 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo to Video Generative Adversarial Network for Few-shot Learning Based on Policy Gradient
Oct 28, 2024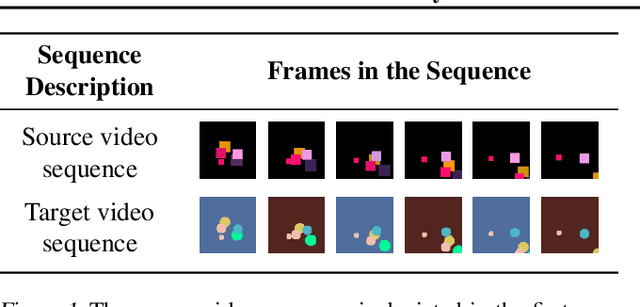
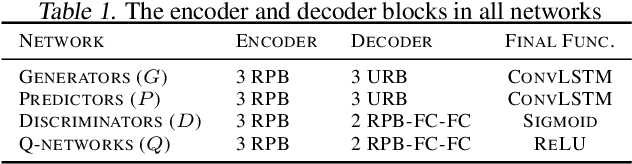
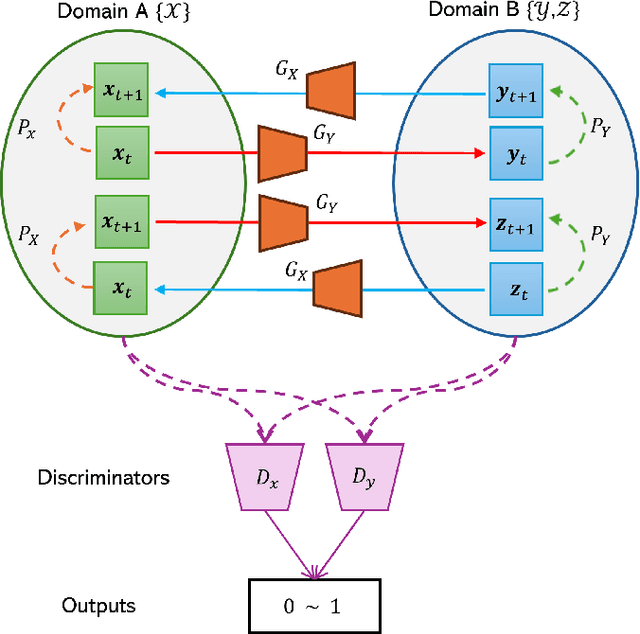
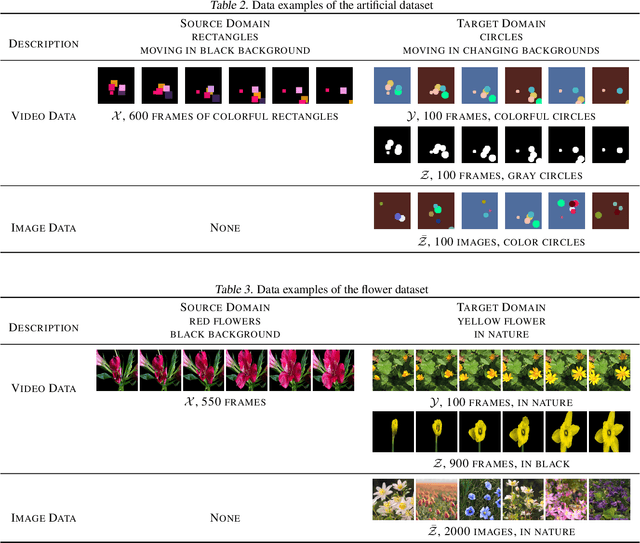
The development of sophisticated models for video-to-video synthesis has been facilitated by recent advances in deep reinforcement learning and generative adversarial networks (GANs). In this paper, we propose RL-V2V-GAN, a new deep neural network approach based on reinforcement learning for unsupervised conditional video-to-video synthesis. While preserving the unique style of the source video domain, our approach aims to learn a mapping from a source video domain to a target video domain. We train the model using policy gradient and employ ConvLSTM layers to capture the spatial and temporal information by designing a fine-grained GAN architecture and incorporating spatio-temporal adversarial goals. The adversarial losses aid in content translation while preserving style. Unlike traditional video-to-video synthesis methods requiring paired inputs, our proposed approach is more general because it does not require paired inputs. Thus, when dealing with limited videos in the target domain, i.e., few-shot learning, it is particularly effective. Our experiments show that RL-V2V-GAN can produce temporally coherent video results. These results highlight the potential of our approach for further advances in video-to-video synthesis.
