 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Encoders for Data-Efficient Imitation Learning in Modern Video Games
Dec 04, 2023Video games have served as useful benchmarks for the decision making community, but going beyond Atari games towards training agents in modern games has been prohibitively expensive for the vast majority of the research community. Recent progress in the research, development and open release of large vision models has the potential to amortize some of these costs across the community. However, it is currently unclear which of these models have learnt representations that retain information critical for sequential decision making. Towards enabling wider participation in the research of gameplaying agents in modern games, we present a systematic study of imitation learning with publicly available visual encoders compared to the typical, task-specific, end-to-end training approach in Minecraft, Minecraft Dungeons and Counter-Strike: Global Offensive.
Gradient-Boosted Based Structured and Unstructured Learning
Feb 28, 2023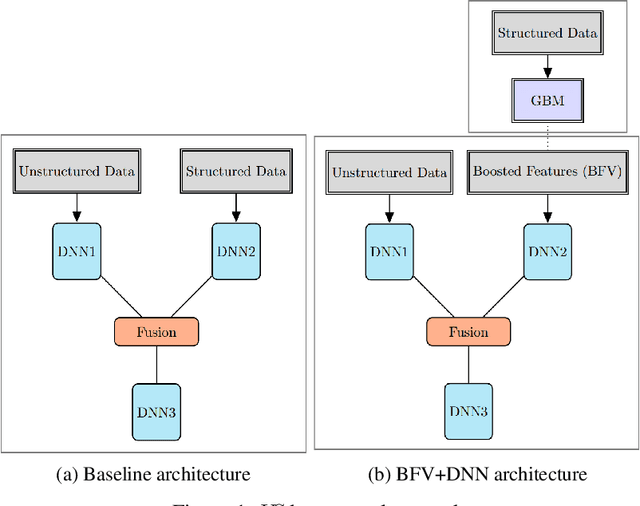
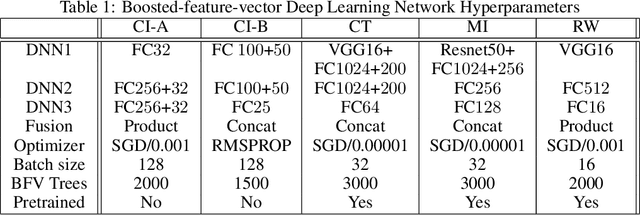
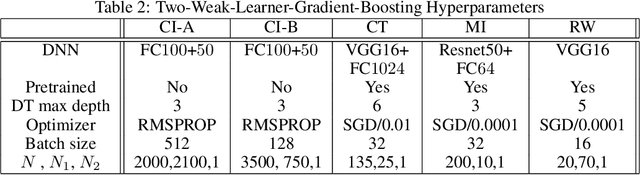
We propose two frameworks to deal with problem settings in which both structured and unstructured data are available. Structured data problems are best solved by traditional machine learning models such as boosting and tree-based algorithms, whereas deep learning has been widely applied to problems dealing with images, text, audio, and other unstructured data sources. However, for the setting in which both structured and unstructured data are accessible, it is not obvious what the best modeling approach is to enhance performance on both data sources simultaneously. Our proposed frameworks allow joint learning on both kinds of data by integrating the paradigms of boosting models and deep neural networks. The first framework, the boosted-feature-vector deep learning network, learns features from the structured data using gradient boosting and combines them with embeddings from unstructured data via a two-branch deep neural network. Secondly, the two-weak-learner boosting framework extends the boosting paradigm to the setting with two input data sources. We present and compare first- and second-order methods of this framework. Our experimental results on both public and real-world datasets show performance gains achieved by the frameworks over selected baselines by magnitudes of 0.1% - 4.7%.
Multi-Layer Attention-Based Explainability via Transformers for Tabular Data
Feb 28, 2023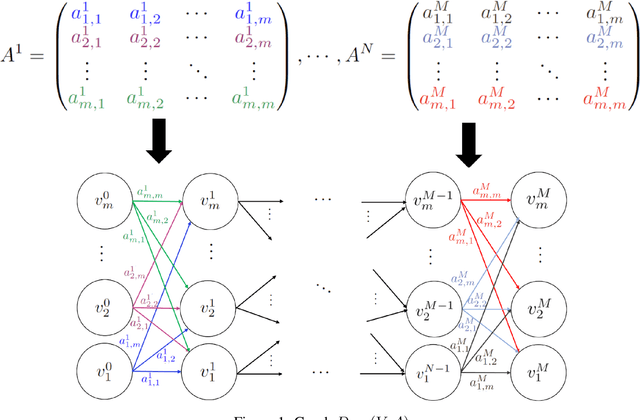
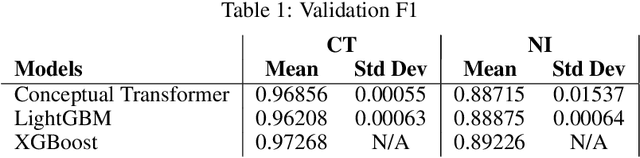
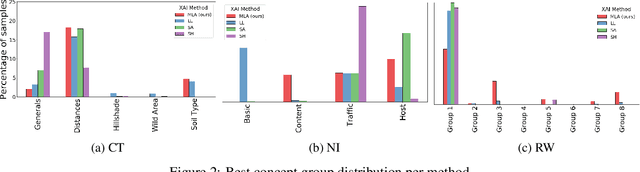
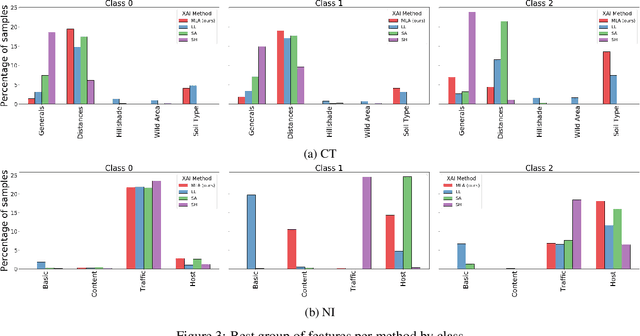
We propose a graph-oriented attention-based explainability method for tabular data. Tasks involving tabular data have been solved mostly using traditional tree-based machine learning models which have the challenges of feature selection and engineering. With that in mind, we consider a transformer architecture for tabular data, which is amenable to explainability, and present a novel way to leverage self-attention mechanism to provide explanations by taking into account the attention matrices of all layers as a whole. The matrices are mapped to a graph structure where groups of features correspond to nodes and attention values to arcs. By finding the maximum probability paths in the graph, we identify groups of features providing larger contributions to explain the model's predictions. To assess the quality of multi-layer attention-based explanations, we compare them with popular attention-, gradient-, and perturbation-based explanability methods.