 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Proper Contrastive Self-supervised Learning Strategies For Music Audio Representation
Jul 10, 2022

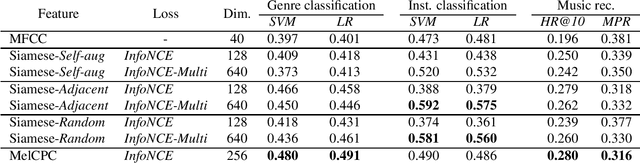
The common research goal of self-supervised learning is to extract a general representation which an arbitrary downstream task would benefit from. In this work, we investigate music audio representation learned from different contrastive self-supervised learning schemes and empirically evaluate the embedded vectors on various music information retrieval (MIR) tasks where different levels of the music perception are concerned. We analyze the results to discuss the proper direction of contrastive learning strategies for different MIR tasks. We show that these representations convey a comprehensive information about the auditory characteristics of music in general, although each of the self-supervision strategies has its own effectiveness in certain aspect of information.
Self-Supervised Multimodal Opinion Summarization
May 27, 2021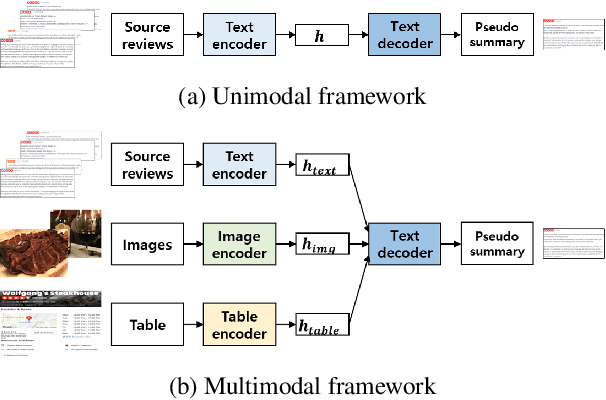
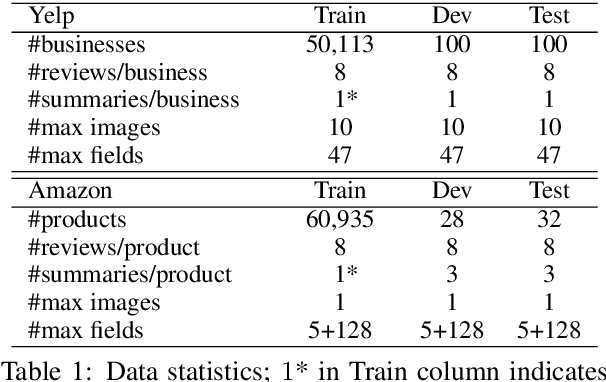
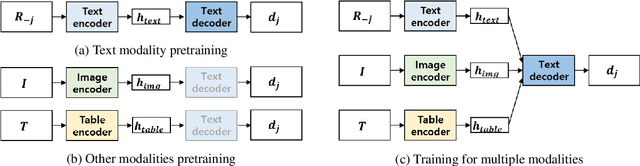
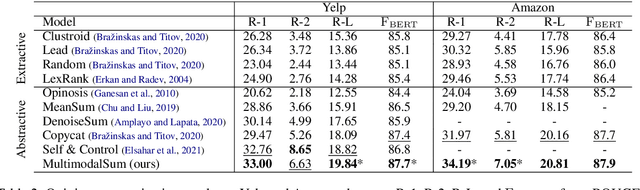
Recently, opinion summarization, which is the generation of a summary from multiple reviews, has been conducted in a self-supervised manner by considering a sampled review as a pseudo summary. However, non-text data such as image and metadata related to reviews have been considered less often. To use the abundant information contained in non-text data, we propose a self-supervised multimodal opinion summarization framework called MultimodalSum. Our framework obtains a representation of each modality using a separate encoder for each modality, and the text decoder generates a summary. To resolve the inherent heterogeneity of multimodal data, we propose a multimodal training pipeline. We first pretrain the text encoder--decoder based solely on text modality data. Subsequently, we pretrain the non-text modality encoders by considering the pretrained text decoder as a pivot for the homogeneous representation of multimodal data. Finally, to fuse multimodal representations, we train the entire framework in an end-to-end manner. We demonstrate the superiority of MultimodalSum by conducting experiments on Yelp and Amazon datasets.
