 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Text Readability in Vision Language Models
Jun 24, 2025We investigate how the ability to recognize textual content within images emerges during the training of Vision-Language Models (VLMs). Our analysis reveals a critical phenomenon: the ability to read textual information in a given image \textbf{(text readability)} emerges abruptly after substantial training iterations, in contrast to semantic content understanding which develops gradually from the early stages of training. This delayed emergence may reflect how contrastive learning tends to initially prioritize general semantic understanding, with text-specific symbolic processing developing later. Interestingly, the ability to match images with rendered text develops even slower, indicating a deeper need for semantic integration. These findings highlight the need for tailored training strategies to accelerate robust text comprehension in VLMs, laying the groundwork for future research on optimizing multimodal learning.
Extract Free Dense Misalignment from CLIP
Dec 24, 2024

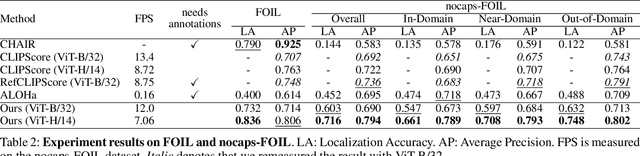

Recent vision-language foundation models still frequently produce outputs misaligned with their inputs, evidenced by object hallucination in captioning and prompt misalignment in the text-to-image generation model. Recent studies have explored methods for identifying misaligned elements, aiming not only to enhance interpretability but also to improve model performance. However, current approaches primarily rely on large foundation models in a zero-shot manner or fine-tuned models with human annotations, which limits scalability due to significant computational costs. This work proposes a novel approach, dubbed CLIP4DM, for detecting dense misalignments from pre-trained CLIP, specifically focusing on pinpointing misaligned words between image and text. We carefully revamp the gradient-based attribution computation method, enabling negative gradient of individual text tokens to indicate misalignment. We also propose F-CLIPScore, which aggregates misaligned attributions with a global alignment score. We evaluate our method on various dense misalignment detection benchmarks, covering various image and text domains and misalignment types. Our method demonstrates state-of-the-art performance among zero-shot models and competitive performance with fine-tuned models while maintaining superior efficiency. Our qualitative examples show that our method has a unique strength to detect entity-level objects, intangible objects, and attributes that can not be easily detected for existing works. We conduct ablation studies and analyses to highlight the strengths and limitations of our approach. Our code is publicly available at https://github.com/naver-ai/CLIP4DM.
Probabilistic Language-Image Pre-Training
Oct 24, 2024

