 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models: A Guide for the Perplexed
Nov 29, 2023

Given the growing importance of AI literacy, we decided to write this tutorial to help narrow the gap between the discourse among those who study language models -- the core technology underlying ChatGPT and similar products -- and those who are intrigued and want to learn more about them. In short, we believe the perspective of researchers and educators can add some clarity to the public's understanding of the technologies beyond what's currently available, which tends to be either extremely technical or promotional material generated about products by their purveyors. Our approach teases apart the concept of a language model from products built on them, from the behaviors attributed to or desired from those products, and from claims about similarity to human cognition. As a starting point, we (1) offer a scientific viewpoint that focuses on questions amenable to study through experimentation; (2) situate language models as they are today in the context of the research that led to their development; and (3) describe the boundaries of what is known about the models at this writing.
Stubborn Lexical Bias in Data and Models
Jun 03, 2023

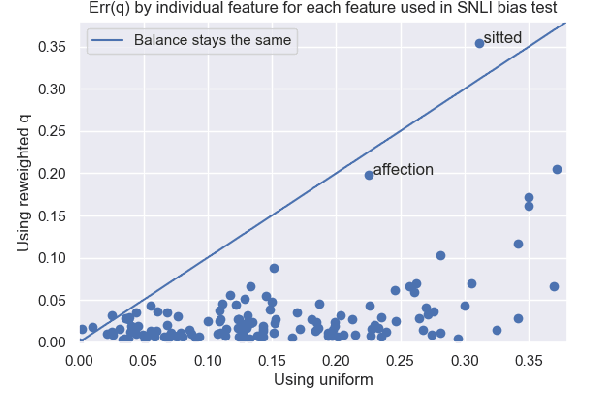

In NLP, recent work has seen increased focus on spurious correlations between various features and labels in training data, and how these influence model behavior. However, the presence and effect of such correlations are typically examined feature by feature. We investigate the cumulative impact on a model of many such intersecting features. Using a new statistical method, we examine whether such spurious patterns in data appear in models trained on the data. We select two tasks -- natural language inference and duplicate-question detection -- for which any unigram feature on its own should ideally be uninformative, which gives us a large pool of automatically extracted features with which to experiment. The large size of this pool allows us to investigate the intersection of features spuriously associated with (potentially different) labels. We then apply an optimization approach to *reweight* the training data, reducing thousands of spurious correlations, and examine how doing so affects models trained on the reweighted data. Surprisingly, though this method can successfully reduce lexical biases in the training data, we still find strong evidence of corresponding bias in the trained models, including worsened bias for slightly more complex features (bigrams). We close with discussion about the implications of our results on what it means to "debias" training data, and how issues of data quality can affect model bias.
All That's 'Human' Is Not Gold: Evaluating Human Evaluation of Generated Text
Jul 07, 2021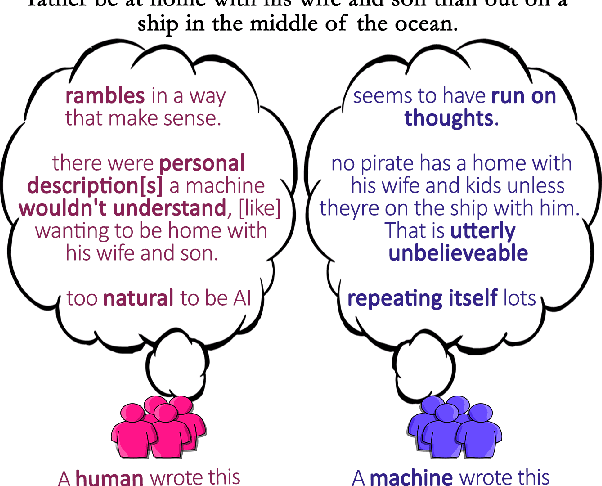
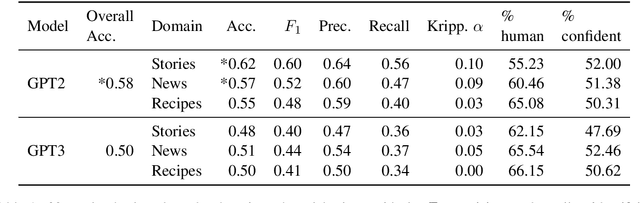

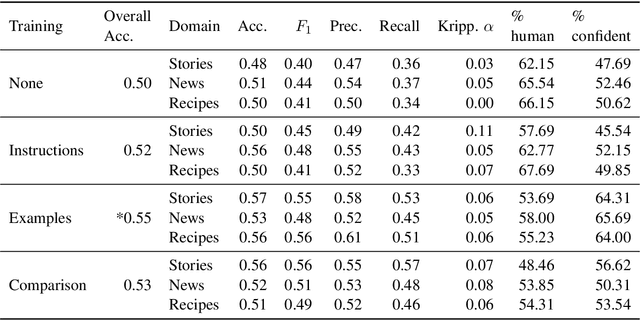
Human evaluations are typically considered the gold standard in natural language generation, but as models' fluency improves, how well can evaluators detect and judge machine-generated text? We run a study assessing non-experts' ability to distinguish between human- and machine-authored text (GPT2 and GPT3) in three domains (stories, news articles, and recipes). We find that, without training, evaluators distinguished between GPT3- and human-authored text at random chance level. We explore three approaches for quickly training evaluators to better identify GPT3-authored text (detailed instructions, annotated examples, and paired examples) and find that while evaluators' accuracy improved up to 55%, it did not significantly improve across the three domains. Given the inconsistent results across text domains and the often contradictory reasons evaluators gave for their judgments, we examine the role untrained human evaluations play in NLG evaluation and provide recommendations to NLG researchers for improving human evaluations of text generated from state-of-the-art models.
Is Attention Interpretable?
Jun 09, 2019

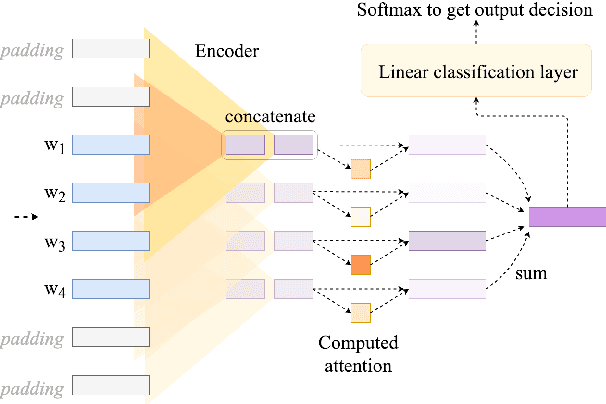

Attention mechanisms have recently boosted performance on a range of NLP tasks. Because attention layers explicitly weight input components' representations, it is also often assumed that attention can be used to identify information that models found important (e.g., specific contextualized word tokens). We test whether that assumption holds by manipulating attention weights in already-trained text classification models and analyzing the resulting differences in their predictions. While we observe some ways in which higher attention weights correlate with greater impact on model predictions, we also find many ways in which this does not hold, i.e., where gradient-based rankings of attention weights better predict their effects than their magnitudes. We conclude that while attention noisily predicts input components' overall importance to a model, it is by no means a fail-safe indicator.