 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-generalizable Face Anti-Spoofing with Patch-based Multi-tasking and Artifact Pattern Conversion
Apr 10, 2026Face Anti-Spoofing (FAS) algorithms, designed to secure face recognition systems against spoofing, struggle with limited dataset diversity, impairing their ability to handle unseen visual domains and spoofing methods. We introduce the Pattern Conversion Generative Adversarial Network (PCGAN) to enhance domain generalization in FAS. PCGAN effectively disentangles latent vectors for spoof artifacts and facial features, allowing to generate images with diverse artifacts. We further incorporate patch-based and multi-task learning to tackle partial attacks and overfitting issues to facial features. Our extensive experiments validate PCGAN's effectiveness in domain generalization and detecting partial attacks, giving a substantial improvement in facial recognition security.
* The published version is available at DOI: https://doi.org/10.1016/j.patcog.2026.113640
Distributional Uncertainty for Out-of-Distribution Detection
Jul 24, 2025



Estimating uncertainty from deep neural networks is a widely used approach for detecting out-of-distribution (OoD) samples, which typically exhibit high predictive uncertainty. However, conventional methods such as Monte Carlo (MC) Dropout often focus solely on either model or data uncertainty, failing to align with the semantic objective of OoD detection. To address this, we propose the Free-Energy Posterior Network, a novel framework that jointly models distributional uncertainty and identifying OoD and misclassified regions using free energy. Our method introduces two key contributions: (1) a free-energy-based density estimator parameterized by a Beta distribution, which enables fine-grained uncertainty estimation near ambiguous or unseen regions; and (2) a loss integrated within a posterior network, allowing direct uncertainty estimation from learned parameters without requiring stochastic sampling. By integrating our approach with the residual prediction branch (RPL) framework, the proposed method goes beyond post-hoc energy thresholding and enables the network to learn OoD regions by leveraging the variance of the Beta distribution, resulting in a semantically meaningful and computationally efficient solution for uncertainty-aware segmentation. We validate the effectiveness of our method on challenging real-world benchmarks, including Fishyscapes, RoadAnomaly, and Segment-Me-If-You-Can.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Compose and Conquer: Diffusion-Based 3D Depth Aware Composable Image Synthesis
