 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen does predictive inverse dynamics outperform behavior cloning?
Jan 29, 2026Behavior cloning (BC) is a practical offline imitation learning method, but it often fails when expert demonstrations are limited. Recent works have introduced a class of architectures named predictive inverse dynamics models (PIDM) that combine a future state predictor with an inverse dynamics model (IDM). While PIDM often outperforms BC, the reasons behind its benefits remain unclear. In this paper, we provide a theoretical explanation: PIDM introduces a bias-variance tradeoff. While predicting the future state introduces bias, conditioning the IDM on the prediction can significantly reduce variance. We establish conditions on the state predictor bias for PIDM to achieve lower prediction error and higher sample efficiency than BC, with the gap widening when additional data sources are available. We validate the theoretical insights empirically in 2D navigation tasks, where BC requires up to five times (three times on average) more demonstrations than PIDM to reach comparable performance; and in a complex 3D environment in a modern video game with high-dimensional visual inputs and stochastic transitions, where BC requires over 66\% more samples than PIDM.
Safe Reinforcement Learning using Action Projection: Safeguard the Policy or the Environment?
Sep 16, 2025Projection-based safety filters, which modify unsafe actions by mapping them to the closest safe alternative, are widely used to enforce safety constraints in reinforcement learning (RL). Two integration strategies are commonly considered: Safe environment RL (SE-RL), where the safeguard is treated as part of the environment, and safe policy RL (SP-RL), where it is embedded within the policy through differentiable optimization layers. Despite their practical relevance in safety-critical settings, a formal understanding of their differences is lacking. In this work, we present a theoretical comparison of SE-RL and SP-RL. We identify a key distinction in how each approach is affected by action aliasing, a phenomenon in which multiple unsafe actions are projected to the same safe action, causing information loss in the policy gradients. In SE-RL, this effect is implicitly approximated by the critic, while in SP-RL, it manifests directly as rank-deficient Jacobians during backpropagation through the safeguard. Our contributions are threefold: (i) a unified formalization of SE-RL and SP-RL in the context of actor-critic algorithms, (ii) a theoretical analysis of their respective policy gradient estimates, highlighting the role of action aliasing, and (iii) a comparative study of mitigation strategies, including a novel penalty-based improvement for SP-RL that aligns with established SE-RL practices. Empirical results support our theoretical predictions, showing that action aliasing is more detrimental for SP-RL than for SE-RL. However, with appropriate improvement strategies, SP-RL can match or outperform improved SE-RL across a range of environments. These findings provide actionable insights for choosing and refining projection-based safe RL methods based on task characteristics.
Visual Encoders for Data-Efficient Imitation Learning in Modern Video Games
