 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust ASR + LLM? A Study on Speech Large Language Models' Ability to Identify and Understand Speaker in Spoken Dialogue
Sep 07, 2024
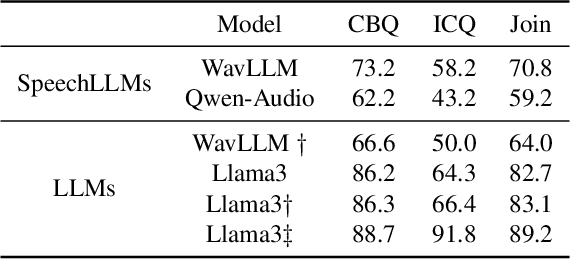
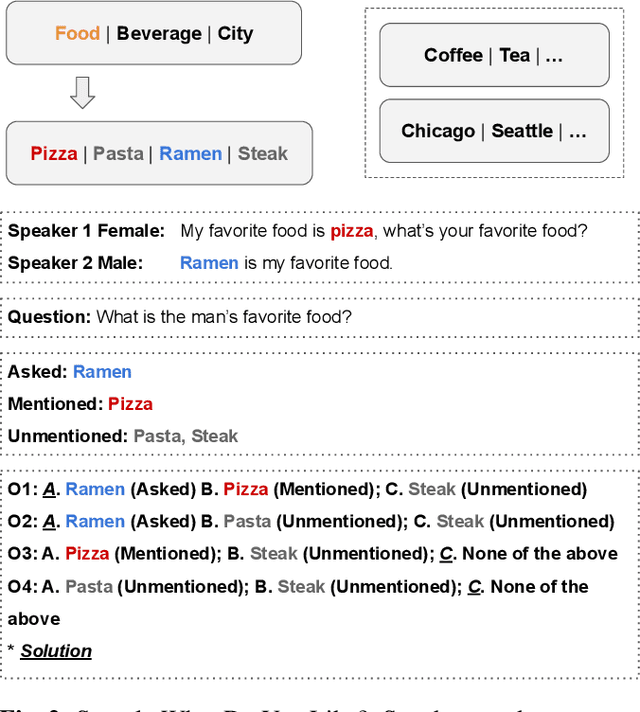
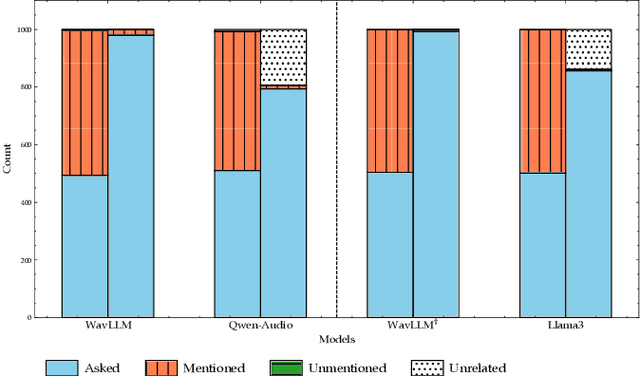
In recent years, we have observed a rapid advancement in speech language models (SpeechLLMs), catching up with humans' listening and reasoning abilities. Remarkably, SpeechLLMs have demonstrated impressive spoken dialogue question-answering (SQA) performance in benchmarks like Gaokao, the English listening test of the college entrance exam in China, which seemingly requires understanding both the spoken content and voice characteristics of speakers in a conversation. However, after carefully examining Gaokao's questions, we find the correct answers to many questions can be inferred from the conversation context alone without identifying the speaker asked in the question. Our evaluation of state-of-the-art models Qwen-Audio and WavLLM in both Gaokao and our proposed "What Do You Like?" dataset shows a significantly higher accuracy in these context-based questions than in identity-critical questions, which can only be answered correctly with correct speaker identification. Our results and analysis suggest that when solving SQA, the current SpeechLLMs exhibit limited speaker awareness from the audio and behave similarly to an LLM reasoning from the conversation transcription without sound. We propose that our definitions and automated classification of context-based and identity-critical questions could offer a more accurate evaluation framework of SpeechLLMs in SQA tasks.