CITIES: Contextual Inference of Tail-Item Embeddings for Sequential Recommendation
May 23, 2021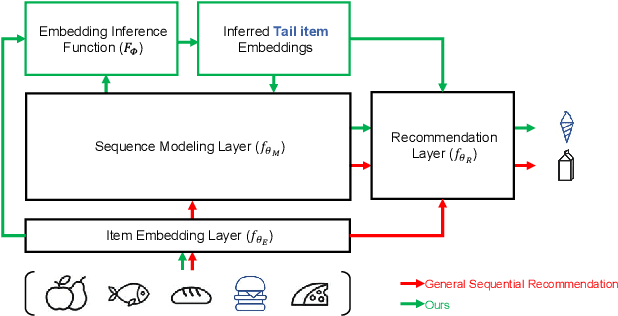
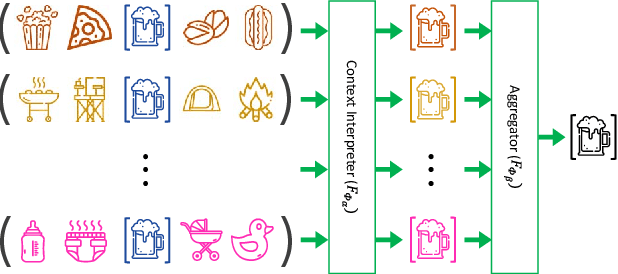
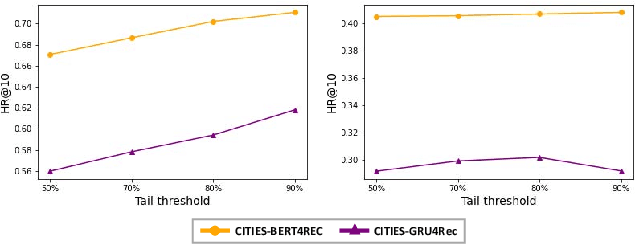
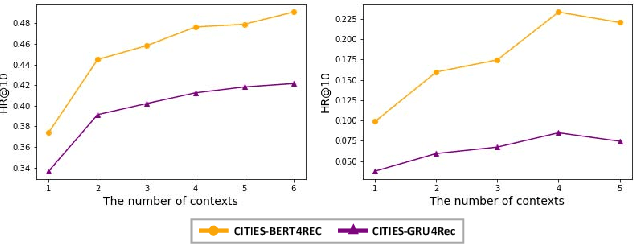
Sequential recommendation techniques provide users with product recommendations fitting their current preferences by handling dynamic user preferences over time. Previous studies have focused on modeling sequential dynamics without much regard to which of the best-selling products (i.e., head items) or niche products (i.e., tail items) should be recommended. We scrutinize the structural reason for why tail items are barely served in the current sequential recommendation model, which consists of an item-embedding layer, a sequence-modeling layer, and a recommendation layer. Well-designed sequence-modeling and recommendation layers are expected to naturally learn suitable item embeddings. However, tail items are likely to fall short of this expectation because the current model structure is not suitable for learning high-quality embeddings with insufficient data. Thus, tail items are rarely recommended. To eliminate this issue, we propose a framework called CITIES, which aims to enhance the quality of the tail-item embeddings by training an embedding-inference function using multiple contextual head items so that the recommendation performance improves for not only the tail items but also for the head items. Moreover, our framework can infer new-item embeddings without an additional learning process. Extensive experiments on two real-world datasets show that applying CITIES to the state-of-the-art methods improves recommendation performance for both tail and head items. We conduct an additional experiment to verify that CITIES can infer suitable new-item embeddings as well.
