 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-Explorer-Student Learning: A Novel Learning Method for Open Set Recognition
Mar 23, 2021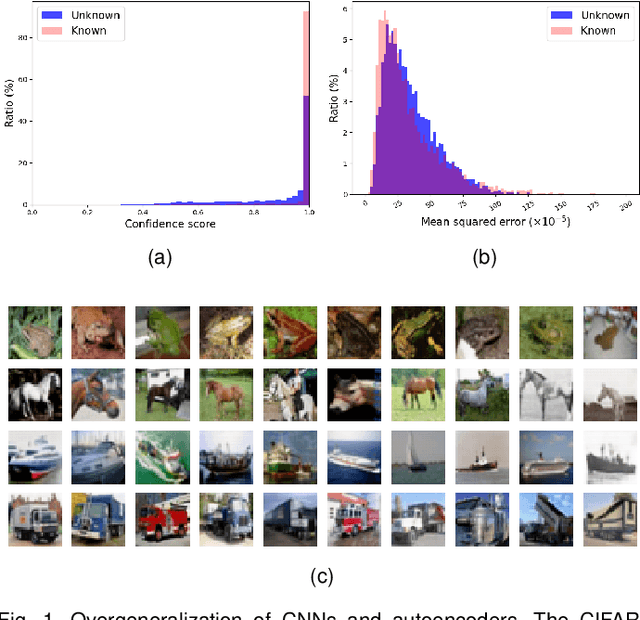
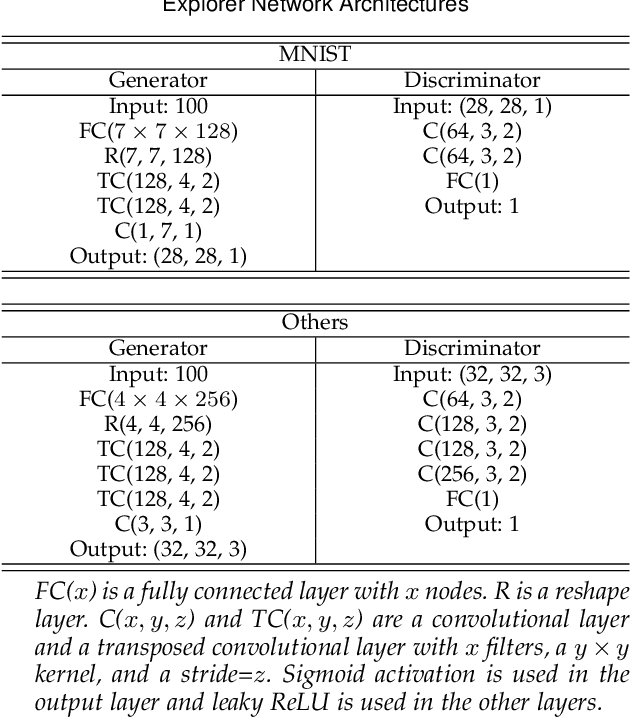
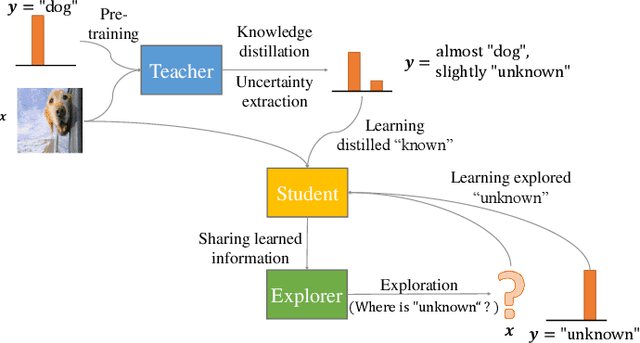
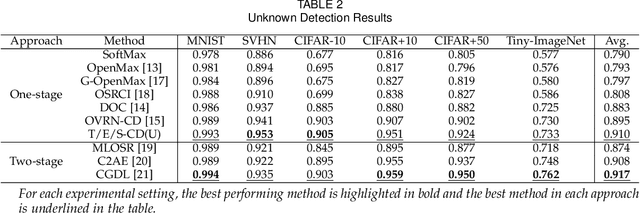
If an unknown example that is not seen during training appears, most recognition systems usually produce overgeneralized results and determine that the example belongs to one of the known classes. To address this problem, teacher-explorer-student (T/E/S) learning, which adopts the concept of open set recognition (OSR) that aims to reject unknown samples while minimizing the loss of classification performance on known samples, is proposed in this study. In this novel learning method, overgeneralization of deep learning classifiers is significantly reduced by exploring various possibilities of unknowns. Here, the teacher network extracts some hints about unknowns by distilling the pretrained knowledge about knowns and delivers this distilled knowledge to the student. After learning the distilled knowledge, the student network shares the learned information with the explorer network. Then, the explorer network shares its exploration results by generating unknown-like samples and feeding the samples to the student network. By repeating this alternating learning process, the student network experiences a variety of synthetic unknowns, reducing overgeneralization. Extensive experiments were conducted, and the experimental results showed that each component proposed in this paper significantly contributes to the improvement in OSR performance. As a result, the proposed T/E/S learning method outperformed current state-of-the-art methods.