Jan 17, 2024Addressing the limitations of text as a source of accurate layout representation in text-conditional diffusion models, many works incorporate additional signals to condition certain attributes within a generated image. Although successful, previous works do not account for the specific localization of said attributes extended into the three dimensional plane. In this context, we present a conditional diffusion model that integrates control over three-dimensional object placement with disentangled representations of global stylistic semantics from multiple exemplar images. Specifically, we first introduce \textit{depth disentanglement training} to leverage the relative depth of objects as an estimator, allowing the model to identify the absolute positions of unseen objects through the use of synthetic image triplets. We also introduce \textit{soft guidance}, a method for imposing global semantics onto targeted regions without the use of any additional localization cues. Our integrated framework, \textsc{Compose and Conquer (CnC)}, unifies these techniques to localize multiple conditions in a disentangled manner. We demonstrate that our approach allows perception of objects at varying depths while offering a versatile framework for composing localized objects with different global semantics. Code: https://github.com/tomtom1103/compose-and-conquer/
Rediscovery of the Effectiveness of Standard Convolution for Lightweight Face Detection
Apr 04, 2022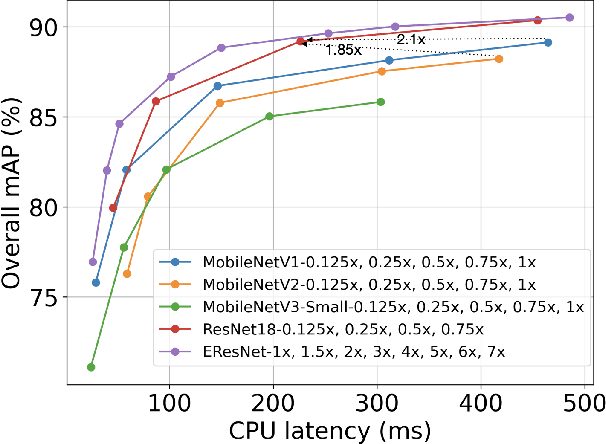
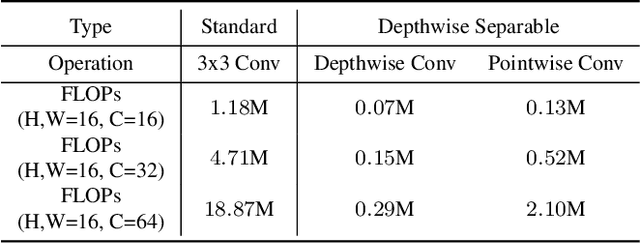
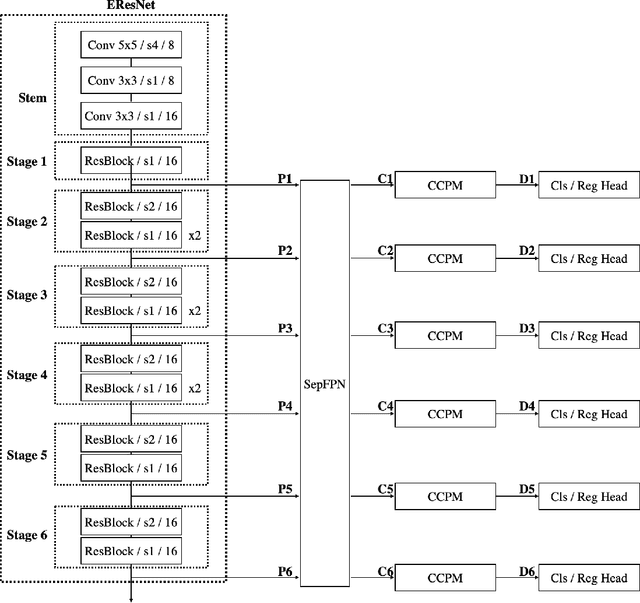
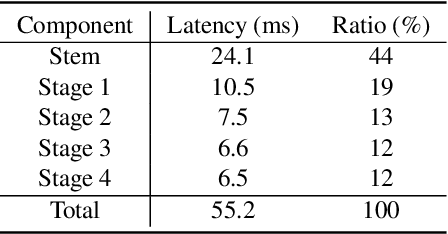
This paper analyses the design choices of face detection architecture that improve efficiency between computation cost and accuracy. Specifically, we re-examine the effectiveness of the standard convolutional block as a lightweight backbone architecture on face detection. Unlike the current tendency of lightweight architecture design, which heavily utilizes depthwise separable convolution layers, we show that heavily channel-pruned standard convolution layer can achieve better accuracy and inference speed when using a similar parameter size. This observation is supported by the analyses concerning the characteristics of the target data domain, face. Based on our observation, we propose to employ ResNet with a highly reduced channel, which surprisingly allows high efficiency compared to other mobile-friendly networks (e.g., MobileNet-V1,-V2,-V3). From the extensive experiments, we show that the proposed backbone can replace that of the state-of-the-art face detector with a faster inference speed. Also, we further propose a new feature aggregation method maximizing the detection performance. Our proposed detector EResFD obtained 80.4% mAP on WIDER FACE Hard subset which only takes 37.7 ms for VGA image inference in on CPU. Code will be available at https://github.com/clovaai/EResFD.
