 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgrid BoostCNN: Efficient Boosting of Convolutional Networks via Gradient-Guided Feature Selection
Jul 30, 2025



Convolutional Neural Networks (CNNs) have achieved remarkable success across a wide range of machine learning tasks by leveraging hierarchical feature learning through deep architectures. However, the large number of layers and millions of parameters often make CNNs computationally expensive to train, requiring extensive time and manual tuning to discover optimal architectures. In this paper, we introduce a novel framework for boosting CNN performance that integrates dynamic feature selection with the principles of BoostCNN. Our approach incorporates two key strategies: subgrid selection and importance sampling, to guide training toward informative regions of the feature space. We further develop a family of algorithms that embed boosting weights directly into the network training process using a least squares loss formulation. This integration not only alleviates the burden of manual architecture design but also enhances accuracy and efficiency. Experimental results across several fine-grained classification benchmarks demonstrate that our boosted CNN variants consistently outperform conventional CNNs in both predictive performance and training speed.
Modular Framework for Uncertainty Prediction in Autonomous Vehicle Motion Forecasting within Complex Traffic Scenarios
Jan 27, 2025



We propose a modular modeling framework designed to enhance the capture and validation of uncertainty in autonomous vehicle (AV) trajectory prediction. Departing from traditional deterministic methods, our approach employs a flexible, end-to-end differentiable probabilistic encoder-decoder architecture. This modular design allows the encoder and decoder to be trained independently, enabling seamless adaptation to diverse traffic scenarios without retraining the entire system. Our key contributions include: (1) a probabilistic heatmap predictor that generates context-aware occupancy grids for dynamic forecasting, (2) a modular training approach that supports independent component training and flexible adaptation, and (3) a structured validation scheme leveraging uncertainty metrics to evaluate robustness under high-risk conditions. To highlight the benefits of our framework, we benchmark it against an end-to-end baseline, demonstrating faster convergence, improved stability, and flexibility. Experimental results validate these advantages, showcasing the capacity of the framework to efficiently handle complex scenarios while ensuring reliable predictions and robust uncertainty representation. This modular design offers significant practical utility and scalability for real-world autonomous driving applications.
Video to Video Generative Adversarial Network for Few-shot Learning Based on Policy Gradient
Oct 28, 2024
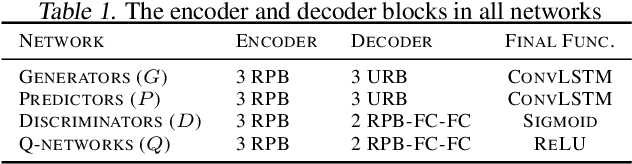
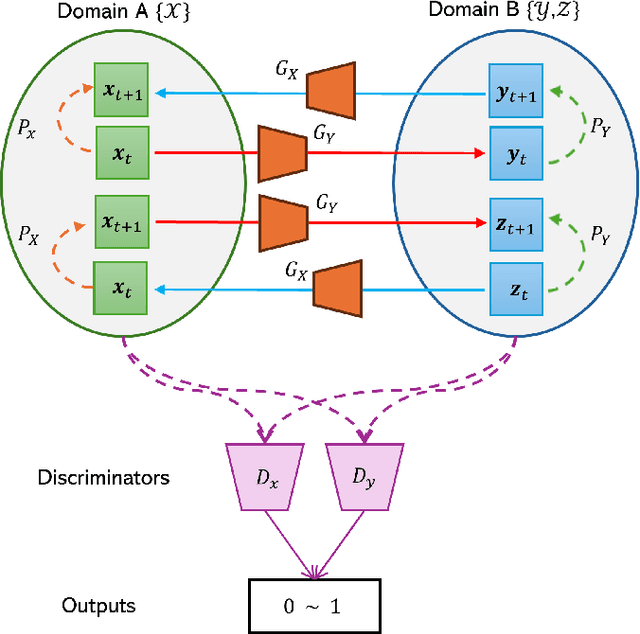
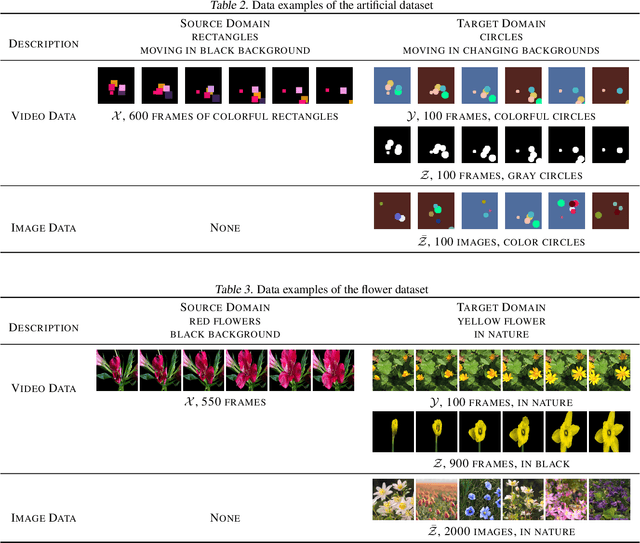
The development of sophisticated models for video-to-video synthesis has been facilitated by recent advances in deep reinforcement learning and generative adversarial networks (GANs). In this paper, we propose RL-V2V-GAN, a new deep neural network approach based on reinforcement learning for unsupervised conditional video-to-video synthesis. While preserving the unique style of the source video domain, our approach aims to learn a mapping from a source video domain to a target video domain. We train the model using policy gradient and employ ConvLSTM layers to capture the spatial and temporal information by designing a fine-grained GAN architecture and incorporating spatio-temporal adversarial goals. The adversarial losses aid in content translation while preserving style. Unlike traditional video-to-video synthesis methods requiring paired inputs, our proposed approach is more general because it does not require paired inputs. Thus, when dealing with limited videos in the target domain, i.e., few-shot learning, it is particularly effective. Our experiments show that RL-V2V-GAN can produce temporally coherent video results. These results highlight the potential of our approach for further advances in video-to-video synthesis.
IIFE: Interaction Information Based Automated Feature Engineering
