 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-JudgeBias: A Benchmark for Evaluating Compositional Biases in MLLM-as-a-Judge
Apr 21, 2026Multimodal Large Language Models (MLLMs) have been increasingly used as automatic evaluators-a paradigm known as MLLM-as-a-Judge. However, their reliability and vulnerabilities to biases remain underexplored. We find that many MLLM judges fail to reliably integrate key visual or textual cues, yielding unreliable evaluations when evidence is missing or mismatched, and exhibiting instability under semantically irrelevant perturbations. To address this, we systematically define Compositional Bias in MLLM-as-a-Judge systems and introduce MM-JudgeBias, a benchmark for evaluating it. MM-JudgeBias introduces controlled perturbations across Query, Image, and Response, and evaluates model behavior via two complementary metrics: Bias-Deviation (BD) for sensitivity and Bias-Conformity (BC) for stability. Our dataset of over 1,800 curated and refined multimodal samples, drawn from 29 source benchmarks, enables a fine-grained diagnosis of nine bias types across diverse tasks and domains. Experiments on 26 state-of-the-art MLLMs reveal systematic modality neglect and asymmetric evaluation tendencies, underscoring the need for more reliable judges.
MMRefine: Unveiling the Obstacles to Robust Refinement in Multimodal Large Language Models
Jun 05, 2025



This paper introduces MMRefine, a MultiModal Refinement benchmark designed to evaluate the error refinement capabilities of Multimodal Large Language Models (MLLMs). As the emphasis shifts toward enhancing reasoning during inference, MMRefine provides a framework that evaluates MLLMs' abilities to detect and correct errors across six distinct scenarios beyond just comparing final accuracy before and after refinement. Furthermore, the benchmark analyzes the refinement performance by categorizing errors into six error types. Experiments with various open and closed MLLMs reveal bottlenecks and factors impeding refinement performance, highlighting areas for improvement in effective reasoning enhancement. Our code and dataset are publicly available at https://github.com/naver-ai/MMRefine.
Extract Free Dense Misalignment from CLIP
Dec 24, 2024

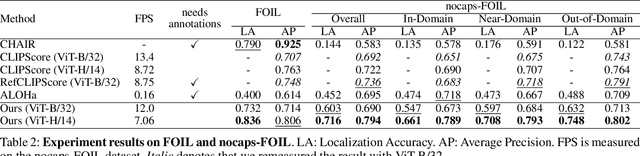

Recent vision-language foundation models still frequently produce outputs misaligned with their inputs, evidenced by object hallucination in captioning and prompt misalignment in the text-to-image generation model. Recent studies have explored methods for identifying misaligned elements, aiming not only to enhance interpretability but also to improve model performance. However, current approaches primarily rely on large foundation models in a zero-shot manner or fine-tuned models with human annotations, which limits scalability due to significant computational costs. This work proposes a novel approach, dubbed CLIP4DM, for detecting dense misalignments from pre-trained CLIP, specifically focusing on pinpointing misaligned words between image and text. We carefully revamp the gradient-based attribution computation method, enabling negative gradient of individual text tokens to indicate misalignment. We also propose F-CLIPScore, which aggregates misaligned attributions with a global alignment score. We evaluate our method on various dense misalignment detection benchmarks, covering various image and text domains and misalignment types. Our method demonstrates state-of-the-art performance among zero-shot models and competitive performance with fine-tuned models while maintaining superior efficiency. Our qualitative examples show that our method has a unique strength to detect entity-level objects, intangible objects, and attributes that can not be easily detected for existing works. We conduct ablation studies and analyses to highlight the strengths and limitations of our approach. Our code is publicly available at https://github.com/naver-ai/CLIP4DM.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