Observations on K-image Expansion of Image-Mixing Augmentation for Classification
Oct 08, 2021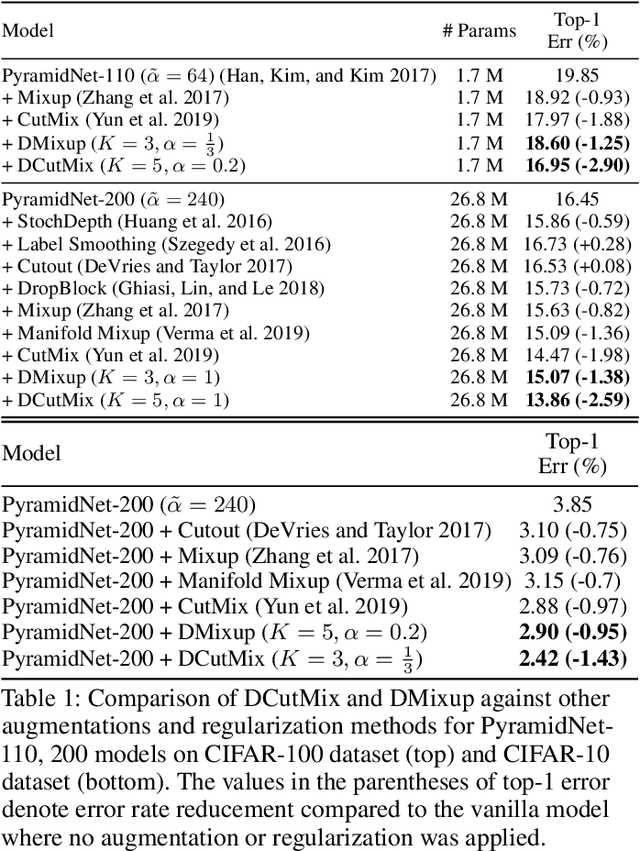
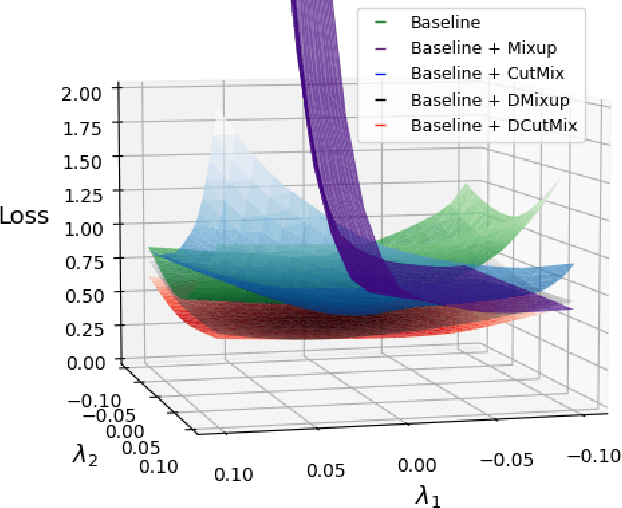

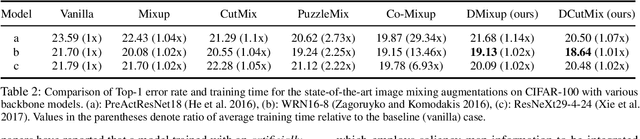
Image-mixing augmentations (e.g., Mixup or CutMix), which typically mix two images, have become de-facto training tricks for image classification. Despite their huge success on image classification, the number of images to mix has not been profoundly investigated by the previous works, only showing the naive K-image expansion leads to poor performance degradation. This paper derives a new K-image mixing augmentation based on the stick-breaking process under Dirichlet prior. We show that our method can train more robust and generalized classifiers through extensive experiments and analysis on classification accuracy, a shape of a loss landscape and adversarial robustness, than the usual two-image methods. Furthermore, we show that our probabilistic model can measure the sample-wise uncertainty and can boost the efficiency for Network Architecture Search (NAS) with 7x reduced search time.
Beyond Semantic to Instance Segmentation: Weakly-Supervised Instance Segmentation via Semantic Knowledge Transfer and Self-Refinement
Sep 20, 2021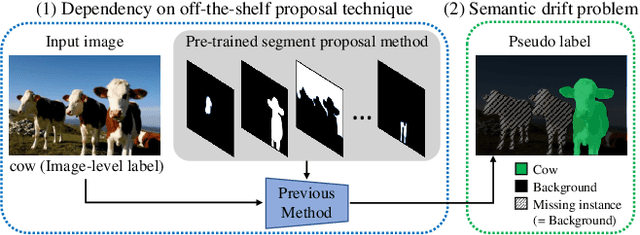
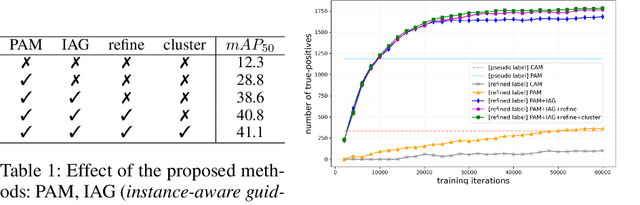
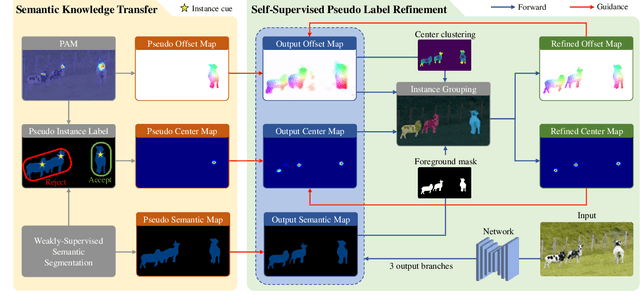
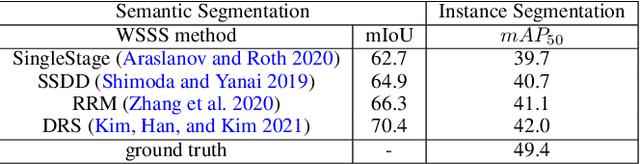
Recent weakly-supervised semantic segmentation (WSSS) has made remarkable progress due to class-wise localization techniques using image-level labels. Meanwhile, weakly-supervised instance segmentation (WSIS) is a more challenging task because instance-wise localization using only image-level labels is quite difficult. Consequently, most WSIS approaches exploit off-the-shelf proposal technique that requires pre-training with high-level labels, deviating a fully image-level supervised setting. Moreover, we focus on semantic drift problem, $i.e.,$ missing instances in pseudo instance labels are categorized as background class, occurring confusion between background and instance in training. To this end, we propose a novel approach that consists of two innovative components. First, we design a semantic knowledge transfer