Freudian and Newtonian Recurrent Cell for Sequential Recommendation
Feb 11, 2021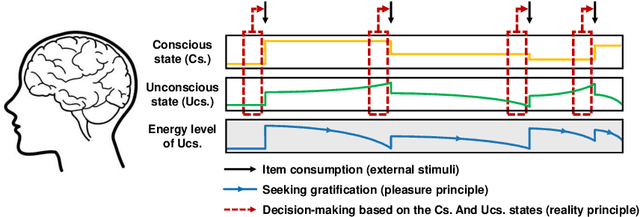
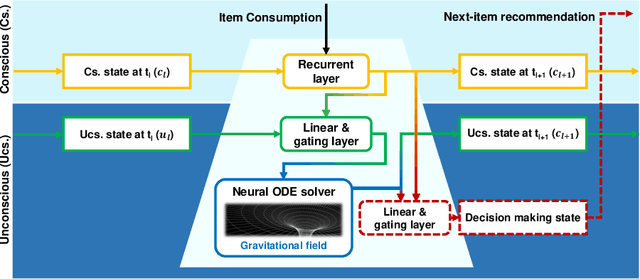
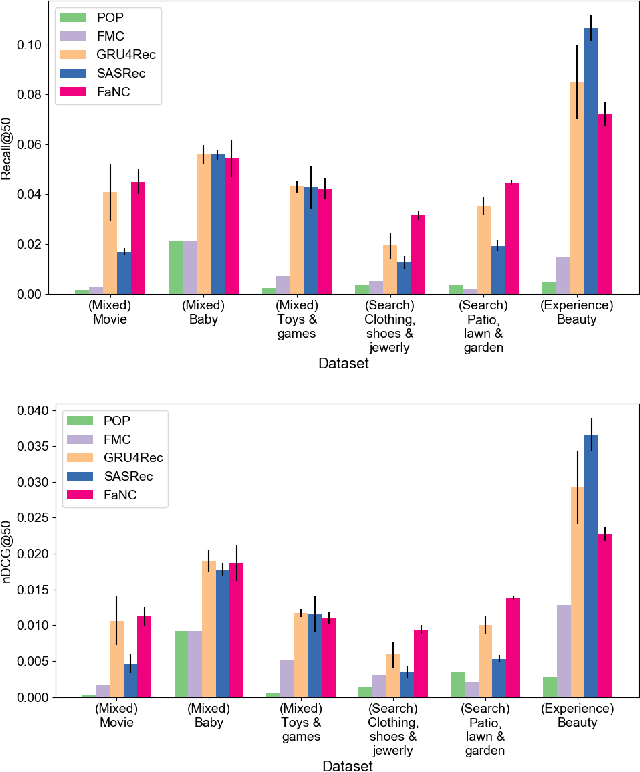
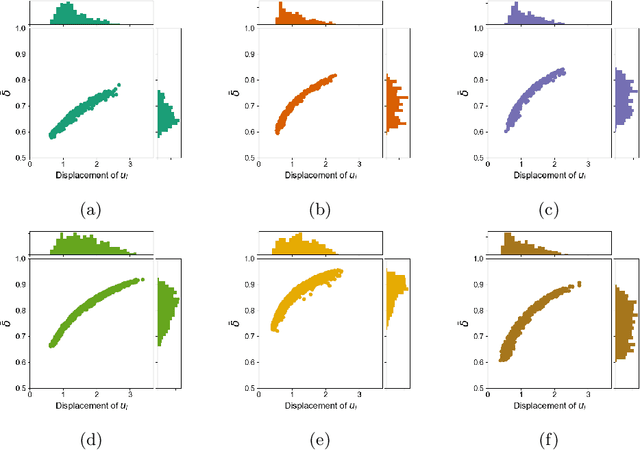
A sequential recommender system aims to recommend attractive items to users based on behaviour patterns. The predominant sequential recommendation models are based on natural language processing models, such as the gated recurrent unit, that embed items in some defined space and grasp the user's long-term and short-term preferences based on the item embeddings. However, these approaches lack fundamental insight into how such models are related to the user's inherent decision-making process. To provide this insight, we propose a novel recurrent cell, namely FaNC, from Freudian and Newtonian perspectives. FaNC divides the user's state into conscious and unconscious states, and the user's decision process is modelled by Freud's two principles: the pleasure principle and reality principle. To model the pleasure principle, i.e., free-floating user's instinct, we place the user's unconscious state and item embeddings in the same latent space and subject them to Newton's law of gravitation. Moreover, to recommend items to users, we model the reality principle, i.e., balancing the conscious and unconscious states, via a gating function. Based on extensive experiments on various benchmark datasets, this paper provides insight into the characteristics of the proposed model. FaNC initiates a new direction of sequential recommendations at the convergence of psychoanalysis and recommender systems.