EGTR: Extracting Graph from Transformer for Scene Graph Generation
Apr 05, 2024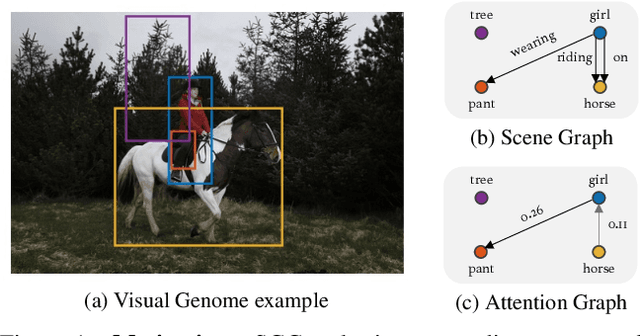



Scene Graph Generation (SGG) is a challenging task of detecting objects and predicting relationships between objects. After DETR was developed, one-stage SGG models based on a one-stage object detector have been actively studied. However, complex modeling is used to predict the relationship between objects, and the inherent relationship between object queries learned in the multi-head self-attention of the object detector has been neglected. We propose a lightweight one-stage SGG model that extracts the relation graph from the various relationships learned in the multi-head self-attention layers of the DETR decoder. By fully utilizing the self-attention by-products, the relation graph can be extracted effectively with a shallow relation extraction head. Considering the dependency of the relation extraction task on the object detection task, we propose a novel relation smoothing technique that adjusts the relation label adaptively according to the quality of the detected objects. By the relation smoothing, the model is trained according to the continuous curriculum that focuses on object detection task at the beginning of training and performs multi-task learning as the object detection performance gradually improves. Furthermore, we propose a connectivity prediction task that predicts whether a relation exists between object pairs as an auxiliary task of the relation extraction. We demonstrate the effectiveness and efficiency of our method for the Visual Genome and Open Image V6 datasets. Our code is publicly available at https://github.com/naver-ai/egtr.
Self-Supervised Multimodal Opinion Summarization
May 27, 2021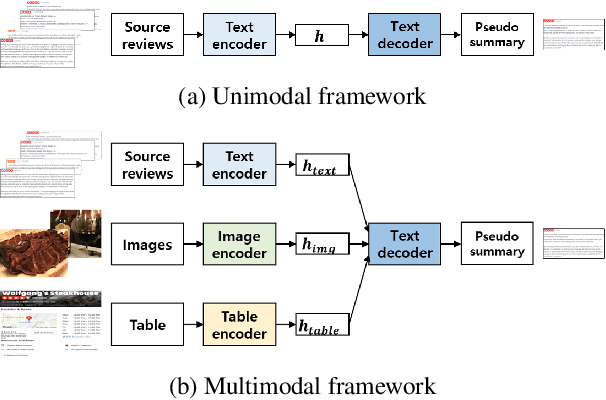
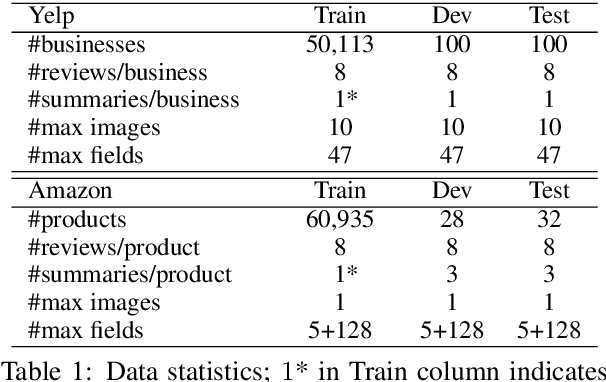
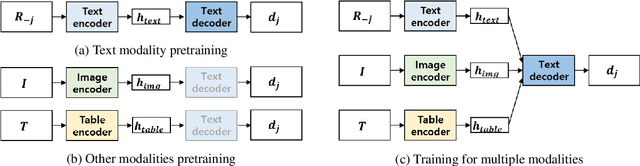
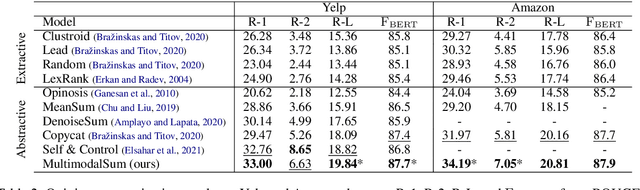
Recently, opinion summarization, which is the generation of a summary from multiple reviews, has been conducted in a self-supervised manner by considering a sampled review as a pseudo summary. However, non-text data such as image and metadata related to reviews have been considered less often. To use the abundant information contained in non-text data, we propose a self-supervised multimodal opinion summarization framework called MultimodalSum. Our framework obtains a representation of each modality using a separate encoder for each modality, and the text decoder generates a summary. To resolve the inherent heterogeneity of multimodal data, we propose a multimodal training pipeline. We first pretrain the text encoder--decoder based solely on text modality data. Subsequently, we pretrain the non-text modality encoders by considering the pretrained text decoder as a pivot for the homogeneous representation of multimodal data. Finally, to fuse multimodal representations, we train the entire framework in an end-to-end manner. We demonstrate the superiority of MultimodalSum by conducting experiments on Yelp and Amazon datasets.