Collective Decision of One-vs-Rest Networks for Open Set Recognition
Mar 19, 2021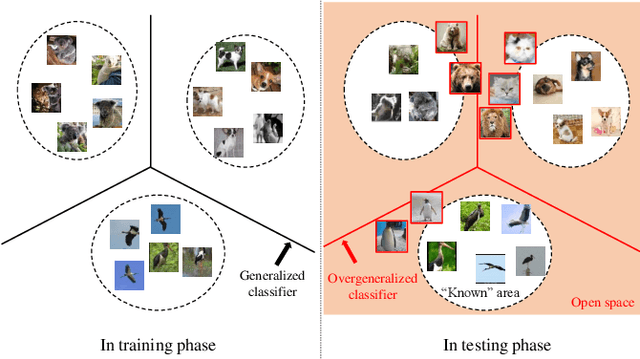
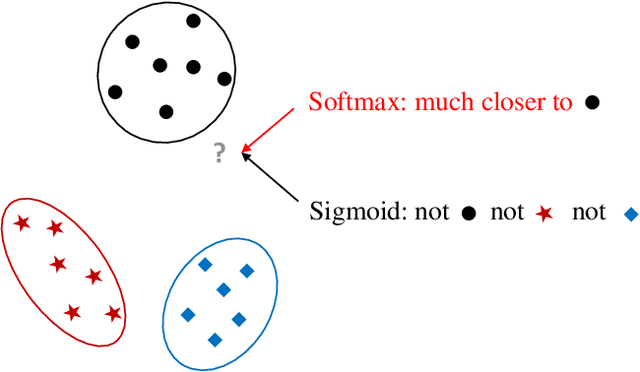

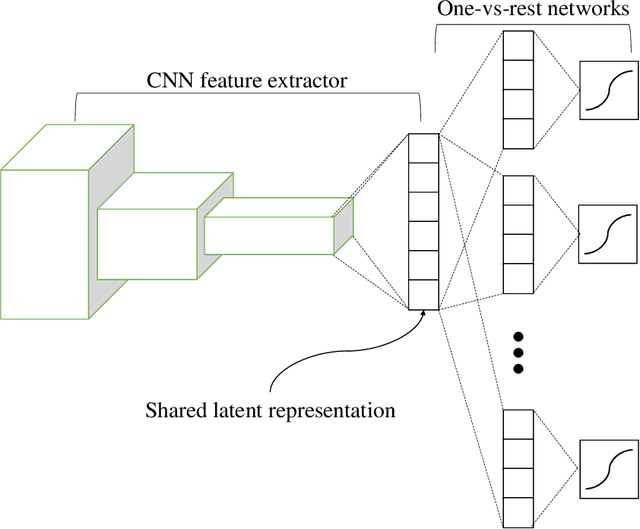
Unknown examples that are unseen during training often appear in real-world machine learning tasks, and an intelligent self-learning system should be able to distinguish between known and unknown examples. Accordingly, open set recognition (OSR), which addresses the problem of classifying knowns and identifying unknowns, has recently been highlighted. However, conventional deep neural networks using a softmax layer are vulnerable to overgeneralization, producing high confidence scores for unknowns. In this paper, we propose a simple OSR method based on the intuition that OSR performance can be maximized by setting strict and sophisticated decision boundaries that reject unknowns while maintaining satisfactory classification performance on knowns. For this purpose, a novel network structure is proposed, in which multiple one-vs-rest networks (OVRNs) follow a convolutional neural network feature extractor. Here, the OVRN is a simple feed-forward neural network that enhances the ability to reject nonmatches by learning class-specific discriminative features. Furthermore, the collective decision score is modeled by combining the multiple decisions reached by the OVRNs to