 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Can Tell What I am Doing: Toward Real-World Natural Language Grounding of Robot Experiences
Nov 20, 2024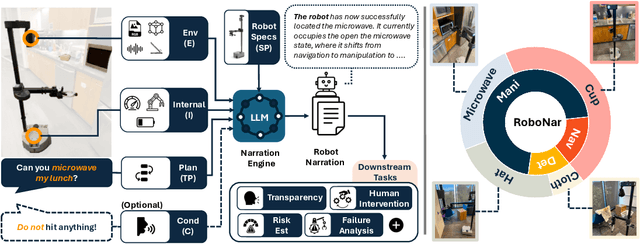
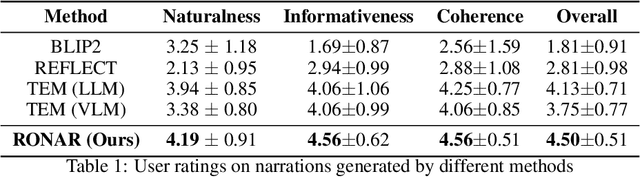
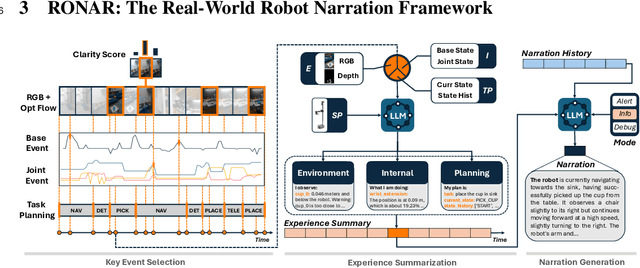
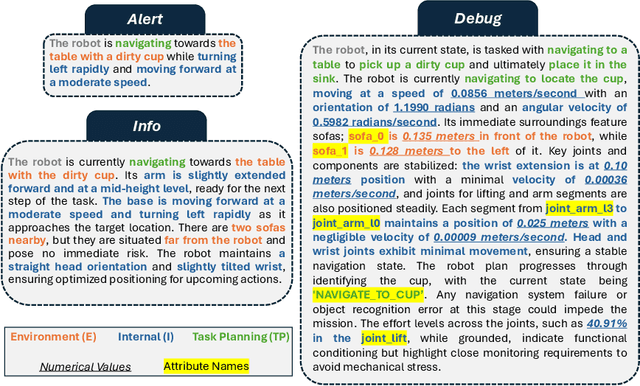
Understanding robot behaviors and experiences through natural language is crucial for developing intelligent and transparent robotic systems. Recent advancement in large language models (LLMs) makes it possible to translate complex, multi-modal robotic experiences into coherent, human-readable narratives. However, grounding real-world robot experiences into natural language is challenging due to many reasons, such as multi-modal nature of data, differing sample rates, and data volume. We introduce RONAR, an LLM-based system that generates natural language narrations from robot experiences, aiding in behavior announcement, failure analysis, and human interaction to recover failure. Evaluated across various scenarios, RONAR outperforms state-of-the-art methods and improves failure recovery efficiency. Our contributions include a multi-modal framework for robot experience narration, a comprehensive real-robot dataset, and empirical evidence of RONAR's effectiveness in enhancing user experience in system transparency and failure analysis.
Set the Clock: Temporal Alignment of Pretrained Language Models
Feb 26, 2024Language models (LMs) are trained on web text originating from many points in time and, in general, without any explicit temporal grounding. This work investigates the temporal chaos of pretrained LMs and explores various methods to align their internal knowledge to a target time, which we call "temporal alignment." To do this, we first automatically construct a dataset containing 20K time-sensitive questions and their answers for each year from 2000 to 2023. Based on this dataset, we empirically show that pretrained LMs (e.g., LLaMa2), despite having a recent pretraining cutoff (e.g., 2022), mostly answer questions using earlier knowledge (e.g., in 2019). We then develop several methods, from prompting to finetuning, to align LMs to use their most recent knowledge when answering questions, and investigate various factors in this alignment. Our experiments show that aligning LLaMa2 to the year 2022 can boost its performance by up to 62% relatively as measured by that year, even without mentioning time information explicitly, indicating the possibility of aligning models' internal sense of time after pretraining. Finally, we find that alignment to a historical time is also possible, with up to 2.8$\times$ the performance of the unaligned LM in 2010 if finetuning models to that year. These findings hint at the sophistication of LMs' internal knowledge organization and the necessity of tuning them properly.
Language Models: A Guide for the Perplexed
Nov 29, 2023

Given the growing importance of AI literacy, we decided to write this tutorial to help narrow the gap between the discourse among those who study language models -- the core technology underlying ChatGPT and similar products -- and those who are intrigued and want to learn more about them. In short, we believe the perspective of researchers and educators can add some clarity to the public's understanding of the technologies beyond what's currently available, which tends to be either extremely technical or promotional material generated about products by their purveyors. Our approach teases apart the concept of a language model from products built on them, from the behaviors attributed to or desired from those products, and from claims about similarity to human cognition. As a starting point, we (1) offer a scientific viewpoint that focuses on questions amenable to study through experimentation; (2) situate language models as they are today in the context of the research that led to their development; and (3) describe the boundaries of what is known about the models at this writing.