Freudian and Newtonian Recurrent Cell for Sequential Recommendation
Feb 11, 2021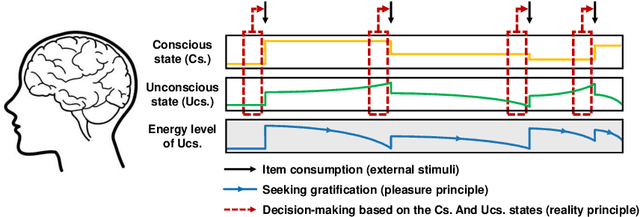
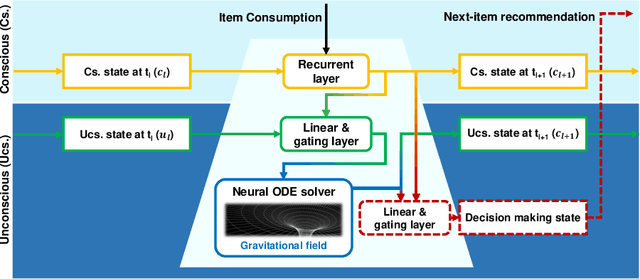
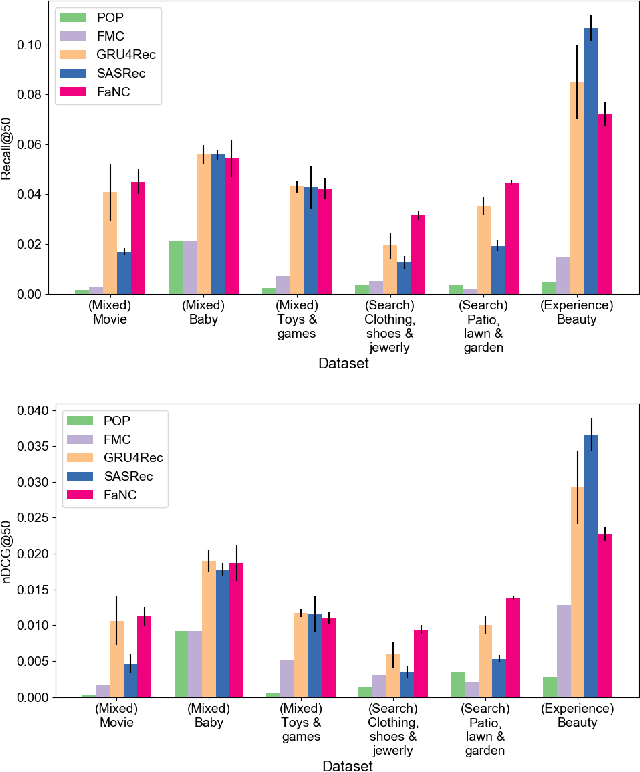
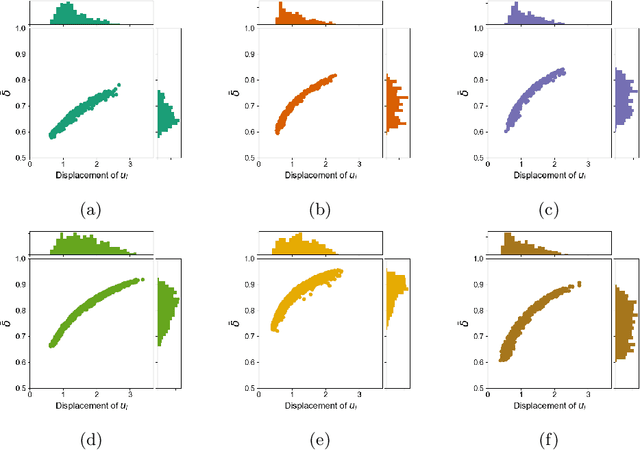
A sequential recommender system aims to recommend attractive items to users based on behaviour patterns. The predominant sequential recommendation models are based on natural language processing models, such as the gated recurrent unit, that embed items in some defined space and grasp the user's long-term and short-term preferences based on the item embeddings. However, these approaches lack fundamental insight into how such models are related to the user's inherent decision-making process. To provide this insight, we propose a novel recurrent cell, namely FaNC, from Freudian and Newtonian perspectives. FaNC divides the user's state into conscious and unconscious states, and the user's decision process is modelled by Freud's two principles: the pleasure principle and reality principle. To model the pleasure principle, i.e., free-floating user's instinct, we place the user's unconscious state and item embeddings in the same latent space and subject them to Newton's law of gravitation. Moreover, to recommend items to users, we model the reality principle, i.e., balancing the conscious and unconscious states, via a gating function. Based on extensive experiments on various benchmark datasets, this paper provides insight into the characteristics of the proposed model. FaNC initiates a new direction of sequential recommendations at the convergence of psychoanalysis and recommender systems.