alleviate overgeneralization. Extensive experiments were conducted on various datasets, and the experimental results showed that the proposed method performed significantly better than the state-of-the-art methods by effectively reducing overgeneralization.
Freudian and Newtonian Recurrent Cell for Sequential Recommendation
Feb 11, 2021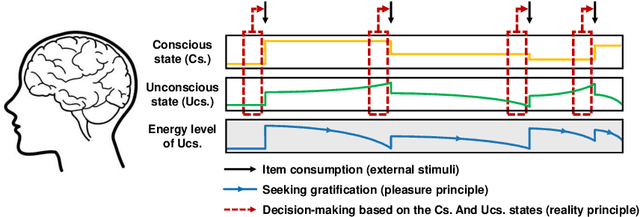
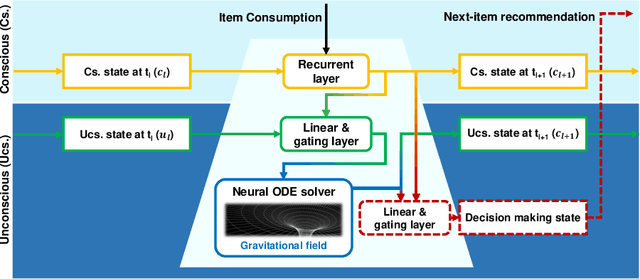
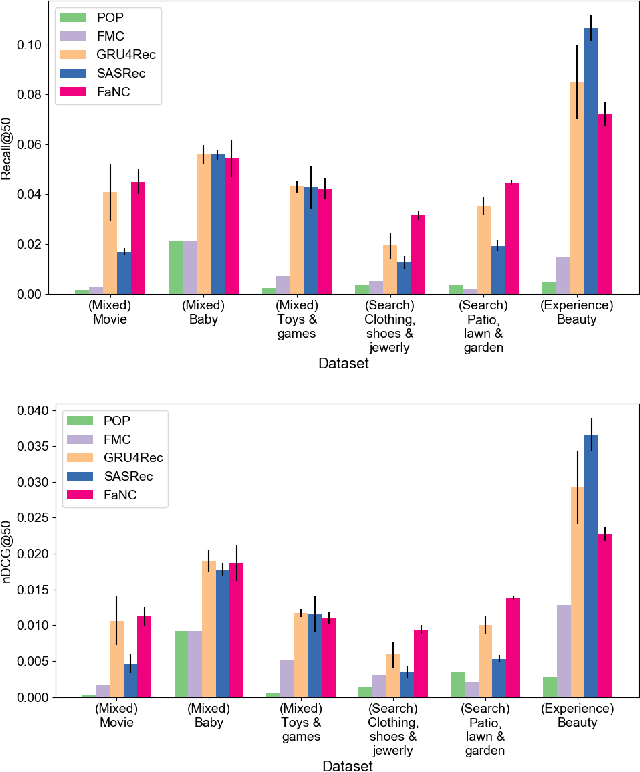
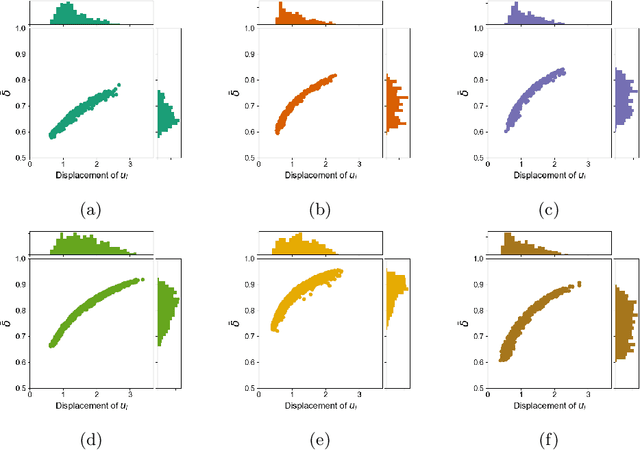
A sequential recommender system aims to recommend attractive items to users based on behaviour patterns. The predominant sequential recommendation models are based on natural language processing models, such as the gated recurrent unit, that embed items in some defined space and grasp the user's long-term and short-term preferences based on the item embeddings. However, these approaches lack fundamental insight into how such models are related to the user's inherent decision-making process. To provide this insight, we propose a novel recurrent cell, namely FaNC, from Freudian and Newtonian perspectives. FaNC divides the user's state into conscious and unconscious states, and the user's decision process is modelled by Freud's two principles: the pleasure principle and reality principle. To model the pleasure principle, i.e., free-floating user's instinct, we place the user's unconscious state and item embeddings in the same latent space and subject them to Newton's law of gravitation. Moreover, to recommend items to users, we model the reality principle, i.e., balancing