 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow4D: Leveraging 4D Voxel Network for LiDAR Scene Flow Estimation
Paper and Code
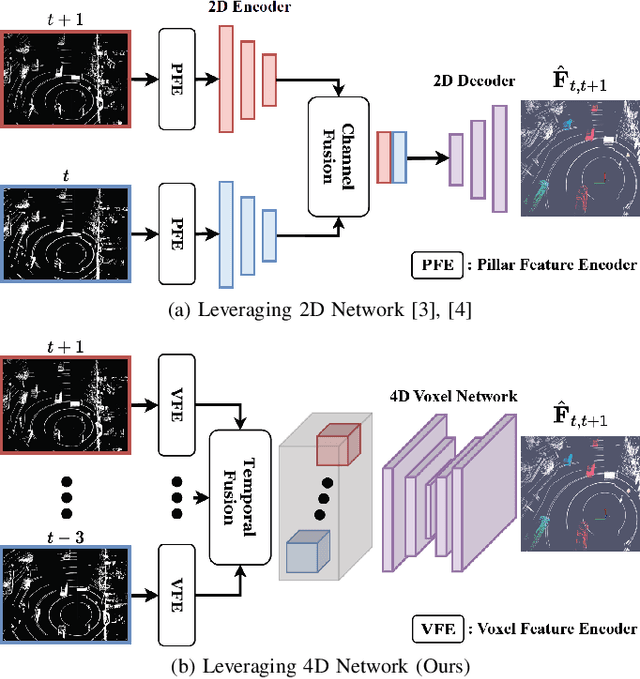
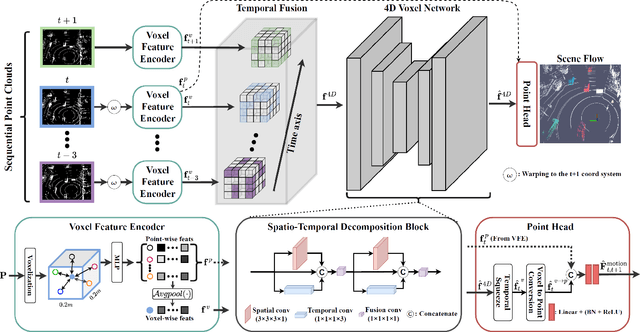
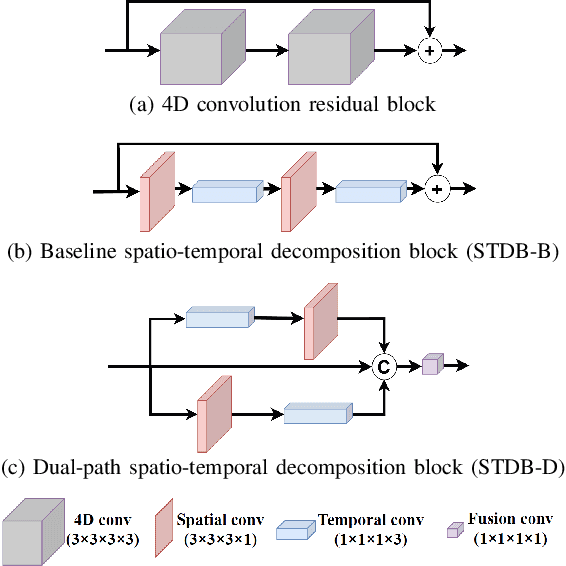
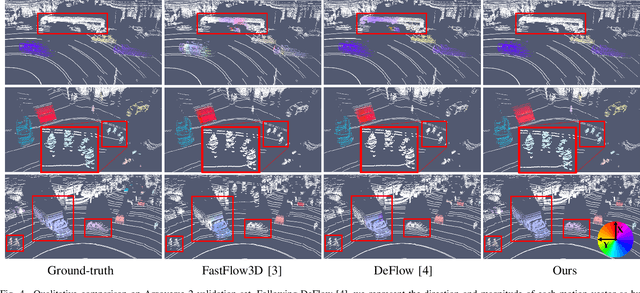
Understanding the motion states of the surrounding environment is critical for safe autonomous driving. These motion states can be accurately derived from scene flow, which captures the three-dimensional motion field of points. Existing LiDAR scene flow methods extract spatial features from each point cloud and then fuse them channel-wise, resulting in the implicit extraction of spatio-temporal features. Furthermore, they utilize 2D Bird's Eye View and process only two frames, missing crucial spatial information along the Z-axis and the broader temporal context, leading to suboptimal performance. To address these limitations, we propose Flow4D, which temporally fuses multiple point clouds after the 3D intra-voxel feature encoder, enabling more explicit extraction of spatio-temporal features through a 4D voxel network. However, while using 4D convolution improves performance, it significantly increases the computational load. For further efficiency, we introduce the Spatio-Temporal Decomposition Block (STDB), which combines 3D and 1D convolutions instead of using heavy 4D convolution. In addition, Flow4D further improves performance by using five frames to take advantage of richer temporal information. As a result, the proposed method achieves a 45.9% higher performance compared to the state-of-the-art while running in real-time, and won 1st place in the 2024 Argoverse 2 Scene Flow Challenge. The code is available at https://github.com/dgist-cvlab/Flow4D.