Sep 07, 2024Automated feature engineering (AutoFE) is the process of automatically building and selecting new features that help improve downstream predictive performance. While traditional feature engineering requires significant domain expertise and time-consuming iterative testing, AutoFE strives to make feature engineering easy and accessible to all data science practitioners. We introduce a new AutoFE algorithm, IIFE, based on determining which feature pairs synergize well through an information-theoretic perspective called interaction information. We demonstrate the superior performance of IIFE over existing algorithms. We also show how interaction information can be used to improve existing AutoFE algorithms. Finally, we highlight several critical experimental setup issues in the existing AutoFE literature and their effects on performance.
Unsupervised Video Summarization
Nov 07, 2023This paper introduces a new, unsupervised method for automatic video summarization using ideas from generative adversarial networks but eliminating the discriminator, having a simple loss function, and separating training of different parts of the model. An iterative training strategy is also applied by alternately training the reconstructor and the frame selector for multiple iterations. Furthermore, a trainable mask vector is added to the model in summary generation during training and evaluation. The method also includes an unsupervised model selection algorithm. Results from experiments on two public datasets (SumMe and TVSum) and four datasets we created (Soccer, LoL, MLB, and ShortMLB) demonstrate the effectiveness of each component on the model performance, particularly the iterative training strategy. Evaluations and comparisons with the state-of-the-art methods highlight the advantages of the proposed method in performance, stability, and training efficiency.
DIALGEN: Collaborative Human-LM Generated Dialogues for Improved Understanding of Human-Human Conversations
Jul 13, 2023



Applications that could benefit from automatic understanding of human-human conversations often come with challenges associated with private information in real-world data such as call center or clinical conversations. Working with protected data also increases costs of annotation, which limits technology development. To address these challenges, we propose DIALGEN, a human-in-the-loop semi-automated dialogue generation framework. DIALGEN uses a language model (ChatGPT) that can follow schema and style specifications to produce fluent conversational text, generating a complex conversation through iteratively generating subdialogues and using human feedback to correct inconsistencies or redirect the flow. In experiments on structured summarization of agent-client information gathering calls, framed as dialogue state tracking, we show that DIALGEN data enables significant improvement in model performance.
S-Omninet: Structured Data Enhanced Universal Multimodal Learning Architecture
Jul 01, 2023



Multimodal multitask learning has attracted an increasing interest in recent years. Singlemodal models have been advancing rapidly and have achieved astonishing results on various tasks across multiple domains. Multimodal learning offers opportunities for further improvements by integrating data from multiple modalities. Many methods are proposed to learn on a specific type of multimodal data, such as vision and language data. A few of them are designed to handle several modalities and tasks at a time. In this work, we extend and improve Omninet, an architecture that is capable of handling multiple modalities and tasks at a time, by introducing cross-cache attention, integrating patch embeddings for vision inputs, and supporting structured data. The proposed Structured-data-enhanced Omninet (S-Omninet) is a universal model that is capable of learning from structured data of various dimensions effectively with unstructured data through cross-cache attention, which enables interactions among spatial, temporal, and structured features. We also enhance spatial representations in a spatial cache with patch embeddings. We evaluate the proposed model on several multimodal datasets and demonstrate a significant improvement over the baseline, Omninet.
