 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based Bootstrap of Controlled Markov Chains
May 12, 2026We propose and analyze a model-based bootstrap for transition kernels in finite controlled Markov chains (CMCs) with possibly nonstationary or history-dependent control policies, a setting that arises naturally in offline reinforcement learning (RL) when the behavior policy generating the data is unknown. We establish distributional consistency of the bootstrap transition estimator in both a single long-chain regime and the episodic offline RL regime. The key technical tools are a novel bootstrap law of large numbers (LLN) for the visitation counts and a novel use of the martingale central limit theorem (CLT) for the bootstrap transition increments. We extend bootstrap distributional consistency to the downstream targets of offline policy evaluation (OPE) and optimal policy recovery (OPR) via the delta method by verifying Hadamard differentiability of the Bellman operators, yielding asymptotically valid confidence intervals for value and $Q$-functions. Experiments on the RiverSwim problem show that the proposed bootstrap confidence intervals (CIs), especially the percentile CIs, outperform the episodic bootstrap and plug-in CLT CIs, and are often close to nominal ($50\%$, $90\%$, $95\%$) coverage, while the baselines are poorly calibrated at small sample sizes and short episode lengths.
Rank-Accuracy Trade-off for LoRA: A Gradient-Flow Analysis
Feb 10, 2026Previous empirical studies have shown that LoRA achieves accuracy comparable to full-parameter methods on downstream fine-tuning tasks, even for rank-1 updates. By contrast, the theoretical underpinnings of the dependence of LoRA's accuracy on update rank remain relatively unexplored. In this work, we compare the accuracy of rank-r LoRA updates against full-parameter updates for fine-tuning tasks from a dynamical systems perspective. We perform gradient flow analysis in both full-rank and low-rank regimes to establish explicit relationships between rank and accuracy for two loss functions under LoRA. While gradient flow equations for LoRA are presented in prior work, we rigorously derive their form and show that they are identical for simultaneous and sequential LoRA parameter updates. We then use the resulting dynamical system equations to obtain closed-form relationships between LoRA rank and accuracy for trace-squared and Frobenius-norm low-rank approximation loss functions.
On the Convergence Rate of LoRA Gradient Descent
Dec 20, 2025The low-rank adaptation (LoRA) algorithm for fine-tuning large models has grown popular in recent years due to its remarkable performance and low computational requirements. LoRA trains two ``adapter" matrices that form a low-rank representation of the model parameters, thereby massively reducing the number of parameters that need to be updated at every step. Although LoRA is simple, its convergence is poorly understood due to the lack of Lipschitz smoothness, a key condition for classic convergence analyses. As a result, current theoretical results only consider asymptotic behavior or assume strong boundedness conditions which artificially enforce Lipschitz smoothness. In this work, we provide for the first time a non-asymptotic convergence analysis of the \textit{original LoRA gradient descent} algorithm, which reflects widespread practice, without such assumptions. Our work relies on three key steps: i) reformulating the problem in terms of the outer product of the stacked adapter matrices, ii) a modified descent lemma for the ``Lipschitz-like" reparametrized function, and iii) controlling the step size. With this approach, we prove that LoRA gradient descent converges to a stationary point at rate $O(\frac{1}{\log T})$, where $T$ is the number of iterations.
Zero-shot Graph Reasoning via Retrieval Augmented Framework with LLMs
Sep 16, 2025We propose a new, training-free method, Graph Reasoning via Retrieval Augmented Framework (GRRAF), that harnesses retrieval-augmented generation (RAG) alongside the code-generation capabilities of large language models (LLMs) to address a wide range of graph reasoning tasks. In GRRAF, the target graph is stored in a graph database, and the LLM is prompted to generate executable code queries that retrieve the necessary information. This approach circumvents the limitations of existing methods that require extensive finetuning or depend on predefined algorithms, and it incorporates an error feedback loop with a time-out mechanism to ensure both correctness and efficiency. Experimental evaluations on the GraphInstruct dataset reveal that GRRAF achieves 100% accuracy on most graph reasoning tasks, including cycle detection, bipartite graph checks, shortest path computation, and maximum flow, while maintaining consistent token costs regardless of graph sizes. Imperfect but still very high performance is observed on subgraph matching. Notably, GRRAF scales effectively to large graphs with up to 10,000 nodes.
Subgrid BoostCNN: Efficient Boosting of Convolutional Networks via Gradient-Guided Feature Selection
Jul 30, 2025



Convolutional Neural Networks (CNNs) have achieved remarkable success across a wide range of machine learning tasks by leveraging hierarchical feature learning through deep architectures. However, the large number of layers and millions of parameters often make CNNs computationally expensive to train, requiring extensive time and manual tuning to discover optimal architectures. In this paper, we introduce a novel framework for boosting CNN performance that integrates dynamic feature selection with the principles of BoostCNN. Our approach incorporates two key strategies: subgrid selection and importance sampling, to guide training toward informative regions of the feature space. We further develop a family of algorithms that embed boosting weights directly into the network training process using a least squares loss formulation. This integration not only alleviates the burden of manual architecture design but also enhances accuracy and efficiency. Experimental results across several fine-grained classification benchmarks demonstrate that our boosted CNN variants consistently outperform conventional CNNs in both predictive performance and training speed.
FedGA-Tree: Federated Decision Tree using Genetic Algorithm
Jun 09, 2025In recent years, with rising concerns for data privacy, Federated Learning has gained prominence, as it enables collaborative training without the aggregation of raw data from participating clients. However, much of the current focus has been on parametric gradient-based models, while nonparametric counterparts such as decision tree are relatively understudied. Existing methods for adapting decision trees to Federated Learning generally combine a greedy tree-building algorithm with differential privacy to produce a global model for all clients. These methods are limited to classification trees and categorical data due to the constraints of differential privacy. In this paper, we explore an alternative approach that utilizes Genetic Algorithm to facilitate the construction of personalized decision trees and accommodate categorical and numerical data, thus allowing for both classification and regression trees. Comprehensive experiments demonstrate that our method surpasses decision trees trained solely on local data and a benchmark algorithm.
BEAR: BGP Event Analysis and Reporting
Jun 04, 2025

