 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Classifying Multimodal Sequences
May 02, 2023Often pieces of information are received sequentially over time. When did one collect enough such pieces to classify? Trading wait time for decision certainty leads to early classification problems that have recently gained attention as a means of adapting classification to more dynamic environments. However, so far results have been limited to unimodal sequences. In this pilot study, we expand into early classifying multimodal sequences by combining existing methods. We show our new method yields experimental AUC advantages of up to 8.7%.
A Policy for Early Sequence Classification
Apr 07, 2023Sequences are often not received in their entirety at once, but instead, received incrementally over time, element by element. Early predictions yielding a higher benefit, one aims to classify a sequence as accurately as possible, as soon as possible, without having to wait for the last element. For this early sequence classification, we introduce our novel classifier-induced stopping. While previous methods depend on exploration during training to learn when to stop and classify, ours is a more direct, supervised approach. Our classifier-induced stopping achieves an average Pareto frontier AUC increase of 11.8% over multiple experiments.
Open-Set Recognition of Breast Cancer Treatments
Jan 09, 2022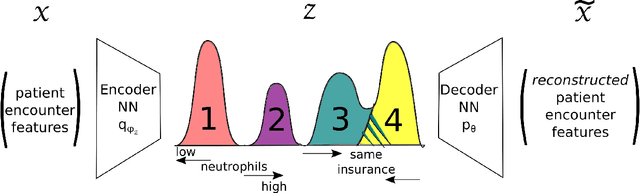

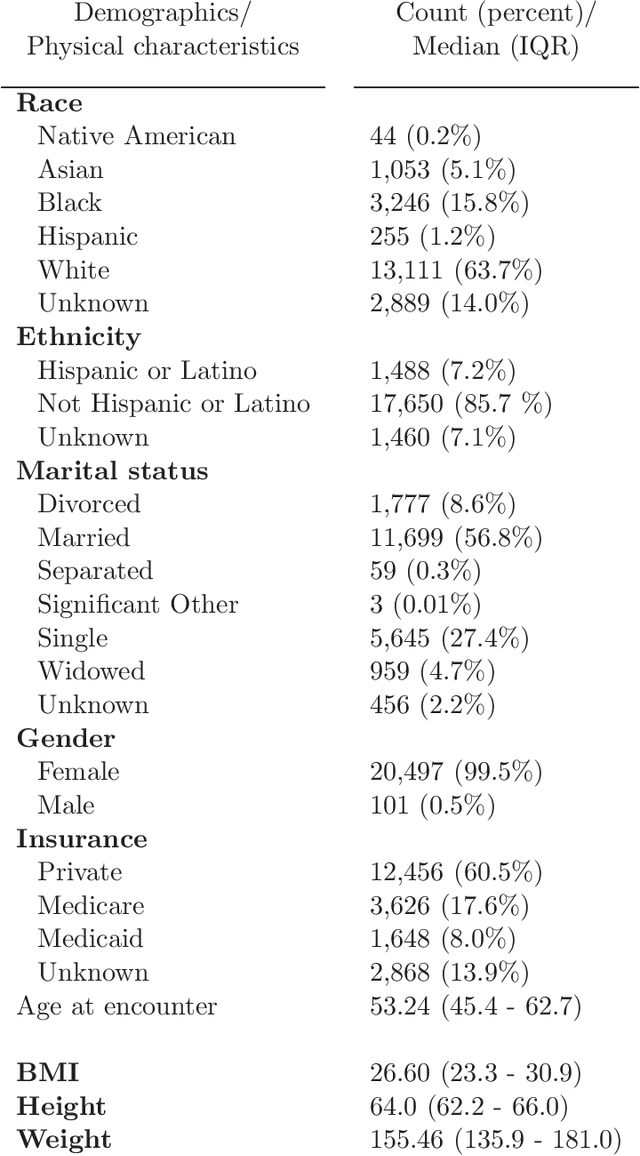
Open-set recognition generalizes a classification task by classifying test samples as one of the known classes from training or "unknown." As novel cancer drug cocktails with improved treatment are continually discovered, predicting cancer treatments can naturally be formulated in terms of an open-set recognition problem. Drawbacks, due to modeling unknown samples during training, arise from straightforward implementations of prior work in healthcare open-set learning. Accordingly, we reframe the problem methodology and apply a recent existing Gaussian mixture variational autoencoder model, which achieves state-of-the-art results for image datasets, to breast cancer patient data. Not only do we obtain more accurate and robust classification results, with a 24.5% average F1 increase compared to a recent method, but we also reexamine open-set recognition in terms of deployability to a clinical setting.
