 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcentrated-Comprehensive Convolutions for lightweight semantic segmentation
Paper and Code

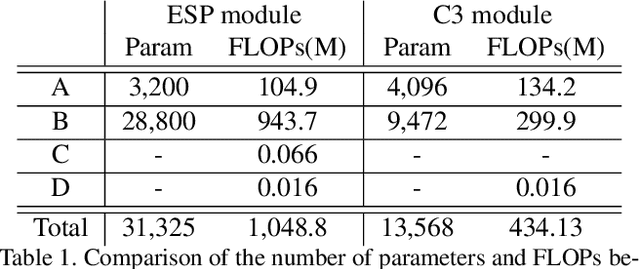
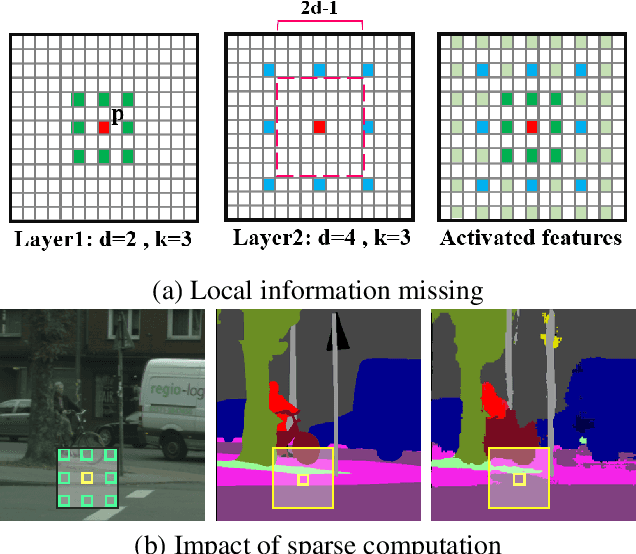

The semantic segmentation requires a lot of computational cost. The dilated convolution relieves this burden of complexity by increasing the receptive field without additional parameters. For a more lightweight model, using depth-wise separable convolution is one of the practical choices. However, a simple combination of these two methods results in too sparse an operation which might cause severe performance degradation. To resolve this problem, we propose a new block of Concentrated-Comprehensive Convolution (CCC) which takes both advantages of the dilated convolution and the depth-wise separable convolution. The CCC block consists of an information concentration stage and a comprehensive convolution stage. The first stage uses two depth-wise asymmetric convolutions for compressed information from the neighboring pixels. The second stage increases the receptive field by using a depth-wise separable dilated convolution from the feature map of the first stage. By replacing the conventional ESP module with the proposed CCC module, without accuracy degradation in Cityscapes dataset, we could reduce the number of parameters by half and the number of flops by 35% compared to the ESPnet which is one of the fastest models. We further applied the CCC to other segmentation models based on dilated convolution and our method achieved comparable or higher performance with a decreased number of parameters and flops. Finally, experiments on ImageNet classification task show that CCC can successfully replace dilated convolutions.