 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-World Efficient Blind Motion Deblurring via Blur Pixel Discretization
Apr 18, 2024



As recent advances in mobile camera technology have enabled the capability to capture high-resolution images, such as 4K images, the demand for an efficient deblurring model handling large motion has increased. In this paper, we discover that the image residual errors, i.e., blur-sharp pixel differences, can be grouped into some categories according to their motion blur type and how complex their neighboring pixels are. Inspired by this, we decompose the deblurring (regression) task into blur pixel discretization (pixel-level blur classification) and discrete-to-continuous conversion (regression with blur class map) tasks. Specifically, we generate the discretized image residual errors by identifying the blur pixels and then transform them to a continuous form, which is computationally more efficient than naively solving the original regression problem with continuous values. Here, we found that the discretization result, i.e., blur segmentation map, remarkably exhibits visual similarity with the image residual errors. As a result, our efficient model shows comparable performance to state-of-the-art methods in realistic benchmarks, while our method is up to 10 times computationally more efficient.
KL-Divergence-Based Region Proposal Network for Object Detection
May 22, 2020

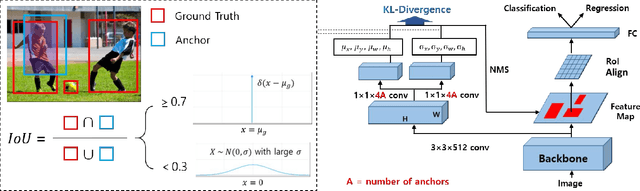

The learning of the region proposal in object detection using the deep neural networks (DNN) is divided into two tasks: binary classification and bounding box regression task. However, traditional RPN (Region Proposal Network) defines these two tasks as different problems, and they are trained independently. In this paper, we propose a new region proposal learning method that considers the bounding box offset's uncertainty in the objectness score. Our method redefines RPN to a problem of minimizing the KL-divergence, difference between the two probability distributions. We applied KL-RPN, which performs region proposal using KL-Divergence, to the existing two-stage object detection framework and showed that it can improve the performance of the existing method. Experiments show that it achieves 2.6% and 2.0% AP improvements on MS COCO test-dev in Faster R-CNN with VGG-16 and R-FCN with ResNet-101 backbone, respectively.
Mixture-Model-based Bounding Box Density Estimation for Object Detection
Nov 28, 2019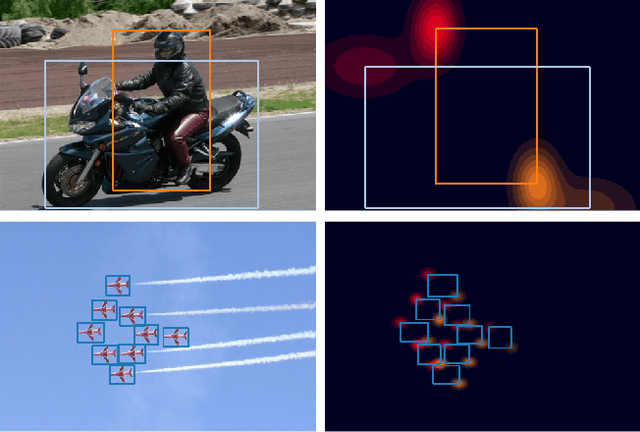
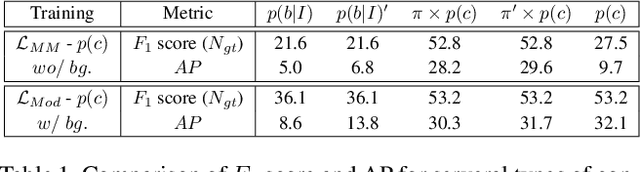
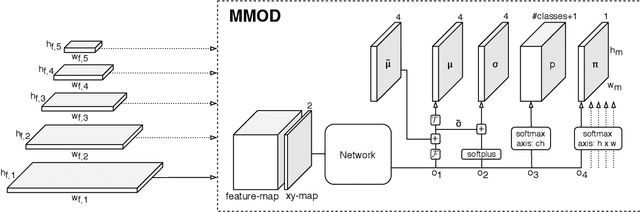
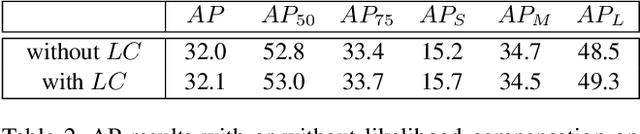