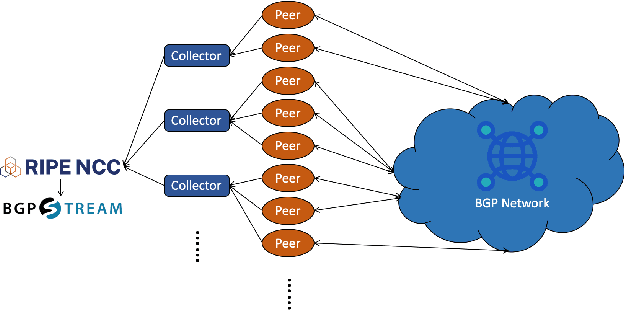

The Internet comprises of interconnected, independently managed Autonomous Systems (AS) that rely on the Border Gateway Protocol (BGP) for inter-domain routing. BGP anomalies--such as route leaks and hijacks--can divert traffic through unauthorized or inefficient paths, jeopardizing network reliability and security. Although existing rule-based and machine learning methods can detect these anomalies using structured metrics, they still require experts with in-depth BGP knowledge of, for example, AS relationships and historical incidents, to interpret events and propose remediation. In this paper, we introduce BEAR (BGP Event Analysis and Reporting), a novel framework that leverages large language models (LLMs) to automatically generate comprehensive reports explaining detected BGP anomaly events. BEAR employs a multi-step reasoning process that translates tabular BGP data into detailed textual narratives, enhancing interpretability and analytical precision. To address the limited availability of publicly documented BGP anomalies, we also present a synthetic data generation framework powered by LLMs. Evaluations on both real and synthetic datasets demonstrate that BEAR achieves 100% accuracy, outperforming Chain-of-Thought and in-context learning baselines. This work pioneers an automated approach for explaining BGP anomaly events, offering valuable operational insights for network management.
Technical Debt in In-Context Learning: Diminishing Efficiency in Long Context
Feb 07, 2025Transformers have demonstrated remarkable in-context learning (ICL) capabilities, adapting to new tasks by simply conditioning on demonstrations without parameter updates. Compelling empirical and theoretical evidence suggests that ICL, as a general-purpose learner, could outperform task-specific models. However, it remains unclear to what extent the transformers optimally learn in-context compared to principled learning algorithms. To bridge this gap, we introduce a new framework for quantifying optimality of ICL as a learning algorithm in stylized settings. Our findings reveal a striking dichotomy: while ICL initially matches the efficiency of a Bayes optimal estimator, its efficiency significantly deteriorates in long context. Through an information-theoretic analysis, we show that the diminishing efficiency is inherent to ICL. These results clarify the trade-offs in adopting ICL as a universal problem solver, motivating a new generation of on-the-fly adaptive methods without the diminishing efficiency.
Federated Low-Rank Tensor Estimation for Multimodal Image Reconstruction
Feb 04, 2025



Low-rank tensor estimation offers a powerful approach to addressing high-dimensional data challenges and can substantially improve solutions to ill-posed inverse problems, such as image reconstruction under noisy or undersampled conditions. Meanwhile, tensor decomposition has gained prominence in federated learning (FL) due to its effectiveness in exploiting latent space structure and its capacity to enhance communication efficiency. In this paper, we present a federated image reconstruction method that applies Tucker decomposition, incorporating joint factorization and randomized sketching to manage large-scale, multimodal data. Our approach avoids reconstructing full-size tensors and supports heterogeneous ranks, allowing clients to select personalized decomposition ranks based on prior knowledge or communication capacity. Numerical results demonstrate that our method achieves superior reconstruction quality and communication compression compared to existing approaches, thereby highlighting its potential for multimodal inverse problems in the FL setting.
Continuous-Time Analysis of Federated Averaging
Jan 31, 2025Federated averaging (FedAvg) is a popular algorithm for horizontal federated learning (FL), where samples are gathered across different clients and are not shared with each other or a central server. Extensive convergence analysis of FedAvg exists for the discrete iteration setting, guaranteeing convergence for a range of loss functions and varying levels of data heterogeneity. We extend this analysis to the continuous-time setting where the global weights evolve according to a multivariate stochastic differential equation (SDE), which is the first time FedAvg has been studied from the continuous-time perspective. We use techniques from stochastic processes to establish convergence guarantees under different loss functions, some of which are more general than existing work in the discrete setting. We also provide conditions for which FedAvg updates to the server weights can be approximated as normal random variables. Finally, we use the continuous-time formulation to reveal generalization properties of FedAvg.