Semi-supervised 3D Video Information Retrieval with Deep Neural Network and Bi-directional Dynamic-time Warping Algorithm
Sep 03, 2023
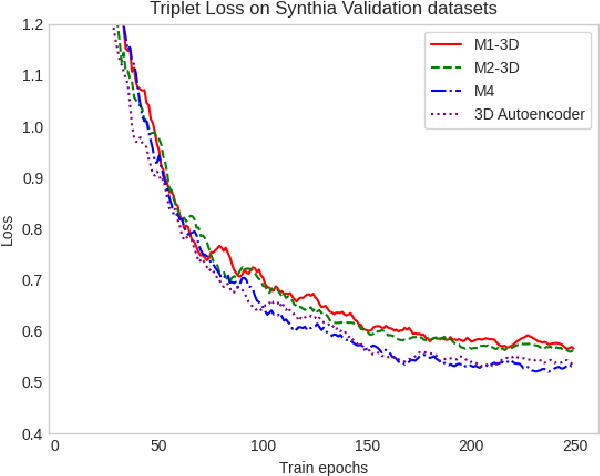


This paper presents a novel semi-supervised deep learning algorithm for retrieving similar 2D and 3D videos based on visual content. The proposed approach combines the power of deep convolutional and recurrent neural networks with dynamic time warping as a similarity measure. The proposed algorithm is designed to handle large video datasets and retrieve the most related videos to a given inquiry video clip based on its graphical frames and contents. We split both the candidate and the inquiry videos into a sequence of clips and convert each clip to a representation vector using an autoencoder-backed deep neural network. We then calculate a similarity measure between the sequences of embedding vectors using a bi-directional dynamic time-warping method. This approach is tested on multiple public datasets, including CC\_WEB\_VIDEO, Youtube-8m, S3DIS, and Synthia, and showed good results compared to state-of-the-art. The algorithm effectively solves video retrieval tasks and outperforms the benchmarked state-of-the-art deep learning model.
A Deep Value-network Based Approach for Multi-Driver Order Dispatching
Jun 08, 2021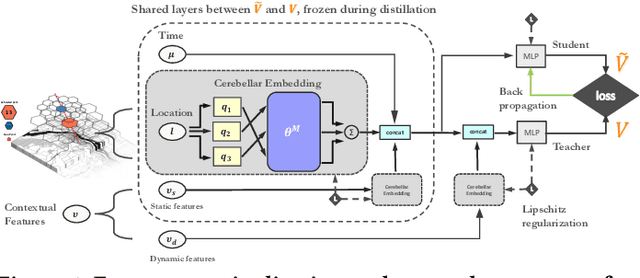
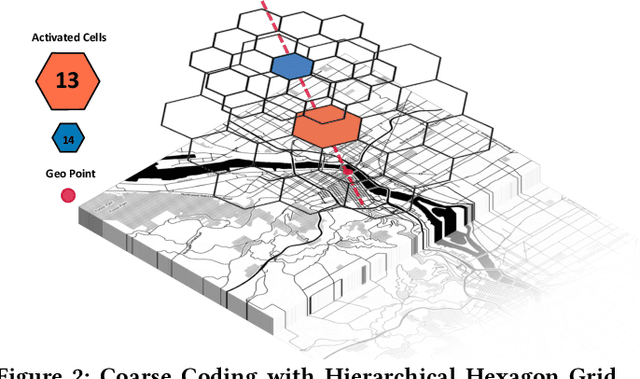
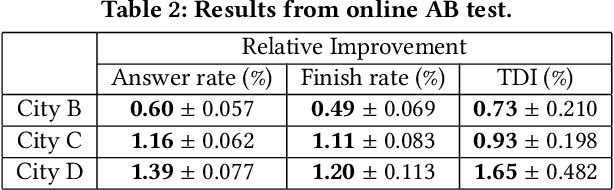
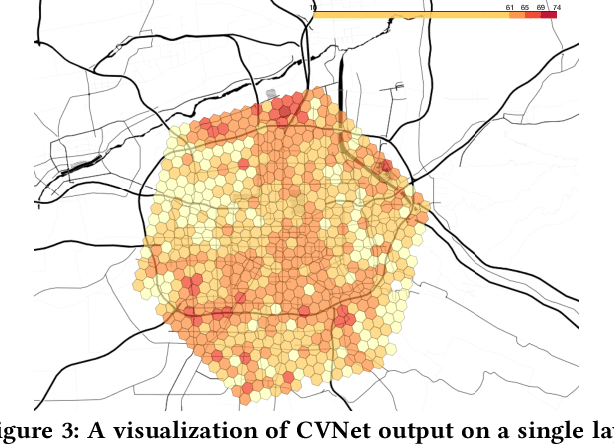
Recent works on ride-sharing order dispatching have highlighted the importance of taking into account both the spatial and temporal dynamics in the dispatching process for improving the transportation system efficiency. At the same time, deep reinforcement learning has advanced to the point where it achieves superhuman performance in a number of fields. In this work, we propose a deep reinforcement learning based solution for order dispatching and we conduct large scale online A/B tests on DiDi's ride-dispatching platform to show that the proposed method achieves significant improvement on both