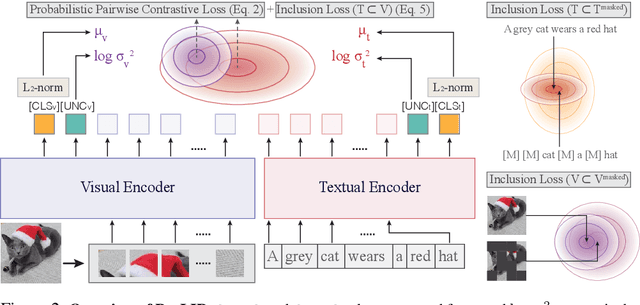

Vision-language models (VLMs) embed aligned image-text pairs into a joint space but often rely on deterministic embeddings, assuming a one-to-one correspondence between images and texts. This oversimplifies real-world relationships, which are inherently many-to-many, with multiple captions describing a single image and vice versa. We introduce Probabilistic Language-Image Pre-training (ProLIP), the first probabilistic VLM pre-trained on a billion-scale image-text dataset using only probabilistic objectives, achieving a strong zero-shot capability (e.g., 74.6% ImageNet zero-shot accuracy with ViT-B/16). ProLIP efficiently estimates uncertainty by an "uncertainty token" without extra parameters. We also introduce a novel inclusion loss that enforces distributional inclusion relationships between image-text pairs and between original and masked inputs. Experiments demonstrate that, by leveraging uncertainty estimates, ProLIP benefits downstream tasks and aligns with intuitive notions of uncertainty, e.g., shorter texts being more uncertain and more general inputs including specific ones. Utilizing text uncertainties, we further improve ImageNet accuracy from 74.6% to 75.8% (under a few-shot setting), supporting the practical advantages of our probabilistic approach. The code is available at https://github.com/naver-ai/prolip
Reducing Task Discrepancy of Text Encoders for Zero-Shot Composed Image Retrieval
Jun 13, 2024Composed Image Retrieval (CIR) aims to retrieve a target image based on a reference image and conditioning text, enabling controllable searches. Due to the expensive dataset construction cost for CIR triplets, a zero-shot (ZS) CIR setting has been actively studied to eliminate the need for human-collected triplet datasets. The mainstream of ZS-CIR employs an efficient projection module that projects a CLIP image embedding to the CLIP text token embedding space, while fixing the CLIP encoders. Using the projected image embedding, these methods generate image-text composed features by using the pre-trained text encoder. However, their CLIP image and text encoders suffer from the task discrepancy between the pre-training task (text $\leftrightarrow$ image) and the target CIR task (image + text $\leftrightarrow$ image). Conceptually, we need expensive triplet samples to reduce the discrepancy, but we use cheap text triplets instead and update the text encoder. To that end, we introduce the Reducing Task Discrepancy of text encoders for Composed Image Retrieval (RTD), a plug-and-play training scheme for the text encoder that enhances its capability using a novel target-anchored text contrastive learning. We also propose two additional techniques to improve the proposed learning scheme: a hard negatives-based refined batch sampling strategy and a sophisticated concatenation scheme. Integrating RTD into the state-of-the-art projection-based ZS-CIR methods significantly improves performance across various datasets and backbones, demonstrating its efficiency and generalizability.
HYPE: Hyperbolic Entailment Filtering for Underspecified Images and Texts
Apr 26, 2024In an era where the volume of data drives the effectiveness of self-supervised learning, the specificity and clarity of data semantics play a crucial role in model training. Addressing this, we introduce HYPerbolic Entailment filtering (HYPE), a novel methodology designed to meticulously extract modality-wise meaningful and well-aligned data from extensive, noisy image-text pair datasets. Our approach leverages hyperbolic embeddings and the concept of entailment cones to evaluate and filter out samples with meaningless or underspecified semantics, focusing on enhancing the specificity of each data sample. HYPE not only demonstrates a significant improvement in filtering efficiency but also sets a new state-of-the-art in the DataComp benchmark when combined with existing filtering techniques. This breakthrough showcases the potential of HYPE to refine the data selection process, thereby contributing to the development of more accurate and efficient self-supervised learning models. Additionally, the image specificity $\epsilon_{i}$ can be independently applied to induce an image-only dataset from an image-text or image-only data pool for training image-only self-supervised models and showed superior performance when compared to the dataset induced by CLIP score.
Language-only Efficient Training of Zero-shot Composed Image Retrieval
Dec 04, 2023Composed image retrieval (CIR) task takes a composed query of image and text, aiming to search relative images for both conditions. Conventional CIR approaches need a training dataset composed of triplets of query image, query text, and target image, which is very expensive to collect. Several recent works have worked on the zero-shot (ZS) CIR paradigm to tackle the issue without using pre-collected triplets. However, the existing ZS-CIR methods show limited backbone scalability and generalizability due to the lack of diversity of the input texts during training. We propose a novel CIR framework, only using language for its training. Our LinCIR (Language-only training for CIR) can be trained only with text datasets by a novel self-supervision named self-masking projection (SMP). We project the text latent embedding to the token embedding space and construct a new text by replacing the keyword tokens of the original text. Then, we let the new and original texts have the same latent embedding vector. With this simple strategy, LinCIR is surprisingly efficient and highly effective; LinCIR with CLIP ViT-G backbone is trained in 48 minutes and shows the best ZS-CIR performances on four different CIR benchmarks, CIRCO, GeneCIS, FashionIQ, and CIRR, even outperforming supervised method on FashionIQ. Code is available at https://github.com/navervision/lincir
Lifelong Audio-video Masked Autoencoder with Forget-robust Localized Alignments
Oct 12, 2023We present a lifelong audio-video masked autoencoder that continually learns the multimodal representations from a video stream containing audio-video pairs, while its distribution continually shifts over time. Specifically, we propose two novel ideas to tackle the problem: (1) Localized Alignment: We introduce a small trainable multimodal encoder that predicts the audio and video tokens that are well-aligned with each other. This allows the model to learn only the highly correlated audiovisual patches with accurate multimodal relationships. (2) Forget-robust multimodal patch selection: We compare the relative importance of each audio-video patch between the current and past data pair to mitigate unintended drift of the previously learned audio-video representations. Our proposed method, FLAVA (Forget-robust Localized Audio-Video Alignment), therefore, captures the complex relationships between the audio and video modalities during training on a sequence of pre-training tasks while alleviating the forgetting of learned audiovisual correlations. Our experiments validate that FLAVA outperforms the state-of-the-art continual learning methods on several benchmark datasets under continual audio-video representation learning scenarios.
Computational Approaches for App-to-App Retrieval and Design Consistency Check
Sep 19, 2023



