 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Teaching with Shared Classifier for Knowledge Distillation
Jun 14, 2024



Knowledge distillation (KD) is a technique used to transfer knowledge from an overparameterized teacher network to a less-parameterized student network, thereby minimizing the incurred performance loss. KD methods can be categorized into offline and online approaches. Offline KD leverages a powerful pretrained teacher network, while online KD allows the teacher network to be adjusted dynamically to enhance the learning effectiveness of the student network. Recently, it has been discovered that sharing the classifier of the teacher network can significantly boost the performance of the student network with only a minimal increase in the number of network parameters. Building on these insights, we propose adaptive teaching with a shared classifier (ATSC). In ATSC, the pretrained teacher network self-adjusts to better align with the learning needs of the student network based on its capabilities, and the student network benefits from the shared classifier, enhancing its performance. Additionally, we extend ATSC to environments with multiple teachers. We conduct extensive experiments, demonstrating the effectiveness of the proposed KD method. Our approach achieves state-of-the-art results on the CIFAR-100 and ImageNet datasets in both single-teacher and multiteacher scenarios, with only a modest increase in the number of required model parameters. The source code is publicly available at https://github.com/random2314235/ATSC.
Hybrid FedGraph: An efficient hybrid federated learning algorithm using graph convolutional neural network
Apr 15, 2024



Federated learning is an emerging paradigm for decentralized training of machine learning models on distributed clients, without revealing the data to the central server. Most existing works have focused on horizontal or vertical data distributions, where each client possesses different samples with shared features, or each client fully shares only sample indices, respectively. However, the hybrid scheme is much less studied, even though it is much more common in the real world. Therefore, in this paper, we propose a generalized algorithm, FedGraph, that introduces a graph convolutional neural network to capture feature-sharing information while learning features from a subset of clients. We also develop a simple but effective clustering algorithm that aggregates features produced by the deep neural networks of each client while preserving data privacy.
Learning Multiple Coordinated Agents under Directed Acyclic Graph Constraints
Jul 13, 2023



This paper proposes a novel multi-agent reinforcement learning (MARL) method to learn multiple coordinated agents under directed acyclic graph (DAG) constraints. Unlike existing MARL approaches, our method explicitly exploits the DAG structure between agents to achieve more effective learning performance. Theoretically, we propose a novel surrogate value function based on a MARL model with synthetic rewards (MARLM-SR) and prove that it serves as a lower bound of the optimal value function. Computationally, we propose a practical training algorithm that exploits new notion of leader agent and reward generator and distributor agent to guide the decomposed follower agents to better explore the parameter space in environments with DAG constraints. Empirically, we exploit four DAG environments including a real-world scheduling for one of Intel's high volume packaging and test factory to benchmark our methods and show it outperforms the other non-DAG approaches.