Dec 04, 2023Video games have served as useful benchmarks for the decision making community, but going beyond Atari games towards training agents in modern games has been prohibitively expensive for the vast majority of the research community. Recent progress in the research, development and open release of large vision models has the potential to amortize some of these costs across the community. However, it is currently unclear which of these models have learnt representations that retain information critical for sequential decision making. Towards enabling wider participation in the research of gameplaying agents in modern games, we present a systematic study of imitation learning with publicly available visual encoders compared to the typical, task-specific, end-to-end training approach in Minecraft, Minecraft Dungeons and Counter-Strike: Global Offensive.
Using Offline Data to Speed-up Reinforcement Learning in Procedurally Generated Environments
Apr 18, 2023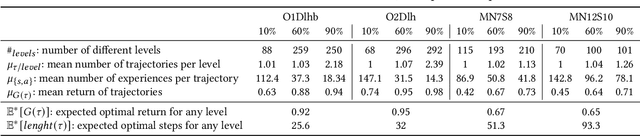
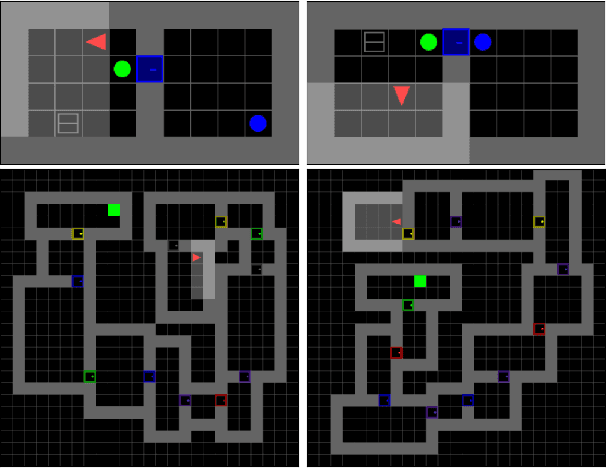
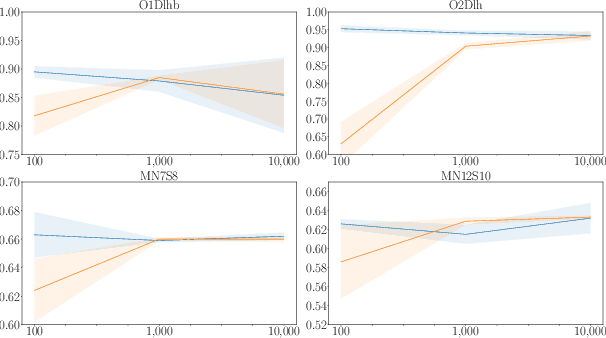
One of the key challenges of Reinforcement Learning (RL) is the ability of agents to generalise their learned policy to unseen settings. Moreover, training RL agents requires large numbers of interactions with the environment. Motivated by the recent success of Offline RL and Imitation Learning (IL), we conduct a study to investigate whether agents can leverage offline data in the form of trajectories to improve the sample-efficiency in procedurally generated environments. We consider two settings of using IL from offline data for RL: (1) pre-training a policy before online RL training and (2) concurrently training a policy with online RL and IL from offline data. We analyse the impact of the quality (optimality of trajectories) and diversity (number of trajectories and covered level) of available offline trajectories on the effectiveness of both approaches. Across four well-known sparse reward tasks in the MiniGrid environment, we find that using IL for pre-training and concurrently during online RL training both consistently improve the sample-efficiency while converging to optimal policies. Furthermore, we show that pre-training a policy from as few as two trajectories can make the difference between learning an optimal policy at the end of online training and not learning at all. Our findings motivate the widespread adoption of IL for pre-training and concurrent IL in procedurally generated environments whenever offline trajectories are available or can be generated.
Ensemble Value Functions for Efficient Exploration in Multi-Agent Reinforcement Learning
Mar 02, 2023



Cooperative multi-agent reinforcement learning (MARL) requires agents to explore to learn to cooperate. Existing value-based MARL algorithms commonly rely on random exploration, such as $\epsilon$-greedy, which is inefficient in discovering multi-agent cooperation. Additionally, the environment in MARL appears non-stationary to any individual agent due to the simultaneous training of other agents, leading to highly variant and thus unstable optimisation signals. In this work, we propose ensemble value functions for multi-agent exploration (EMAX), a general framework to extend any value-based MARL algorithm. EMAX trains ensembles of value functions for each agent to address the key challenges of exploration and non-stationarity: (1) The uncertainty of value estimates across the ensemble is used in a UCB policy to guide the exploration of agents to parts of the environment which require cooperation. (2) Average value estimates across the ensemble serve as target values. These targets exhibit lower variance compared to commonly applied target networks and we show that they lead to more stable gradients during the optimisation. We instantiate three value-based MARL algorithms with EMAX, independent DQN, VDN and QMIX, and evaluate them in 21 tasks across four environments. Using ensembles of five value functions, EMAX improves sample efficiency and final evaluation returns of these algorithms by 54%, 55%, and 844%, respectively, averaged all 21 tasks.