Extracting semantic representations from mobile user interfaces (UI) and using the representations for designers' decision-making processes have shown the potential to be effective computational design support tools. Current approaches rely on machine learning models trained on small-sized mobile UI datasets to extract semantic vectors and use screenshot-to-screenshot comparison to retrieve similar-looking UIs given query screenshots. However, the usability of these methods is limited because they are often not open-sourced and have complex training pipelines for practitioners to follow, and are unable to perform screenshot set-to-set (i.e., app-to-app) retrieval. To this end, we (1) employ visual models trained with large web-scale images and test whether they could extract a UI representation in a zero-shot way and outperform existing specialized models, and (2) use mathematically founded methods to enable app-to-app retrieval and design consistency analysis. Our experiments show that our methods not only improve upon previous retrieval models but also enable multiple new applications.
What Do Self-Supervised Vision Transformers Learn?
May 01, 2023We present a comparative study on how and why contrastive learning (CL) and masked image modeling (MIM) differ in their representations and in their performance of downstream tasks. In particular, we demonstrate that self-supervised Vision Transformers (ViTs) have the following properties: (1) CL trains self-attentions to capture longer-range global patterns than MIM, such as the shape of an object, especially in the later layers of the ViT architecture. This CL property helps ViTs linearly separate images in their representation spaces. However, it also makes the self-attentions collapse into homogeneity for all query tokens and heads. Such homogeneity of self-attention reduces the diversity of representations, worsening scalability and dense prediction performance. (2) CL utilizes the low-frequency signals of the representations, but MIM utilizes high-frequencies. Since low- and high-frequency information respectively represent shapes and textures, CL is more shape-oriented and MIM more texture-oriented. (3) CL plays a crucial role in the later layers, while MIM mainly focuses on the early layers. Upon these analyses, we find that CL and MIM can complement each other and observe that even the simplest harmonization can help leverage the advantages of both methods. The code is available at https://github.com/naver-ai/cl-vs-mim.
CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion
Mar 21, 2023This paper proposes a novel diffusion-based model, CompoDiff, for solving Composed Image Retrieval (CIR) with latent diffusion and presents a newly created dataset of 18 million reference images, conditions, and corresponding target image triplets to train the model. CompoDiff not only achieves a new zero-shot state-of-the-art on a CIR benchmark such as FashionIQ but also enables a more versatile CIR by accepting various conditions, such as negative text and image mask conditions, which are unavailable with existing CIR methods. In addition, the CompoDiff features are on the intact CLIP embedding space so that they can be directly used for all existing models exploiting the CLIP space. The code and dataset used for the training, and the pre-trained weights are available at https://github.com/navervision/CompoDiff