Open-Set Recognition with Gaussian Mixture Variational Autoencoders
Jun 03, 2020
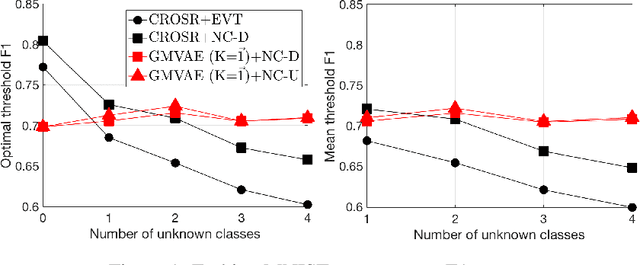
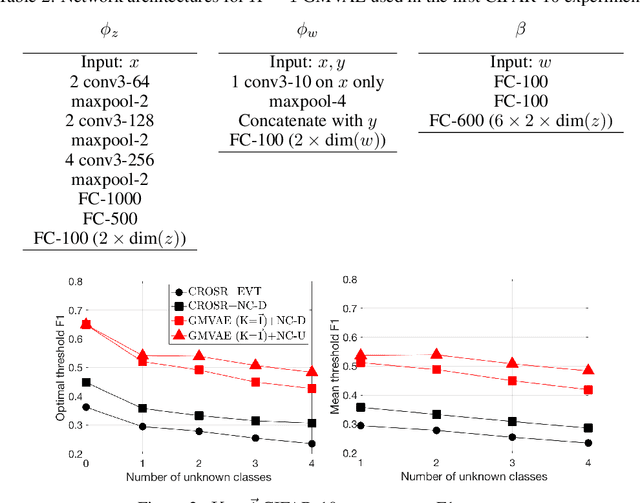
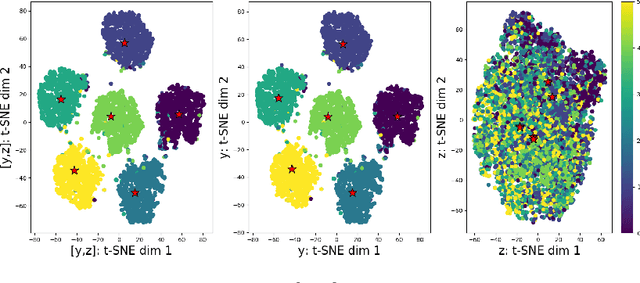
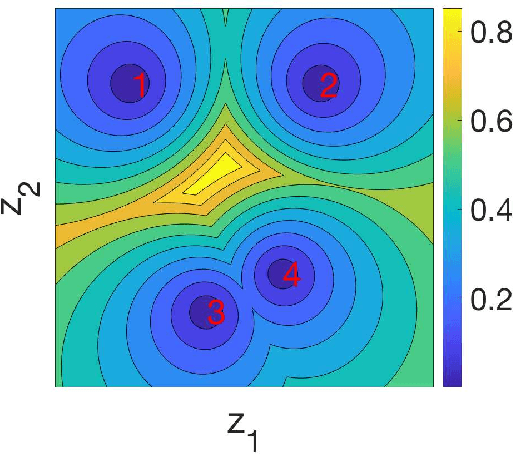
In inference, open-set classification is to either classify a sample into a known class from training or reject it as an unknown class. Existing deep open-set classifiers train explicit closed-set classifiers, in some cases disjointly utilizing reconstruction, which we find dilutes the latent representation's ability to distinguish unknown classes. In contrast, we train our model to cooperatively learn reconstruction and perform class-based clustering in the latent space. With this, our Gaussian mixture variational autoencoder (GMVAE) achieves more accurate and robust open-set classification results, with an average F1 improvement of 29.5%, through extensive experiments aided by analytical results.