Encode Once and Decode in Parallel: Efficient Transformer Decoding
Mar 19, 2024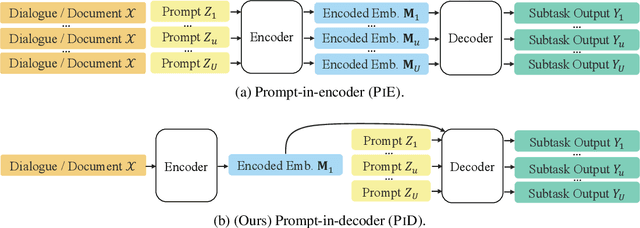

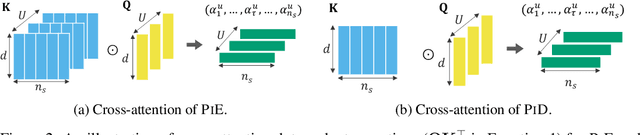
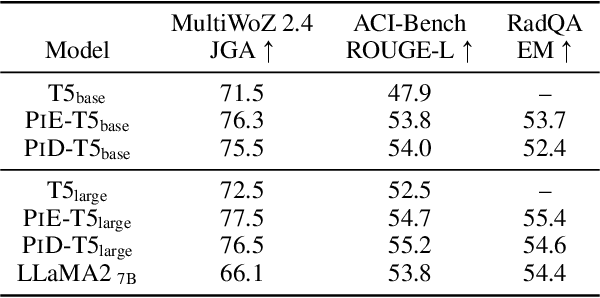
Transformer-based NLP models are powerful but have high computational costs that limit deployment scenarios. Finetuned encoder-decoder models are popular in specialized domains and can outperform larger more generalized decoder-only models, such as GPT-4. We introduce a new configuration for encoder-decoder models that improves efficiency on structured output and question-answering tasks where multiple outputs are required of a single input. Our method, prompt-in-decoder (PiD), encodes the input once and decodes output in parallel, boosting both training and inference efficiency by avoiding duplicate input encoding, thereby reducing the decoder's memory footprint. We achieve computation reduction that roughly scales with the number of subtasks, gaining up to 4.6x speed-up over state-of-the-art models for dialogue state tracking, summarization, and question-answering tasks with comparable or better performance. We release our training/inference code and checkpoints.
DIALGEN: Collaborative Human-LM Generated Dialogues for Improved Understanding of Human-Human Conversations
Jul 13, 2023



Applications that could benefit from automatic understanding of human-human conversations often come with challenges associated with private information in real-world data such as call center or clinical conversations. Working with protected data also increases costs of annotation, which limits technology development. To address these challenges, we propose DIALGEN, a human-in-the-loop semi-automated dialogue generation framework. DIALGEN uses a language model (ChatGPT) that can follow schema and style specifications to produce fluent conversational text, generating a complex conversation through iteratively generating subdialogues and using human feedback to correct inconsistencies or redirect the flow. In experiments on structured summarization of agent-client information gathering calls, framed as dialogue state tracking, we show that DIALGEN data enables significant improvement in model performance.