the conscious and unconscious states, via a gating function. Based on extensive experiments on various benchmark datasets, this paper provides insight into the characteristics of the proposed model. FaNC initiates a new direction of sequential recommendations at the convergence of psychoanalysis and recommender systems.
One-vs-Rest Network-based Deep Probability Model for Open Set Recognition
Apr 17, 2020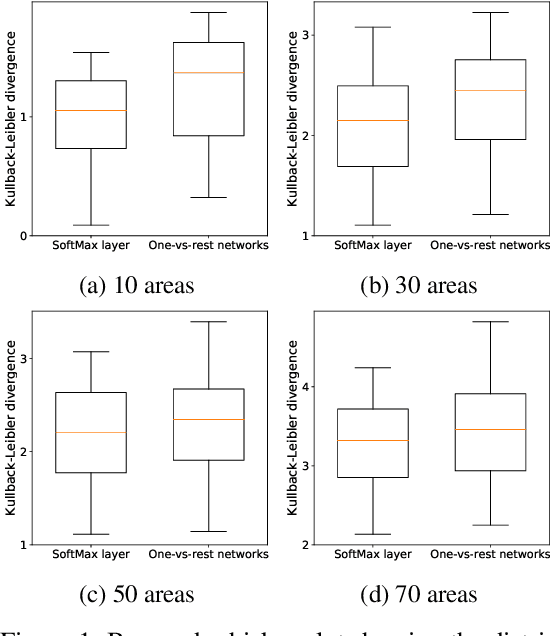
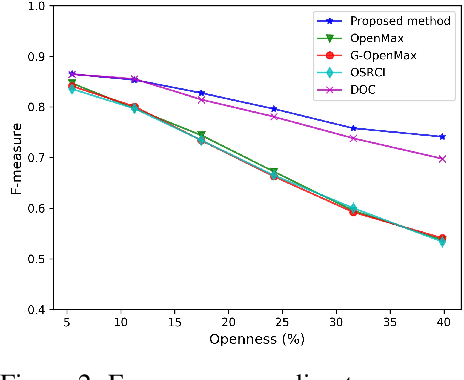

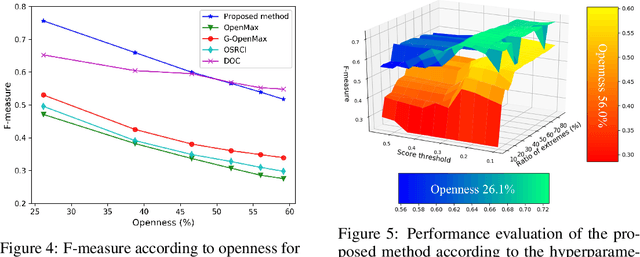
Unknown examples that are unseen during training often appear in real-world computer vision tasks, and an intelligent self-learning system should be able to differentiate between known and unknown examples. Open set recognition, which addresses this problem, has been studied for approximately a decade. However, conventional open set recognition methods based on deep neural networks (DNNs) lack a foundation for post recognition score analysis. In this paper, we propose a DNN structure in which multiple one-vs-rest sigmoid networks follow a convolutional neural network feature extractor. A one-vs-rest network, which is composed of rectified linear unit activation functions for the hidden layers and a single sigmoid target class output node, can maximize the ability to learn information from nonmatch examples. Furthermore, the network yields a sophisticated nonlinear features-to-output mapping that is explainable in the feature space. By introducing extreme value theory-based calibration techniques, the nonlinear and