 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaising the Stakes: Performance Pressure Improves AI-Assisted Decision Making
Oct 21, 2024

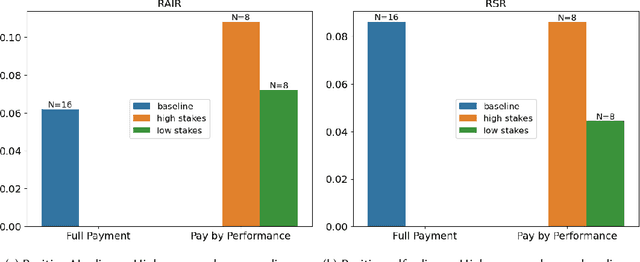

AI systems are used in many domains to assist with decision making, and although the potential for AI systems to assist with decision making is much discussed, human-AI collaboration often underperforms. Investigation into why the performance potential is not realized has revealed many factors, including (mis)trust in the AI system and mental models of AI capabilities on subjective tasks. Performance pressure is known to influence human decision making behavior, yet how it interacts with human-AI decision making is understudied. In this work, we show the effects of performance pressure on AI advice reliance when laypeople (Amazon Mechanical Turk crowdworkers) complete a common AI-assisted task (fake review detection) and thus have inherently low performance pressure. We manipulate performance pressure by leveraging people's loss aversion towards potential monetary gains when completing a task. We find that when the stakes are high, people use AI advice more appropriately than when stakes are lower, regardless of the presence of an AI explanation. Furthermore, when the AI system gives incorrect advice, people correctly discount the poor advice more often when the stakes are higher than when they are lower. We conclude by discussing the implications of how performance pressure influences AI-assisted decision making and encourage future research to incorporate performance pressure analysis.
Risks and NLP Design: A Case Study on Procedural Document QA
Aug 16, 2024As NLP systems are increasingly deployed at scale, concerns about their potential negative impacts have attracted the attention of the research community, yet discussions of risk have mostly been at an abstract level and focused on generic AI or NLP applications. We argue that clearer assessments of risks and harms to users--and concrete strategies to mitigate them--will be possible when we specialize the analysis to more concrete applications and their plausible users. As an illustration, this paper is grounded in cooking recipe procedural document question answering (ProcDocQA), where there are well-defined risks to users such as injuries or allergic reactions. Our case study shows that an existing language model, applied in "zero-shot" mode, quantitatively answers real-world questions about recipes as well or better than the humans who have answered the questions on the web. Using a novel questionnaire informed by theoretical work on AI risk, we conduct a risk-oriented error analysis that could then inform the design of a future system to be deployed with lower risk of harm and better performance.
Encode Once and Decode in Parallel: Efficient Transformer Decoding
Mar 19, 2024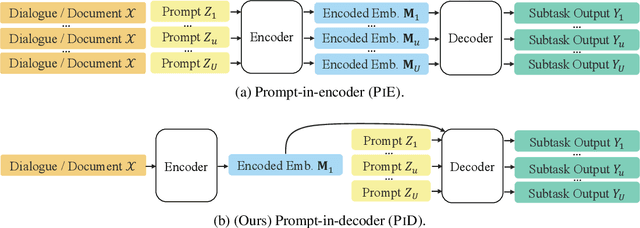

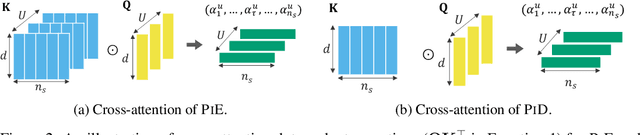
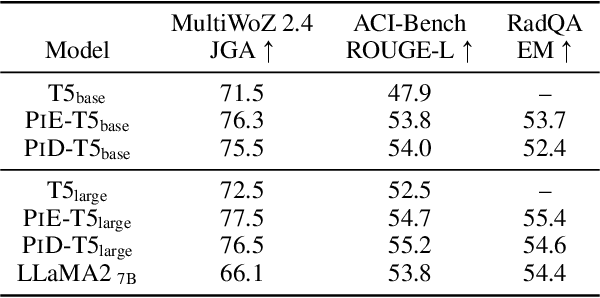
Transformer-based NLP models are powerful but have high computational costs that limit deployment scenarios. Finetuned encoder-decoder models are popular in specialized domains and can outperform larger more generalized decoder-only models, such as GPT-4. We introduce a new configuration for encoder-decoder models that improves efficiency on structured output and question-answering tasks where multiple outputs are required of a single input. Our method, prompt-in-decoder (PiD), encodes the input once and decodes output in parallel, boosting both training and inference efficiency by avoiding duplicate input encoding, thereby reducing the decoder's memory footprint. We achieve computation reduction that roughly scales with the number of subtasks, gaining up to 4.6x speed-up over state-of-the-art models for dialogue state tracking, summarization, and question-answering tasks with comparable or better performance. We release our training/inference code and checkpoints.
DIALGEN: Collaborative Human-LM Generated Dialogues for Improved Understanding of Human-Human Conversations
Jul 13, 2023



