 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Generate Reliable Test Case Generators? A Study on Competition-Level Programming Problems
Jun 07, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in code generation, capable of tackling complex tasks during inference. However, the extent to which LLMs can be utilized for code checking or debugging through test case generation remains largely unexplored. We investigate this problem from the perspective of competition-level programming (CP) programs and propose TCGBench, a Benchmark for (LLM generation of) Test Case Generators. This benchmark comprises two tasks, aimed at studying the capabilities of LLMs in (1) generating valid test case generators for a given CP problem, and further (2) generating targeted test case generators that expose bugs in human-written code. Experimental results indicate that while state-of-the-art LLMs can generate valid test case generators in most cases, most LLMs struggle to generate targeted test cases that reveal flaws in human code effectively. Especially, even advanced reasoning models (e.g., o3-mini) fall significantly short of human performance in the task of generating targeted generators. Furthermore, we construct a high-quality, manually curated dataset of instructions for generating targeted generators. Analysis demonstrates that the performance of LLMs can be enhanced with the aid of this dataset, by both prompting and fine-tuning.
Demonstrations of Integrity Attacks in Multi-Agent Systems
Jun 05, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in natural language understanding, code generation, and complex planning. Simultaneously, Multi-Agent Systems (MAS) have garnered attention for their potential to enable cooperation among distributed agents. However, from a multi-party perspective, MAS could be vulnerable to malicious agents that exploit the system to serve self-interests without disrupting its core functionality. This work explores integrity attacks where malicious agents employ subtle prompt manipulation to bias MAS operations and gain various benefits. Four types of attacks are examined: \textit{Scapegoater}, who misleads the system monitor to underestimate other agents' contributions; \textit{Boaster}, who misleads the system monitor to overestimate their own performance; \textit{Self-Dealer}, who manipulates other agents to adopt certain tools; and \textit{Free-Rider}, who hands off its own task to others. We demonstrate that strategically crafted prompts can introduce systematic biases in MAS behavior and executable instructions, enabling malicious agents to effectively mislead evaluation systems and manipulate collaborative agents. Furthermore, our attacks can bypass advanced LLM-based monitors, such as GPT-4o-mini and o3-mini, highlighting the limitations of current detection mechanisms. Our findings underscore the critical need for MAS architectures with robust security protocols and content validation mechanisms, alongside monitoring systems capable of comprehensive risk scenario assessment.
Aligning Agents like Large Language Models
Jun 06, 2024Training agents to behave as desired in complex 3D environments from high-dimensional sensory information is challenging. Imitation learning from diverse human behavior provides a scalable approach for training an agent with a sensible behavioral prior, but such an agent may not perform the specific behaviors of interest when deployed. To address this issue, we draw an analogy between the undesirable behaviors of imitation learning agents and the unhelpful responses of unaligned large language models (LLMs). We then investigate how the procedure for aligning LLMs can be applied to aligning agents in a 3D environment from pixels. For our analysis, we utilize an academically illustrative part of a modern console game in which the human behavior distribution is multi-modal, but we want our agent to imitate a single mode of this behavior. We demonstrate that we can align our agent to consistently perform the desired mode, while providing insights and advice for successfully applying this approach to training agents. Project webpage at https://adamjelley.github.io/aligning-agents-like-llms .
Visual Encoders for Data-Efficient Imitation Learning in Modern Video Games
Dec 04, 2023Video games have served as useful benchmarks for the decision making community, but going beyond Atari games towards training agents in modern games has been prohibitively expensive for the vast majority of the research community. Recent progress in the research, development and open release of large vision models has the potential to amortize some of these costs across the community. However, it is currently unclear which of these models have learnt representations that retain information critical for sequential decision making. Towards enabling wider participation in the research of gameplaying agents in modern games, we present a systematic study of imitation learning with publicly available visual encoders compared to the typical, task-specific, end-to-end training approach in Minecraft, Minecraft Dungeons and Counter-Strike: Global Offensive.
