 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Self-Supervised Iterative Contextual Smoothing for Efficient Adversarial Defense against Gray- and Black-Box Attack
Jun 22, 2021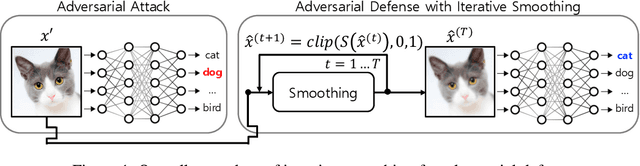
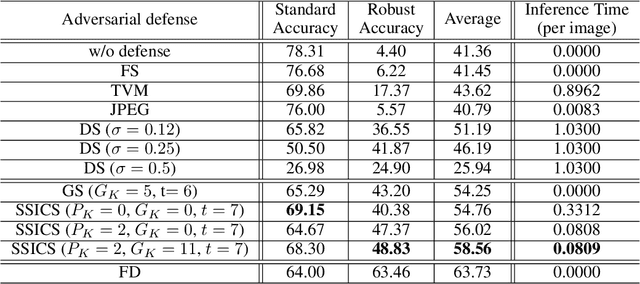
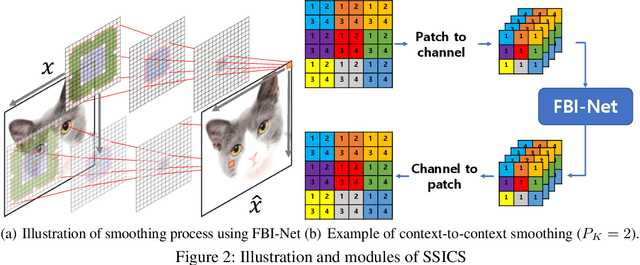
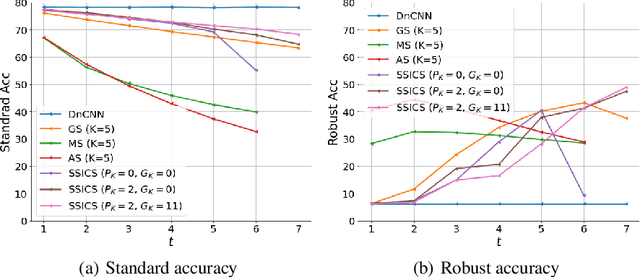
We propose a novel and effective input transformation based adversarial defense method against gray- and black-box attack, which is computationally efficient and does not require any adversarial training or retraining of a classification model. We first show that a very simple iterative Gaussian smoothing can effectively wash out adversarial noise and achieve substantially high robust accuracy. Based on the observation, we propose Self-Supervised Iterative Contextual Smoothing (SSICS), which aims to reconstruct the original discriminative features from the Gaussian-smoothed image in context-adaptive manner, while still smoothing out the adversarial noise. From the experiments on ImageNet, we show that our SSICS achieves both high standard accuracy and very competitive robust accuracy for the gray- and black-box attacks; e.g., transfer-based PGD-attack and score-based attack. A note-worthy point to stress is that our defense is free of computationally expensive adversarial training, yet, can approach its robust accuracy via input transformation.
More than just an auxiliary loss: Anti-spoofing Backbone Training via Adversarial Pseudo-depth Generation
Jan 01, 2021



In this paper, a new method of training pipeline is discussed to achieve significant performance on the task of anti-spoofing with RGB image. We explore and highlight the impact of using pseudo-depth to pre-train a network that will be used as the backbone to the final classifier. While the usage of pseudo-depth for anti-spoofing task is not a new idea on its own, previous endeavours utilize pseudo-depth simply as another medium to extract features for performing prediction, or as part of many auxiliary losses in aiding the training of the main classifier, normalizing the importance of pseudo-depth as just another semantic information. Through this work, we argue that there exists a significant advantage in training the final classifier can be gained by the pre-trained generator learning to predict the corresponding pseudo-depth of a given facial image, from a Generative Adversarial Network framework. Our experimental results indicate that our method results in a much more adaptable system that can generalize beyond intra-dataset samples, but to inter-dataset samples, which it has never seen before during training. Quantitatively, our method approaches the baseline performance of the current state of the art anti-spoofing models with 15.8x less parameters used. Moreover, experiments showed that the introduced methodology performs well only using basic binary label without additional semantic information which indicates potential benefits of this work in industrial and application based environment where trade-off between additional labelling and resources are considered.