 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-Time Analysis of Federated Averaging
Jan 31, 2025Federated averaging (FedAvg) is a popular algorithm for horizontal federated learning (FL), where samples are gathered across different clients and are not shared with each other or a central server. Extensive convergence analysis of FedAvg exists for the discrete iteration setting, guaranteeing convergence for a range of loss functions and varying levels of data heterogeneity. We extend this analysis to the continuous-time setting where the global weights evolve according to a multivariate stochastic differential equation (SDE), which is the first time FedAvg has been studied from the continuous-time perspective. We use techniques from stochastic processes to establish convergence guarantees under different loss functions, some of which are more general than existing work in the discrete setting. We also provide conditions for which FedAvg updates to the server weights can be approximated as normal random variables. Finally, we use the continuous-time formulation to reveal generalization properties of FedAvg.
Federated Automated Feature Engineering
Dec 05, 2024Automated feature engineering (AutoFE) is used to automatically create new features from original features to improve predictive performance without needing significant human intervention and expertise. Many algorithms exist for AutoFE, but very few approaches exist for the federated learning (FL) setting where data is gathered across many clients and is not shared between clients or a central server. We introduce AutoFE algorithms for the horizontal, vertical, and hybrid FL settings, which differ in how the data is gathered across clients. To the best of our knowledge, we are the first to develop AutoFE algorithms for the horizontal and hybrid FL cases, and we show that the downstream model performance of federated AutoFE is similar to the case where data is held centrally and AutoFE is performed centrally.
IIFE: Interaction Information Based Automated Feature Engineering
Sep 07, 2024Automated feature engineering (AutoFE) is the process of automatically building and selecting new features that help improve downstream predictive performance. While traditional feature engineering requires significant domain expertise and time-consuming iterative testing, AutoFE strives to make feature engineering easy and accessible to all data science practitioners. We introduce a new AutoFE algorithm, IIFE, based on determining which feature pairs synergize well through an information-theoretic perspective called interaction information. We demonstrate the superior performance of IIFE over existing algorithms. We also show how interaction information can be used to improve existing AutoFE algorithms. Finally, we highlight several critical experimental setup issues in the existing AutoFE literature and their effects on performance.
A Primal-Dual Algorithm for Hybrid Federated Learning
Oct 14, 2022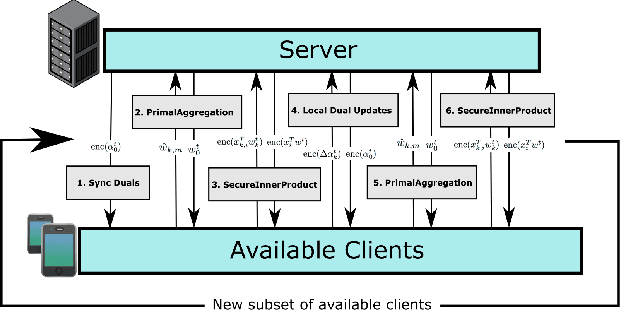

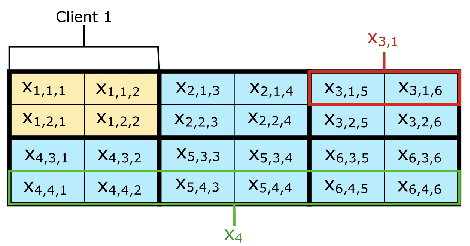
Very few methods for hybrid federated learning, where clients only hold subsets of both features and samples, exist. Yet, this scenario is very important in practical settings. We provide a fast, robust algorithm for hybrid federated learning that hinges on Fenchel Duality. We prove the convergence of the algorithm to the same solution as if the model was trained centrally in a variety of practical regimes. Furthermore, we provide experimental results that demonstrate the performance improvements of the algorithm over a commonly used method in federated learning, FedAvg. We also provide privacy considerations and necessary steps to protect client data.