 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Guided Attribute Aware Pretraining for Generalizable Image Quality Assessment
Jun 03, 2024In no-reference image quality assessment (NR-IQA), the challenge of limited dataset sizes hampers the development of robust and generalizable models. Conventional methods address this issue by utilizing large datasets to extract rich representations for IQA. Also, some approaches propose vision language models (VLM) based IQA, but the domain gap between generic VLM and IQA constrains their scalability. In this work, we propose a novel pretraining framework that constructs a generalizable representation for IQA by selectively extracting quality-related knowledge from VLM and leveraging the scalability of large datasets. Specifically, we carefully select optimal text prompts for five representative image quality attributes and use VLM to generate pseudo-labels. Numerous attribute-aware pseudo-labels can be generated with large image datasets, allowing our IQA model to learn rich representations about image quality. Our approach achieves state-of-the-art performance on multiple IQA datasets and exhibits remarkable generalization capabilities. Leveraging these strengths, we propose several applications, such as evaluating image generation models and training image enhancement models, demonstrating our model's real-world applicability. We will make the code available for access.
Real-World Efficient Blind Motion Deblurring via Blur Pixel Discretization
Apr 18, 2024



As recent advances in mobile camera technology have enabled the capability to capture high-resolution images, such as 4K images, the demand for an efficient deblurring model handling large motion has increased. In this paper, we discover that the image residual errors, i.e., blur-sharp pixel differences, can be grouped into some categories according to their motion blur type and how complex their neighboring pixels are. Inspired by this, we decompose the deblurring (regression) task into blur pixel discretization (pixel-level blur classification) and discrete-to-continuous conversion (regression with blur class map) tasks. Specifically, we generate the discretized image residual errors by identifying the blur pixels and then transform them to a continuous form, which is computationally more efficient than naively solving the original regression problem with continuous values. Here, we found that the discretization result, i.e., blur segmentation map, remarkably exhibits visual similarity with the image residual errors. As a result, our efficient model shows comparable performance to state-of-the-art methods in realistic benchmarks, while our method is up to 10 times computationally more efficient.
Information-Theoretic GAN Compression with Variational Energy-based Model
Mar 28, 2023
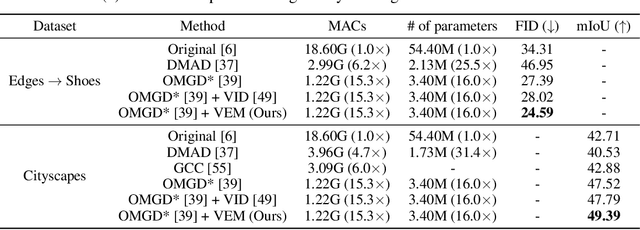

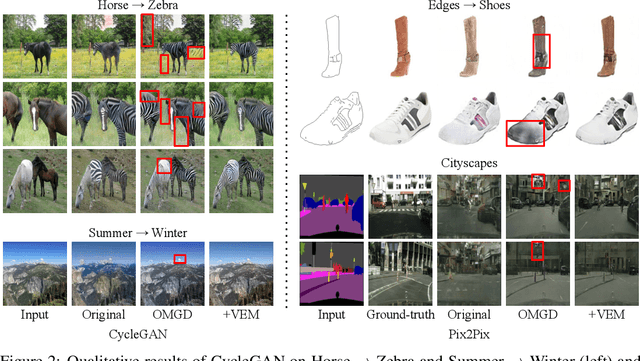
We propose an information-theoretic knowledge distillation approach for the compression of generative adversarial networks, which aims to maximize the mutual information between teacher and student networks via a variational optimization based on an energy-based model. Because the direct computation of the mutual information in continuous domains is intractable, our approach alternatively optimizes the student network by maximizing the variational lower bound of the mutual information. To achieve a tight lower bound, we introduce an energy-based model relying on a deep neural network to represent a flexible variational distribution that deals with high-dimensional images and consider spatial dependencies between pixels, effectively. Since the proposed method is a generic optimization algorithm, it can be conveniently incorporated into arbitrary generative adversarial networks and even dense prediction networks, e.g., image enhancement models. We demonstrate that the proposed algorithm achieves outstanding performance in model compression of generative adversarial networks consistently when combined with several existing models.