In this paper, we propose a new object detection model, Mixture-Model-based Object Detector (MMOD), that performs multi-object detection using a mixture model. Unlike previous studies, we use density estimation to deal with the multi-object detection task. MMOD captures the conditional distribution of bounding boxes for a given input image using a mixture model consisting of Gaussian and categorical distributions. For this purpose, we propose a method to extract object bounding boxes from a trained mixture model. In doing so, we also propose a new network structure and objective function for the MMOD. Our proposed method is not trained by assigning a ground truth bounding box to a specific location on the network's output. Instead, the mixture components are automatically learned to represent the distribution of the bounding box through density estimation. Therefore, MMOD does not require a large number of anchors and does not incur the positive-negative imbalance problem. This not only benefits the detection performance but also enhances the inference speed without requiring additional processing. We applied MMOD to Pascal VOC and MS COCO datasets, and outperform the detection performance with inference speed of other state-of-the-art fast object detection methods. (38.7 AP with 39ms per image on MS COCO without bells and whistles.) Code will be available.
Concentrated-Comprehensive Convolutions for lightweight semantic segmentation
Dec 24, 2018
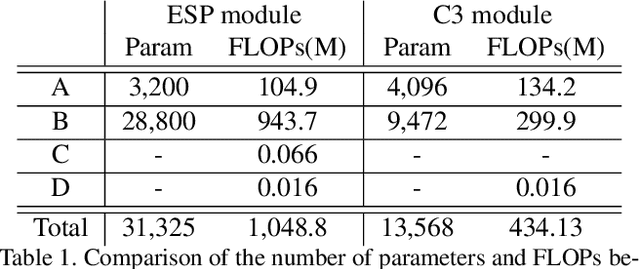
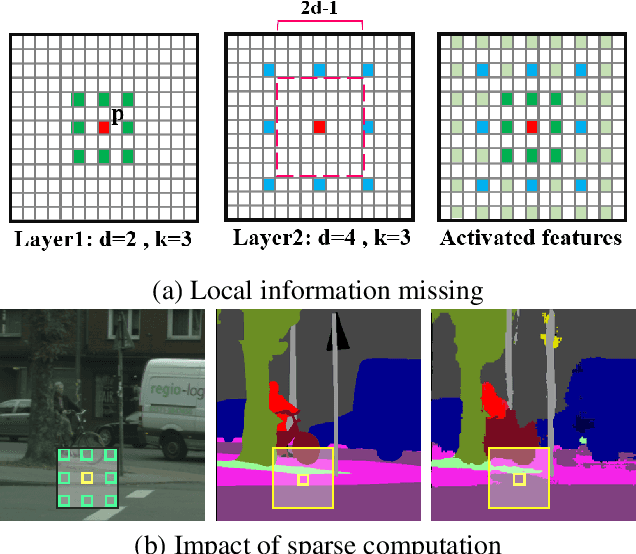

The semantic segmentation requires a lot of computational cost. The dilated convolution relieves this burden of complexity by increasing the receptive field without additional parameters. For a more lightweight model, using depth-wise separable convolution is one of the practical choices. However, a simple combination of these two methods results in too sparse an operation which might cause severe performance degradation. To resolve this problem, we propose a new block of Concentrated-Comprehensive Convolution (CCC) which takes both advantages of the dilated convolution and the depth-wise separable convolution. The CCC block consists of an information concentration stage and a comprehensive convolution stage. The first stage uses two depth-wise asymmetric convolutions for compressed information from the neighboring pixels. The second stage increases the receptive field by using a depth-wise separable dilated convolution from the feature map of the first stage. By replacing the conventional ESP module with the proposed CCC module, without accuracy degradation in Cityscapes dataset, we could reduce the number of parameters by half and the number of flops by 35% compared to the ESPnet which is one of the fastest models. We further applied the CCC to other segmentation models based on dilated convolution and our method achieved comparable or higher performance with a decreased number of parameters and flops. Finally, experiments on ImageNet classification task show that CCC can successfully replace dilated convolutions.