Temporal Graph Modeling for Skeleton-based Action Recognition
Dec 16, 2020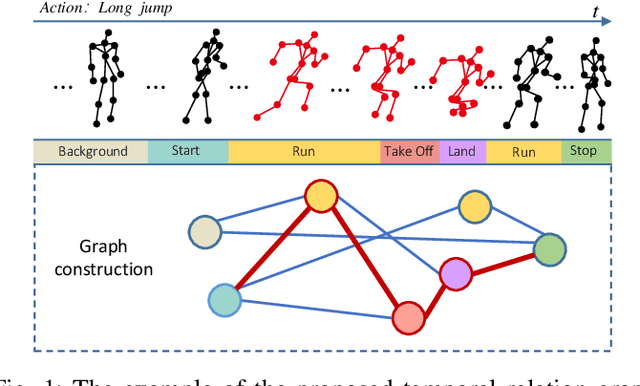
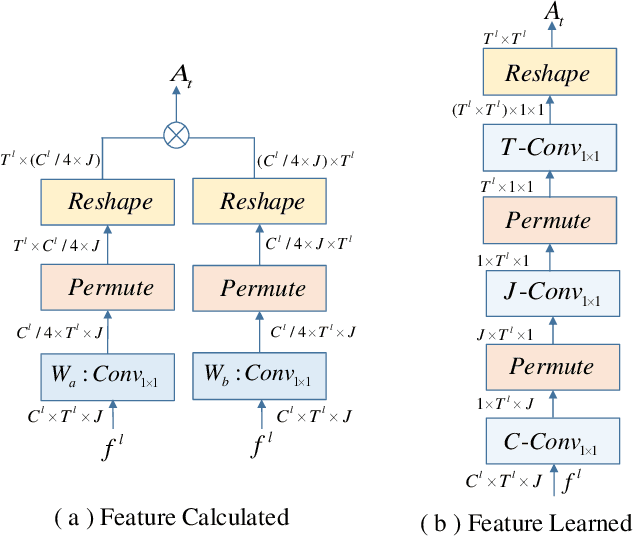
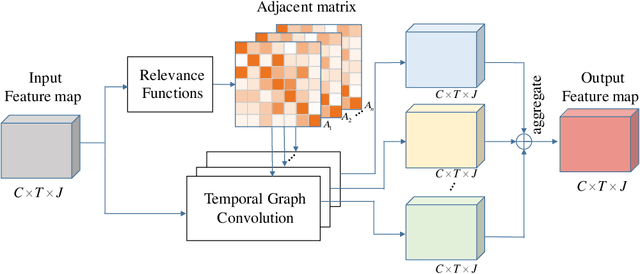
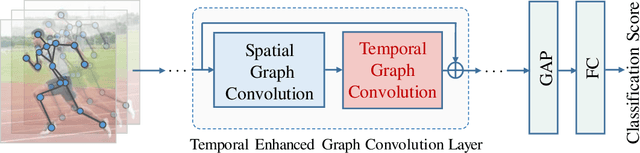
Graph Convolutional Networks (GCNs), which model skeleton data as graphs, have obtained remarkable performance for skeleton-based action recognition. Particularly, the temporal dynamic of skeleton sequence conveys significant information in the recognition task. For temporal dynamic modeling, GCN-based methods only stack multi-layer 1D local convolutions to extract temporal relations between adjacent time steps. With the repeat of a lot of local convolutions, the key temporal information with non-adjacent temporal distance may be ignored due to the information dilution. Therefore, these methods still remain unclear how to fully explore temporal dynamic of skeleton sequence. In this paper, we propose a Temporal Enhanced Graph Convolutional Network (TE-GCN) to tackle this limitation. The proposed TE-GCN constructs temporal relation graph to capture complex temporal dynamic. Specifically, the constructed temporal relation graph explicitly builds connections between semantically related temporal features to model temporal relations between both adjacent and non-adjacent time steps. Meanwhile, to further explore the sufficient temporal dynamic, multi-head mechanism is designed to investigate multi-kinds of temporal relations. Extensive experiments are performed on two widely used large-scale datasets, NTU-60 RGB+D and NTU-120 RGB+D. And experimental results show that the proposed model achieves the state-of-the-art performance by making contribution to temporal modeling for action recognition.