MeLU: Meta-Learned User Preference Estimator for Cold-Start Recommendation
Jul 31, 2019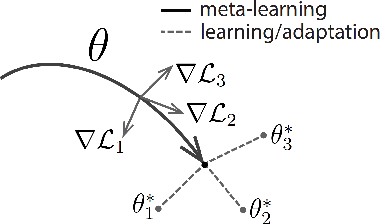
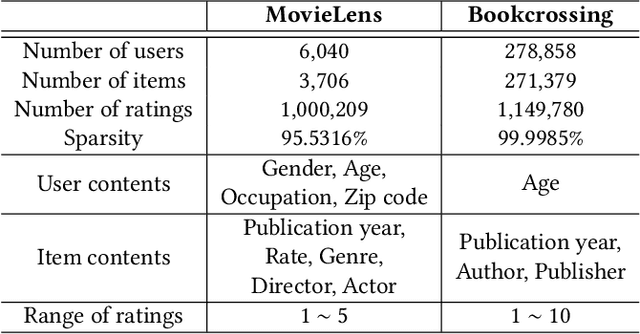
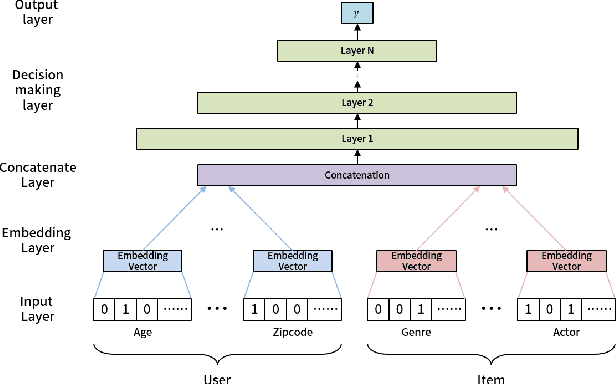
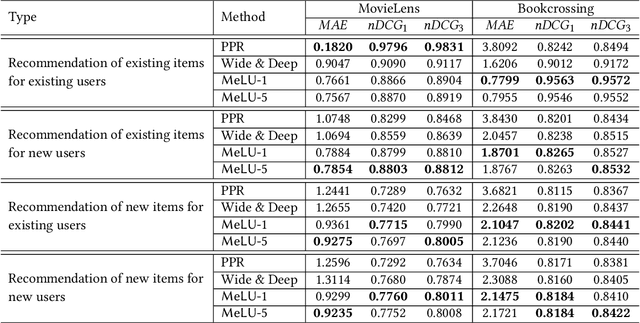
This paper proposes a recommender system to alleviate the cold-start problem that can estimate user preferences based on only a small number of items. To identify a user's preference in the cold state, existing recommender systems, such as Netflix, initially provide items to a user; we call those items evidence candidates. Recommendations are then made based on the items selected by the user. Previous recommendation studies have two limitations: (1) the users who consumed a few items have poor recommendations and (2) inadequate evidence candidates are used to identify user preferences. We propose a meta-learning-based recommender system called MeLU to overcome these two limitations. From meta-learning, which can rapidly adopt new task with a few examples, MeLU can estimate new user's preferences with a few consumed items. In addition, we provide an evidence candidate selection strategy that determines distinguishing items for customized preference estimation. We validate MeLU with two benchmark datasets, and the proposed model reduces at least 5.92% mean absolute error than two comparative models on the datasets. We also conduct a user study experiment to verify the evidence selection strategy.