Synthetic Unknown Class Learning for Learning Unknowns
Nov 15, 2021

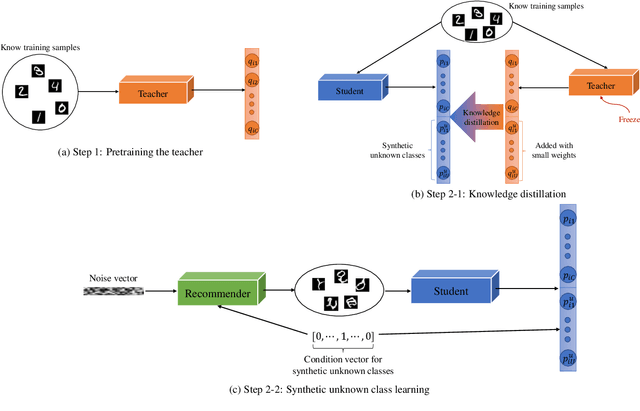
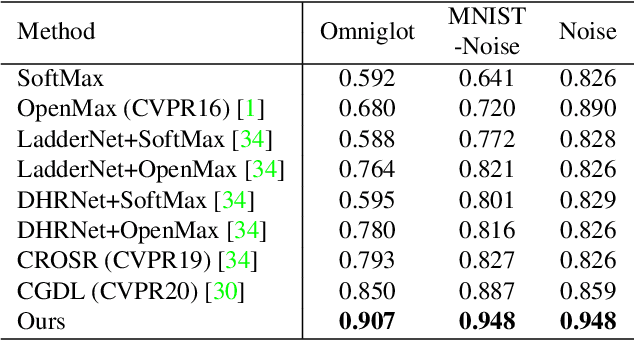
This paper addresses the open set recognition (OSR) problem, where the goal is to correctly classify samples of known classes while detecting unknown samples to reject. In the OSR problem, "unknown" is assumed to have infinite possibilities because we have no knowledge about unknowns until they emerge. Intuitively, the more an OSR system explores the possibilities of unknowns, the more likely it is to detect unknowns. Thus, this paper proposes a novel synthetic unknown class learning method that generates unknown-like samples while maintaining diversity between the generated samples and learns these samples. In addition to this unknown sample generation process, knowledge distillation is introduced to provide room for learning synthetic unknowns. By learning the unknown-like samples and known samples in an alternating manner, the proposed method can not only experience diverse synthetic unknowns but also reduce overgeneralization with respect to known classes. Experiments on several benchmark datasets show that the proposed method significantly outperforms other state-of-the-art approaches. It is also shown that realistic unknown digits can be generated and learned via the proposed method after training on the MNIST dataset.
Teacher-Explorer-Student Learning: A Novel Learning Method for Open Set Recognition
Mar 23, 2021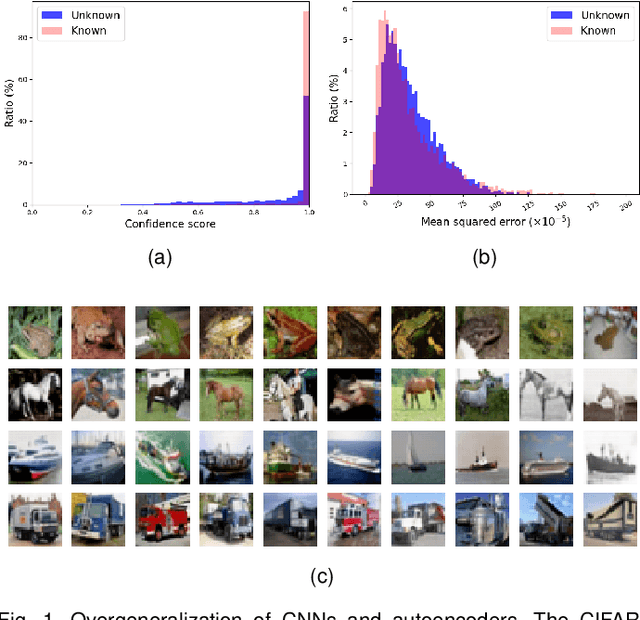
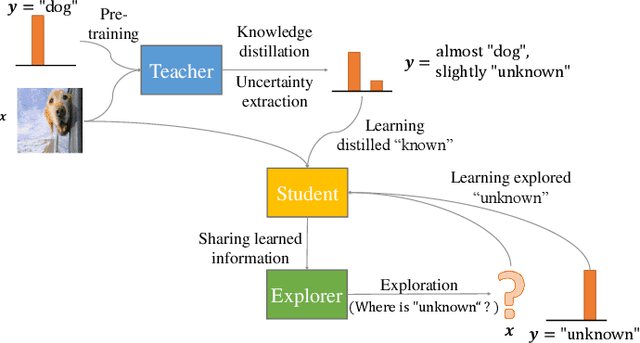
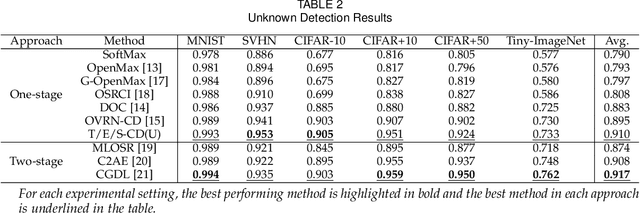
If an unknown example that is not seen during training appears, most recognition systems usually produce overgeneralized results and determine that the example belongs to one of the known classes. To address this problem, teacher-explorer-student (T/E/S) learning, which adopts the concept of open set recognition (OSR) that aims to reject unknown samples while minimizing the loss of classification performance on known samples, is proposed in this study. In this novel learning method, overgeneralization of deep learning classifiers is significantly reduced by exploring various possibilities of unknowns. Here, the teacher network extracts some hints about unknowns by distilling the pretrained knowledge about knowns and delivers this distilled knowledge to the student. After learning the distilled knowledge, the student network shares the learned information with the explorer network. Then, the explorer network shares its exploration results by generating unknown-like samples and feeding the samples to the student network. By repeating this alternating learning process, the student network experiences a variety of synthetic unknowns, reducing overgeneralization. Extensive experiments were conducted, and the experimental results showed that each component proposed in this paper significantly contributes to the improvement in OSR performance. As a result, the proposed T/E/S learning method outperformed current state-of-the-art methods.