Early Classifying Multimodal Sequences
May 02, 2023Often pieces of information are received sequentially over time. When did one collect enough such pieces to classify? Trading wait time for decision certainty leads to early classification problems that have recently gained attention as a means of adapting classification to more dynamic environments. However, so far results have been limited to unimodal sequences. In this pilot study, we expand into early classifying multimodal sequences by combining existing methods. We show our new method yields experimental AUC advantages of up to 8.7%.
A Policy for Early Sequence Classification
Apr 07, 2023Sequences are often not received in their entirety at once, but instead, received incrementally over time, element by element. Early predictions yielding a higher benefit, one aims to classify a sequence as accurately as possible, as soon as possible, without having to wait for the last element. For this early sequence classification, we introduce our novel classifier-induced stopping. While previous methods depend on exploration during training to learn when to stop and classify, ours is a more direct, supervised approach. Our classifier-induced stopping achieves an average Pareto frontier AUC increase of 11.8% over multiple experiments.
Gradient-Boosted Based Structured and Unstructured Learning
Feb 28, 2023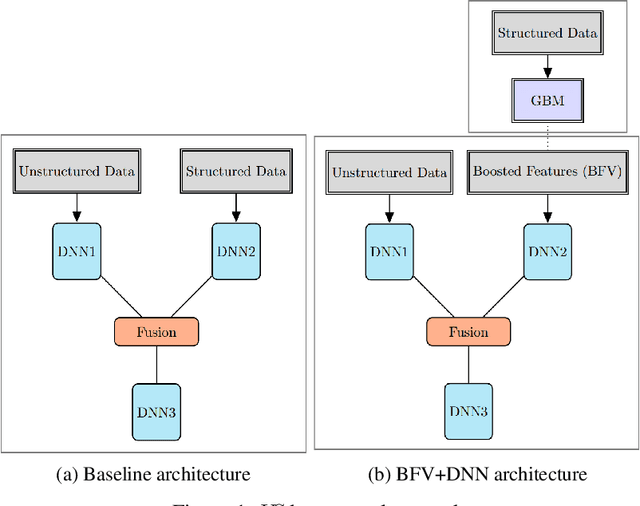
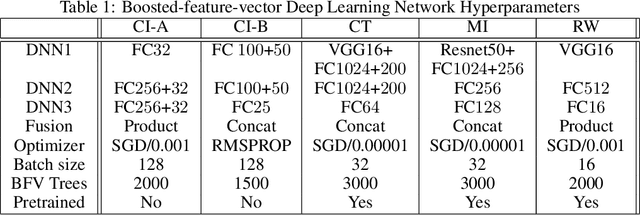
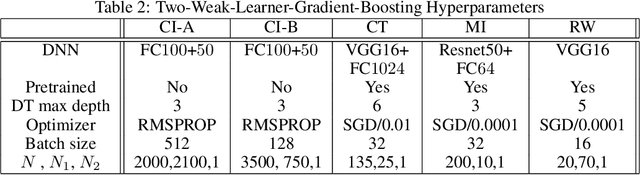
We propose two frameworks to deal with problem settings in which both structured and unstructured data are available. Structured data problems are best solved by traditional machine learning models such as boosting and tree-based algorithms, whereas deep learning has been widely applied to problems dealing with images, text, audio, and other unstructured data sources. However, for the setting in which both structured and unstructured data are accessible, it is not obvious what the best modeling approach is to enhance performance on both data sources simultaneously. Our proposed frameworks allow joint learning on both kinds of data by integrating the paradigms of boosting models and deep neural networks. The first framework, the boosted-feature-vector deep learning network, learns features from the structured data using gradient boosting and combines them with embeddings from unstructured data via a two-branch deep neural network. Secondly, the two-weak-learner boosting framework extends the boosting paradigm to the setting with two input data sources. We present and compare first- and second-order methods of this framework. Our experimental results on both public and real-world datasets show performance gains achieved by the frameworks over selected baselines by magnitudes of 0.1% - 4.7%.