MeLU: Meta-Learned User Preference Estimator for Cold-Start Recommendation
Jul 31, 2019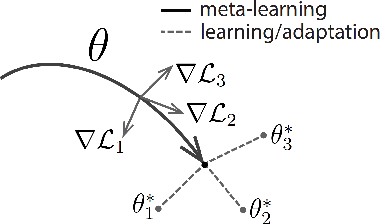
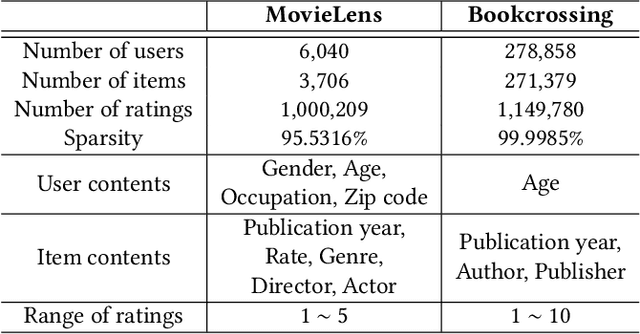
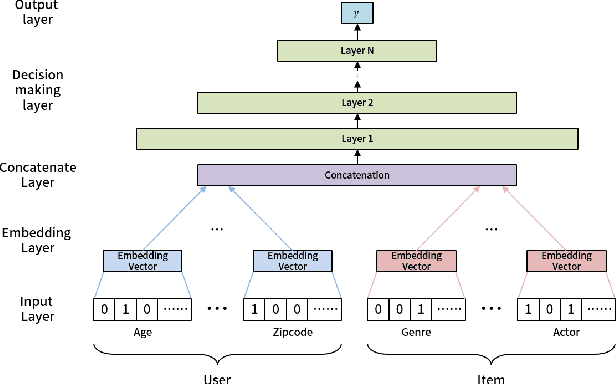
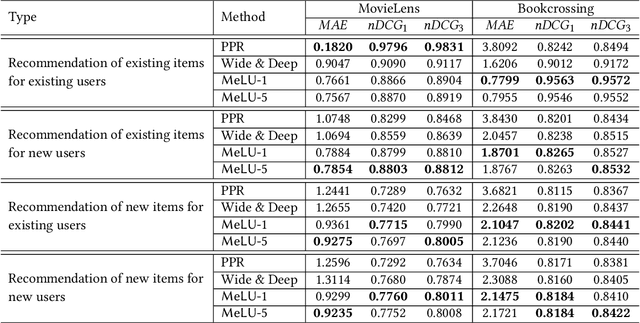
This paper proposes a recommender system to alleviate the cold-start problem that can estimate user preferences based on only a small number of items. To identify a user's preference in the cold state, existing recommender systems, such as Netflix, initially provide items to a user; we call those items evidence candidates. Recommendations are then made based on the items selected by the user. Previous recommendation studies have two limitations: (1) the users who consumed a few items have poor recommendations and (2) inadequate evidence candidates are used to identify user preferences. We propose a meta-learning-based recommender system called MeLU to overcome these two limitations. From meta-learning, which can rapidly adopt new task with a few examples, MeLU can estimate new user's preferences with a few consumed items. In addition, we provide an evidence candidate selection strategy that determines distinguishing items for customized preference estimation. We validate MeLU with two benchmark datasets, and the proposed model reduces at least 5.92% mean absolute error than two comparative models on the datasets. We also conduct a user study experiment to verify the evidence selection strategy.