Collective Decision of One-vs-Rest Networks for Open Set Recognition
Mar 19, 2021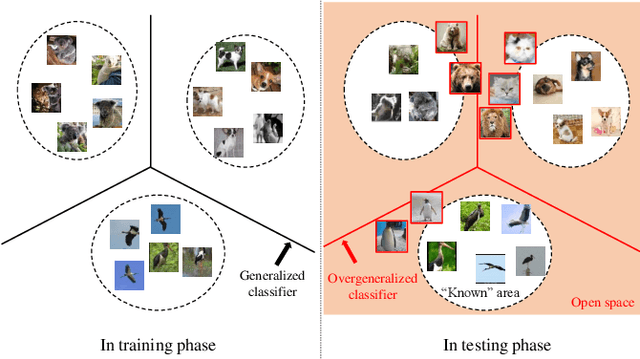
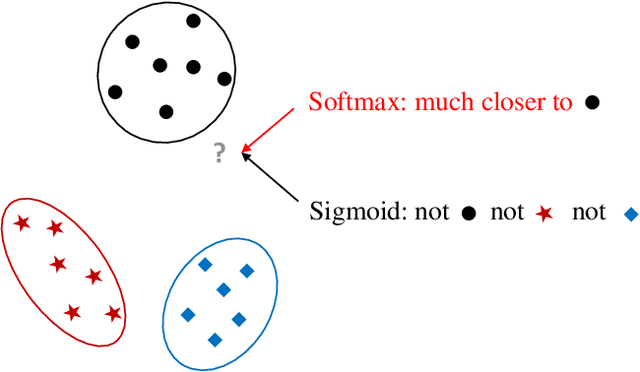

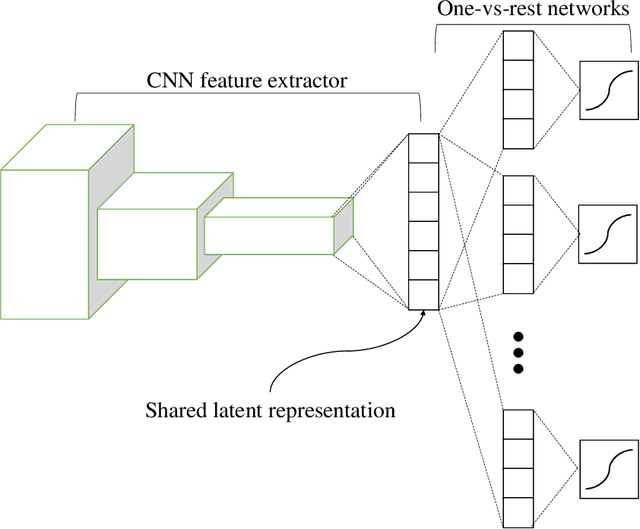
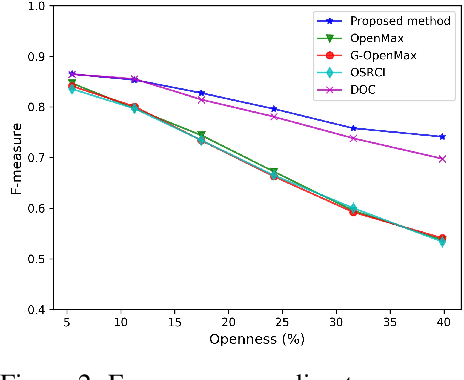
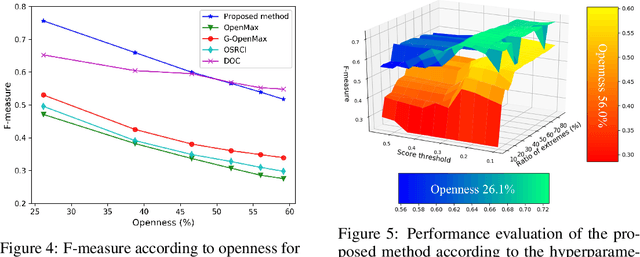
Unknown examples that are unseen during training often appear in real-world machine learning tasks, and an intelligent self-learning system should be able to distinguish between known and unknown examples. Accordingly, open set recognition (OSR), which addresses the problem of classifying knowns and identifying unknowns, has recently been highlighted. However, conventional deep neural networks using a softmax layer are vulnerable to overgeneralization, producing high confidence scores for unknowns. In this paper, we propose a simple OSR method based on the intuition that OSR performance can be maximized by setting strict and sophisticated decision boundaries that reject unknowns while maintaining satisfactory classification performance on knowns. For this purpose, a novel network structure is proposed, in which multiple one-vs-rest networks (OVRNs) follow a convolutional neural network feature extractor. Here, the OVRN is a simple feed-forward neural network that enhances the ability to reject nonmatches by learning class-specific discriminative features. Furthermore, the collective decision score is modeled by combining the multiple decisions reached by the OVRNs to alleviate overgeneralization. Extensive experiments were conducted on various datasets, and the experimental results showed that the proposed method performed significantly better than the state-of-the-art methods by effectively reducing overgeneralization.