Unsupervised Learning of Hierarchical Conversation Structure
May 24, 2022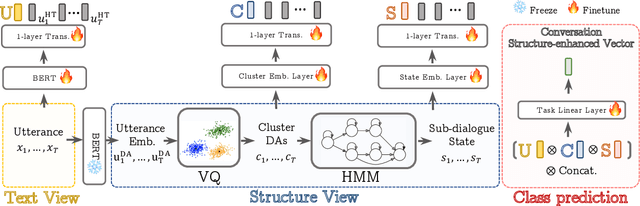
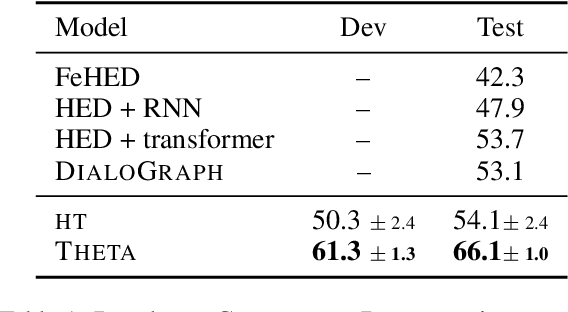
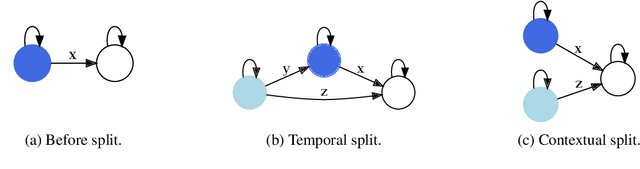
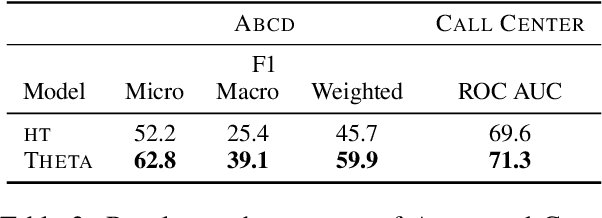
Human conversations can evolve in many different ways, creating challenges for automatic understanding and summarization. Goal-oriented conversations often have meaningful sub-dialogue structure, but it can be highly domain-dependent. This work introduces an unsupervised approach to learning hierarchical conversation structure, including turn and sub-dialogue segment labels, corresponding roughly to dialogue acts and sub-tasks, respectively. The decoded structure is shown to be useful in enhancing neural models of language for three conversation-level understanding tasks. Further, the learned finite-state sub-dialogue network is made interpretable through automatic summarization. Our code and trained models are available at \url{https://github.com/boru-roylu/THETA}.
DIALKI: Knowledge Identification in Conversational Systems through Dialogue-Document Contextualization
Sep 10, 2021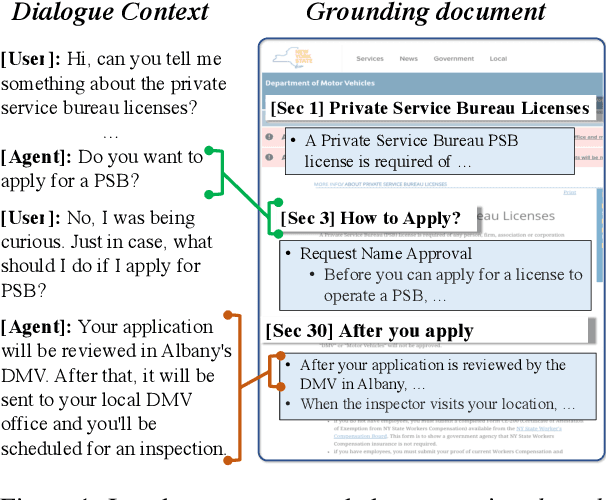

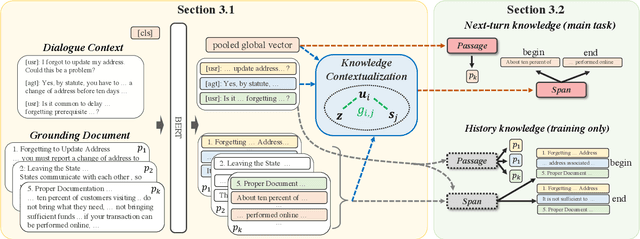
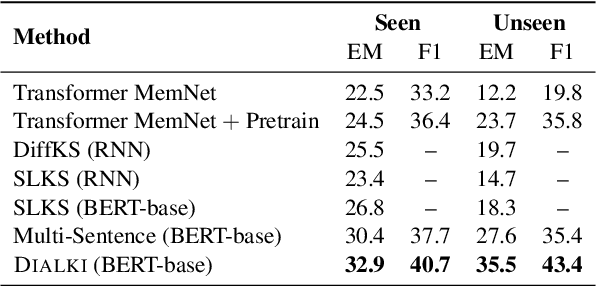
Identifying relevant knowledge to be used in conversational systems that are grounded in long documents is critical to effective response generation. We introduce a knowledge identification model that leverages the document structure to provide dialogue-contextualized passage encodings and better locate knowledge relevant to the conversation. An auxiliary loss captures the history of dialogue-document connections. We demonstrate the effectiveness of our model on two document-grounded conversational datasets and provide analyses showing generalization to unseen documents and long dialogue contexts.