to obtain pseudo instance labels by transferring the knowledge of WSSS to WSIS while eliminating the need for off-the-shelf proposals. Second, we propose a self-refinement method that refines the pseudo instance labels in a self-supervised scheme and employs them to the training in an online manner while resolving the semantic drift problem. The extensive experiments demonstrate the effectiveness of our approach, and we outperform existing works on PASCAL VOC2012 without any off-the-shelf proposal techniques. Furthermore, our approach can be easily applied to the point-supervised setting, boosting the performance with an economical annotation cost. The code will be available soon.
SSUL: Semantic Segmentation with Unknown Label for Exemplar-based Class-Incremental Learning
Jul 01, 2021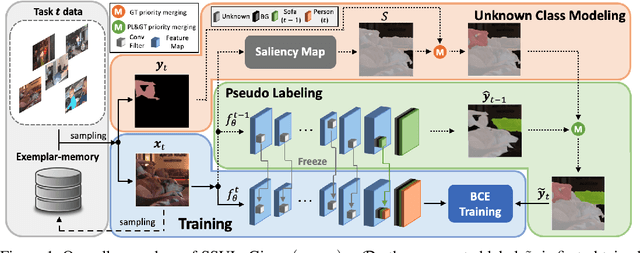


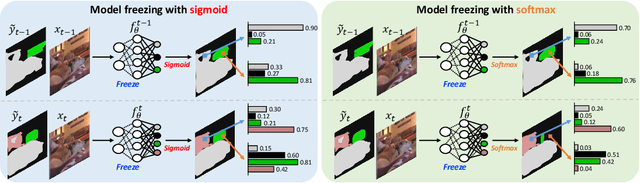
We consider a class-incremental semantic segmentation (CISS) problem. While some recently proposed algorithms utilized variants of knowledge distillation (KD) technique to tackle the problem, they only partially addressed the key additional challenges in CISS that causes the catastrophic forgetting; i.e., the semantic drift of the background class and multi-label prediction issue. To better address these challenges, we propose a new method, dubbed as SSUL-M (Semantic Segmentation with Unknown Label with Memory), by carefully combining several techniques tailored for semantic segmentation. More specifically, we make three main contributions; (1) modeling unknown class within the background class to help learning future classes (help plasticity), (2) freezing backbone network and past classifiers with binary cross-entropy loss and pseudo-labeling to overcome catastrophic forgetting (help stability), and (3) utilizing tiny exemplar memory for the first time in CISS to improve both plasticity and stability. As a result, we show our method achieves significantly better performance than the recent state-of-the-art baselines on the standard benchmark datasets. Furthermore, we justify our contributions with thorough and extensive ablation analyses and discuss different natures of the CISS problem compared to the standard class-incremental learning for classification.