One-vs-Rest Network-based Deep Probability Model for Open Set Recognition
Apr 17, 2020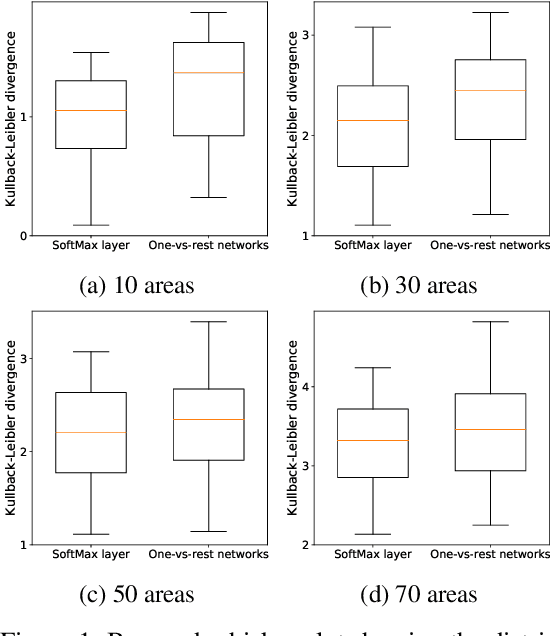

Unknown examples that are unseen during training often appear in real-world computer vision tasks, and an intelligent self-learning system should be able to differentiate between known and unknown examples. Open set recognition, which addresses this problem, has been studied for approximately a decade. However, conventional open set recognition methods based on deep neural networks (DNNs) lack a foundation for post recognition score analysis. In this paper, we propose a DNN structure in which multiple one-vs-rest sigmoid networks follow a convolutional neural network feature extractor. A one-vs-rest network, which is composed of rectified linear unit activation functions for the hidden layers and a single sigmoid target class output node, can maximize the ability to learn information from nonmatch examples. Furthermore, the network yields a sophisticated nonlinear features-to-output mapping that is explainable in the feature space. By introducing extreme value theory-based calibration techniques, the nonlinear and explainable mapping provides a well-grounded class membership probability models. Our experiments show that one-vs-rest networks can provide more informative hidden representations for unknown examples than the commonly used SoftMax layer. In addition, the proposed probability model outperformed the state-of-the art methods in open set classification scenarios.