 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Set Recognition of Breast Cancer Treatments
Paper and Code
Jan 09, 2022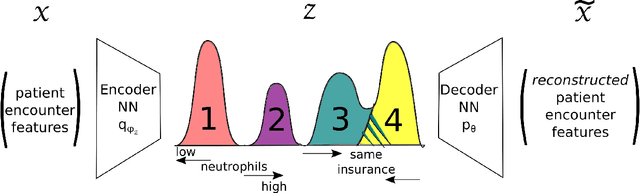

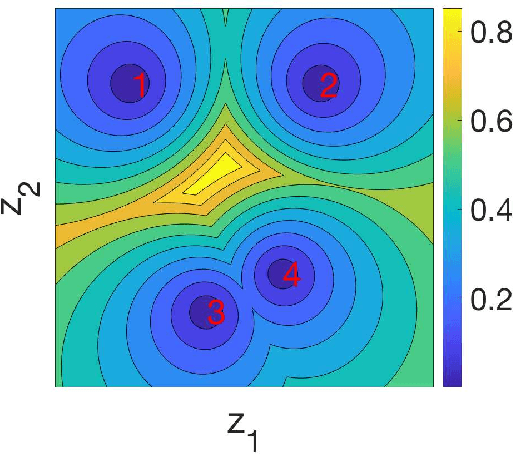
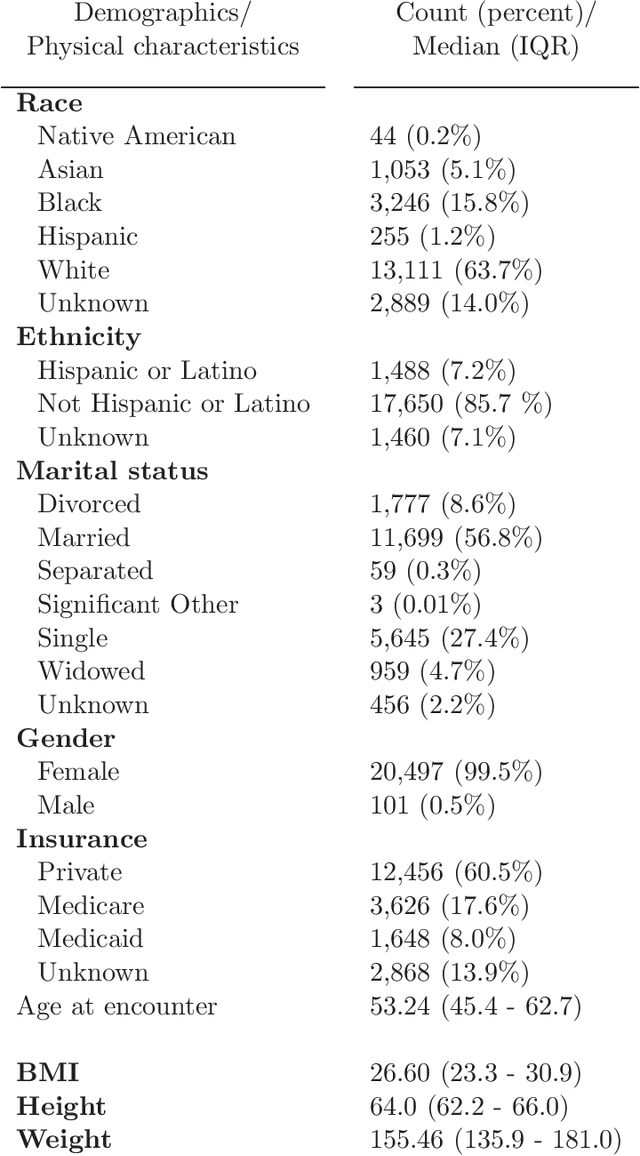
Open-set recognition generalizes a classification task by classifying test samples as one of the known classes from training or "unknown." As novel cancer drug cocktails with improved treatment are continually discovered, predicting cancer treatments can naturally be formulated in terms of an open-set recognition problem. Drawbacks, due to modeling unknown samples during training, arise from straightforward implementations of prior work in healthcare open-set learning. Accordingly, we reframe the problem methodology and apply a recent existing Gaussian mixture variational autoencoder model, which achieves state-of-the-art results for image datasets, to breast cancer patient data. Not only do we obtain more accurate and robust classification results, with a 24.5% average F1 increase compared to a recent method, but we also reexamine open-set recognition in terms of deployability to a clinical setting.