explainable mapping provides a well-grounded class membership probability models. Our experiments show that one-vs-rest networks can provide more informative hidden representations for unknown examples than the commonly used SoftMax layer. In addition, the proposed probability model outperformed the state-of-the art methods in open set classification scenarios.
Amplifying the Imitation Effect for Reinforcement Learning of UCAV's Mission Execution
Jan 17, 2019

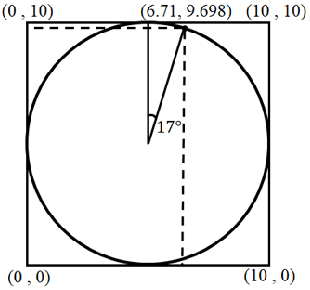
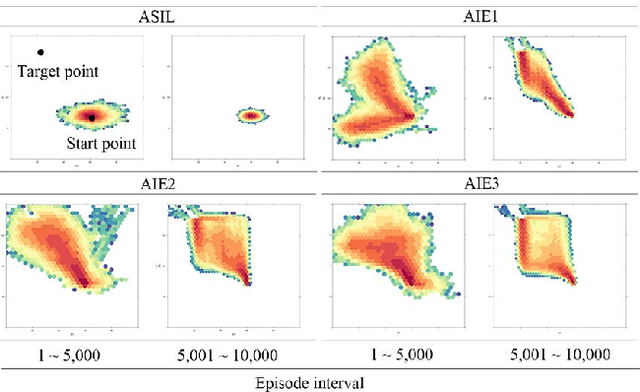
This paper proposes a new reinforcement learning (RL) algorithm that enhances exploration by amplifying the imitation effect (AIE). This algorithm consists of self-imitation learning and random network distillation algorithms. We argue that these two algorithms complement each other and that combining these two algorithms can amplify the imitation effect for exploration. In addition, by adding an intrinsic penalty reward to the state that the RL agent frequently visits and using replay memory for learning the feature state when using an exploration bonus, the proposed approach leads to deep exploration and deviates from the current converged policy. We verified the exploration performance of the algorithm through experiments in a two-dimensional grid environment. In addition, we applied the algorithm to a simulated environment of unmanned combat aerial vehicle (UCAV) mission execution, and the empirical results show that AIE is very effective for finding the UCAV's shortest flight path to avoid an enemy's missiles.