Distance-based Self-Attention Network for Natural Language Inference
Dec 06, 2017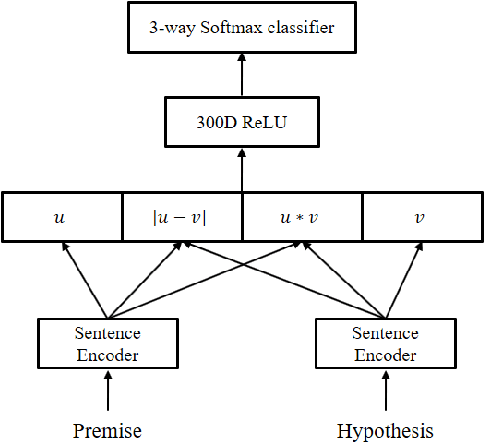

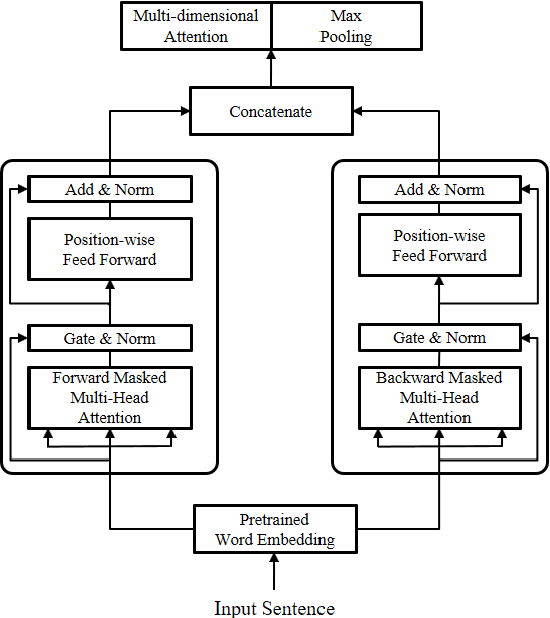

Attention mechanism has been used as an ancillary means to help RNN or CNN. However, the Transformer (Vaswani et al., 2017) recently recorded the state-of-the-art performance in machine translation with a dramatic reduction in training time by solely using attention. Motivated by the Transformer, Directional Self Attention Network (Shen et al., 2017), a fully attention-based sentence encoder, was proposed. It showed good performance with various data by using forward and backward directional information in a sentence. But in their study, not considered at all was the distance between words, an important feature when learning the local dependency to help understand the context of input text. We propose Distance-based Self-Attention Network, which considers the word distance by using a simple distance mask in order to model the local dependency without losing the ability of modeling global dependency which attention has inherent. Our model shows good performance with NLI data, and it records the new state-of-the-art result with SNLI data. Additionally, we show that our model has a strength in long sentences or documents.