total driver income and user experience related metrics. In particular, we model the ride dispatching problem as a Semi Markov Decision Process to account for the temporal aspect of the dispatching actions. To improve the stability of the value iteration with nonlinear function approximators like neural networks, we propose Cerebellar Value Networks (CVNet) with a novel distributed state representation layer. We further derive a regularized policy evaluation scheme for CVNet that penalizes large Lipschitz constant of the value network for additional robustness against adversarial perturbation and noises. Finally, we adapt various transfer learning methods to CVNet for increased learning adaptability and efficiency across multiple cities. We conduct extensive offline simulations based on real dispatching data as well as online AB tests through the DiDi's platform. Results show that CVNet consistently outperforms other recently proposed dispatching methods. We finally show that the performance can be further improved through the efficient use of transfer learning.
Convergence Analysis of Batch Normalization for Deep Neural Nets
May 22, 2017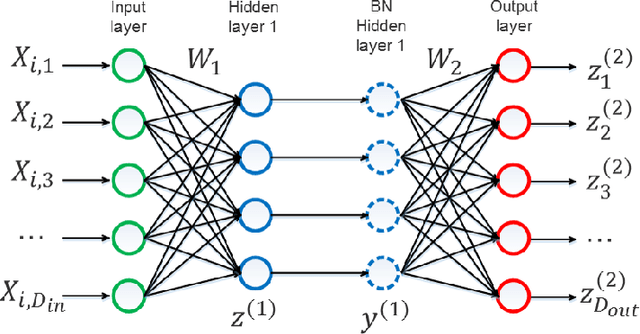
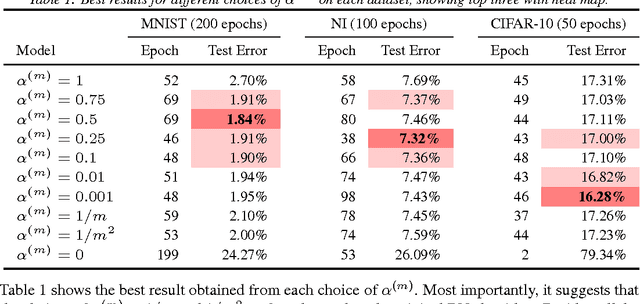
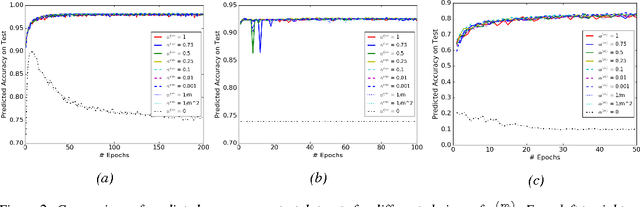
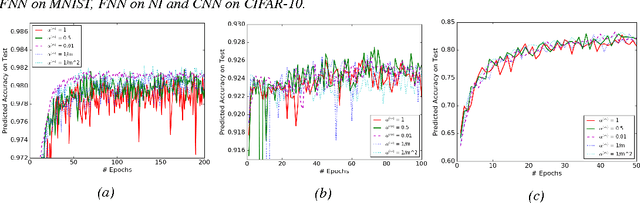
Batch normalization (BN) is very effective in accelerating the convergence of a neural network training phase that it has become a common practice. We propose a generalization of BN, the diminishing batch normalization (DBN) algorithm. We provide an analysis of the convergence of the DBN algorithm that converges to a stationary point with respect to trainable parameters. We analyze a two layer model with linear activation. The main challenge of the analysis is the fact that some parameters are updated by gradient while others are not. In the numerical experiments, we use models with more layers and ReLU activation. We observe that DBN outperforms the original BN algorithm on MNIST, NI and CIFAR-10 datasets with reasonable complex FNN and CNN models.