Applications that could benefit from automatic understanding of human-human conversations often come with challenges associated with private information in real-world data such as call center or clinical conversations. Working with protected data also increases costs of annotation, which limits technology development. To address these challenges, we propose DIALGEN, a human-in-the-loop semi-automated dialogue generation framework. DIALGEN uses a language model (ChatGPT) that can follow schema and style specifications to produce fluent conversational text, generating a complex conversation through iteratively generating subdialogues and using human feedback to correct inconsistencies or redirect the flow. In experiments on structured summarization of agent-client information gathering calls, framed as dialogue state tracking, we show that DIALGEN data enables significant improvement in model performance.
All That's 'Human' Is Not Gold: Evaluating Human Evaluation of Generated Text
Jul 07, 2021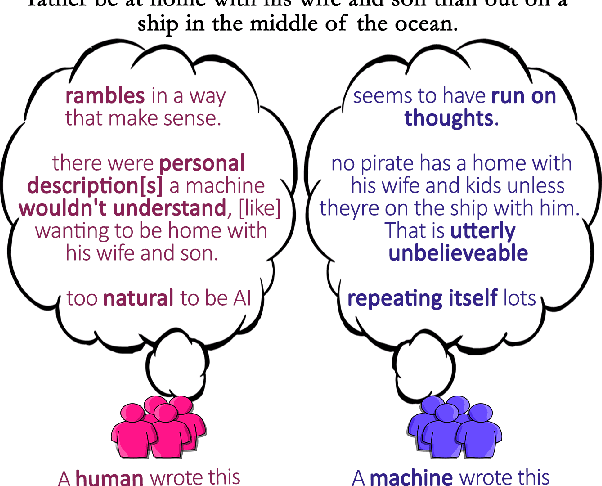
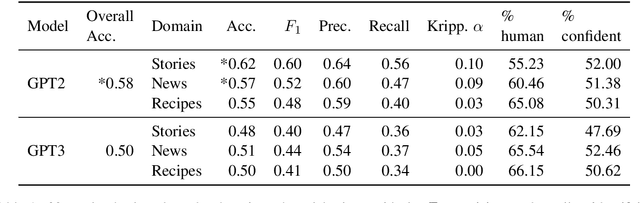

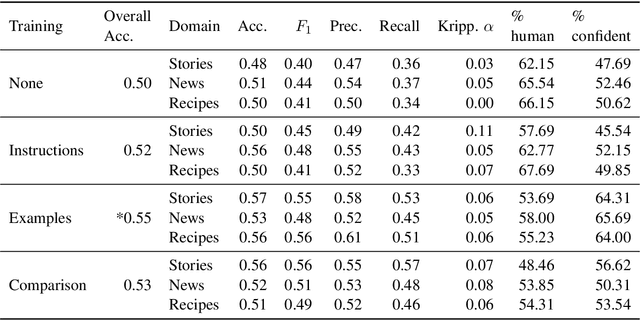
Human evaluations are typically considered the gold standard in natural language generation, but as models' fluency improves, how well can evaluators detect and judge machine-generated text? We run a study assessing non-experts' ability to distinguish between human- and machine-authored text (GPT2 and GPT3) in three domains (stories, news articles, and recipes). We find that, without training, evaluators distinguished between GPT3- and human-authored text at random chance level. We explore three approaches for quickly training evaluators to better identify GPT3-authored text (detailed instructions, annotated examples, and paired examples) and find that while evaluators' accuracy improved up to 55%, it did not significantly improve across the three domains. Given the inconsistent results across text domains and the often contradictory reasons evaluators gave for their judgments, we examine the role untrained human evaluations play in NLG evaluation and provide recommendations to NLG researchers for improving human evaluations of text generated from state-of-the-art models.