Order-Preserving Abstractive Summarization for Spoken Content Based on Connectionist Temporal Classification
Nov 16, 2017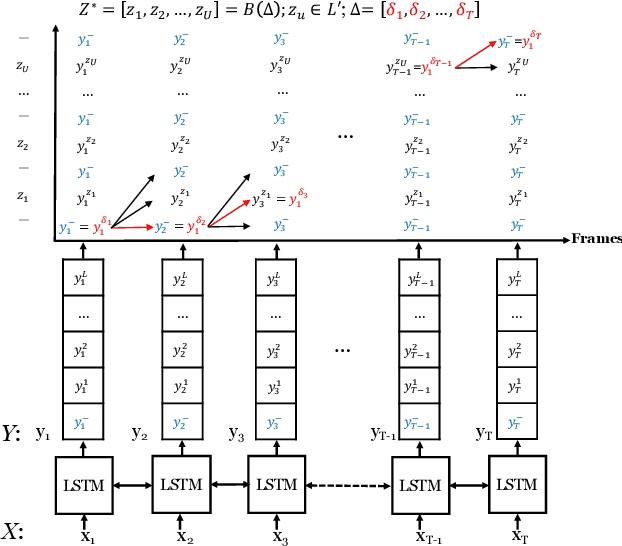

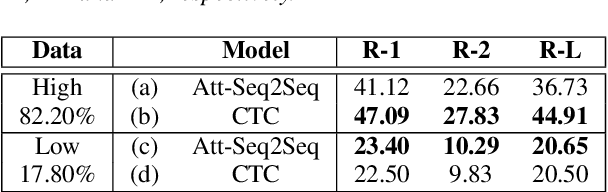
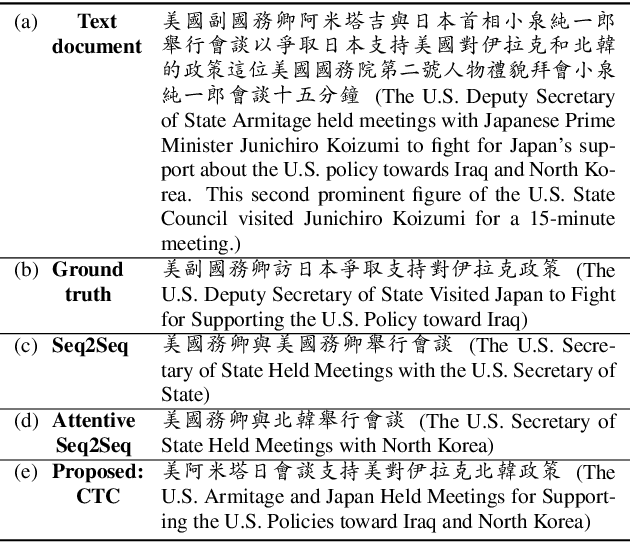
Connectionist temporal classification (CTC) is a powerful approach for sequence-to-sequence learning, and has been popularly used in speech recognition. The central ideas of CTC include adding a label "blank" during training. With this mechanism, CTC eliminates the need of segment alignment, and hence has been applied to various sequence-to-sequence learning problems. In this work, we applied CTC to abstractive summarization for spoken content. The "blank" in this case implies the corresponding input data are less important or noisy; thus it can be ignored. This approach was shown to outperform the existing methods in term of ROUGE scores over Chinese Gigaword and MATBN corpora. This approach also has the nice property that the ordering of words or characters in the input documents can be better preserved in the generated summaries.