Self-Supervised Iterative Contextual Smoothing for Efficient Adversarial Defense against Gray- and Black-Box Attack
Jun 22, 2021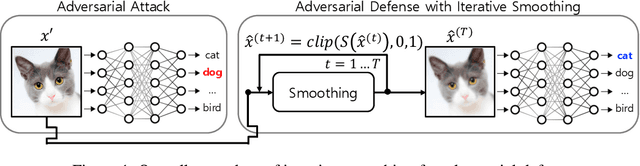
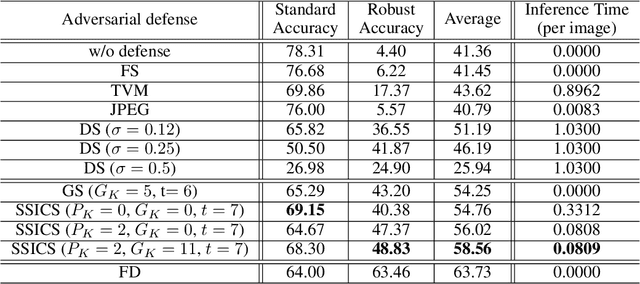
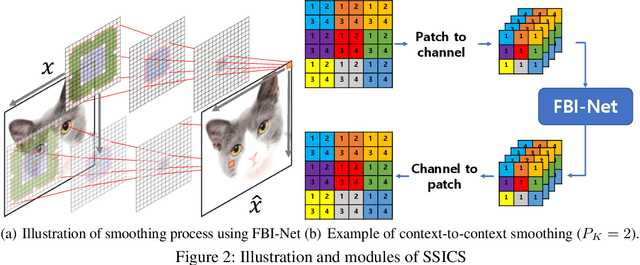
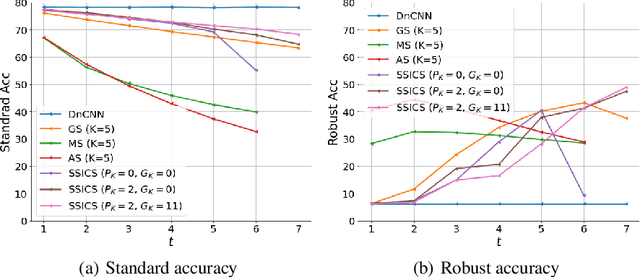
We propose a novel and effective input transformation based adversarial defense method against gray- and black-box attack, which is computationally efficient and does not require any adversarial training or retraining of a classification model. We first show that a very simple iterative Gaussian smoothing can effectively wash out adversarial noise and achieve substantially high robust accuracy. Based on the observation, we propose Self-Supervised Iterative Contextual Smoothing (SSICS), which aims to reconstruct the original discriminative features from the Gaussian-smoothed image in context-adaptive manner, while still smoothing out the adversarial noise. From the experiments on ImageNet, we show that our SSICS achieves both high standard accuracy and very competitive robust accuracy for the gray- and black-box attacks; e.g., transfer-based PGD-attack and score-based attack. A note-worthy point to stress is that our defense is free of computationally expensive adversarial training, yet, can approach its robust accuracy via input transformation.
More than just an auxiliary loss: Anti-spoofing Backbone Training via Adversarial Pseudo-depth Generation
Jan 01, 2021



In this paper, a new method of training pipeline is discussed to achieve significant performance on the task of anti-spoofing with RGB image. We explore and highlight the impact of using pseudo-depth to pre-train a network that will be used as the backbone to the final classifier. While the usage of pseudo-depth for anti-spoofing task is not a new idea on its own, previous endeavours utilize pseudo-depth simply as another medium to extract features for performing prediction, or as part of many auxiliary losses in aiding the training of the main classifier, normalizing the importance of pseudo-depth as just another semantic information. Through this work, we argue that there exists a significant advantage in training the final classifier can be gained by the pre-trained generator learning to predict the corresponding pseudo-depth of a given facial image, from a Generative Adversarial Network framework. Our experimental results indicate that our method results in a much more adaptable system that can generalize beyond intra-dataset samples, but to inter-dataset samples, which it has never seen before during training. Quantitatively, our method approaches the baseline performance of the current state of the art anti-spoofing models with 15.8x less parameters used. Moreover, experiments showed that the introduced methodology performs well only using basic binary label without additional semantic information which indicates potential benefits of this work in industrial and application based environment where trade-off between additional labelling and resources are considered.