Scalable Multi-Agent Reinforcement Learning for Warehouse Logistics with Robotic and Human Co-Workers
Dec 22, 2022
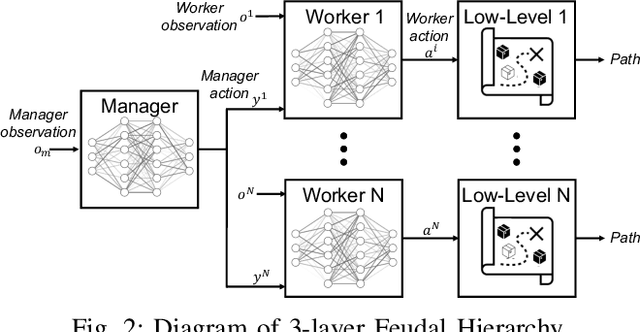
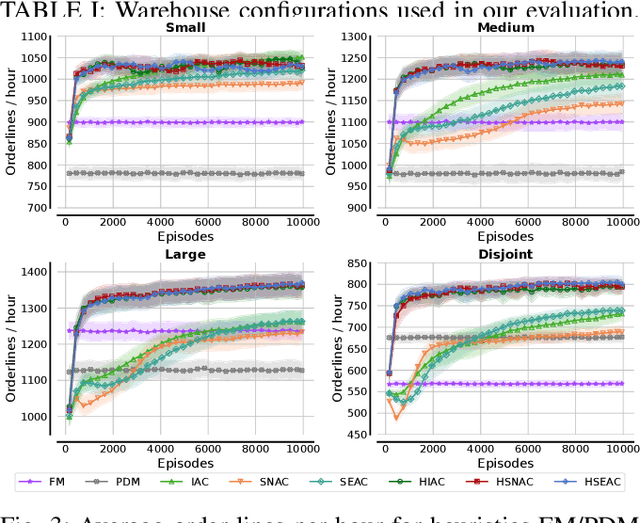
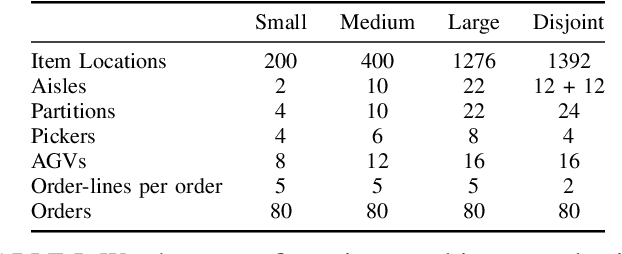
This project leverages advances in multi-agent reinforcement learning (MARL) to improve the efficiency and flexibility of order-picking systems for commercial warehouses. We envision a warehouse of the future in which dozens of mobile robots and human pickers work together to collect and deliver items within the warehouse. The fundamental problem we tackle, called the order-picking problem, is how these worker agents must coordinate their movement and actions in the warehouse to maximise performance (e.g. order throughput) under given resource constraints. Established industry methods using heuristic approaches require large engineering efforts to optimise for innately variable warehouse configurations. In contrast, the MARL framework can be flexibly applied to any warehouse configuration (e.g. size, layout, number/types of workers, item replenishment frequency) and the agents learn via a process of trial-and-error how to optimally cooperate with one another. This paper details the current status of the R&D effort initiated by Dematic and the University of Edinburgh towards a general-purpose and scalable MARL solution for the order-picking problem in realistic warehouses.
Deep Reinforcement Learning for Multi-Agent Interaction
Aug 02, 2022The development of autonomous agents which can interact with other agents to accomplish a given task is a core area of research in artificial intelligence and machine learning. Towards this goal, the Autonomous Agents Research Group develops novel machine learning algorithms for autonomous systems control, with a specific focus on deep reinforcement learning and multi-agent reinforcement learning. Research problems include scalable learning of coordinated agent policies and inter-agent communication; reasoning about the behaviours, goals, and composition of other agents from limited observations; and sample-efficient learning based on intrinsic motivation, curriculum learning, causal inference, and representation learning. This article provides a broad overview of the ongoing research portfolio of the group and discusses open problems for future directions.
Learning Task Embeddings for Teamwork Adaptation in Multi-Agent Reinforcement Learning
Jul 05, 2022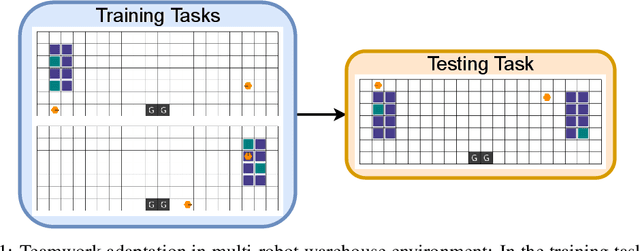
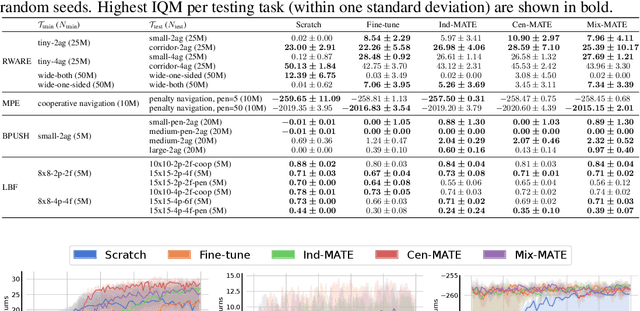
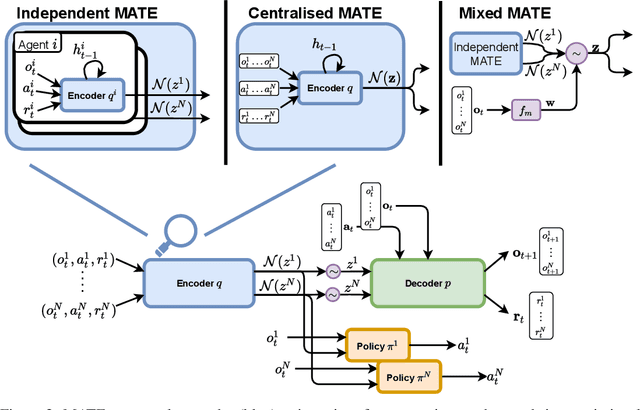
Successful deployment of multi-agent reinforcement learning often requires agents to adapt their behaviour. In this work, we discuss the problem of teamwork adaptation in which a team of agents needs to adapt their policies to solve novel tasks with limited fine-tuning. Motivated by the intuition that agents need to be able to identify and distinguish tasks in order to adapt their behaviour to the current task, we propose to learn multi-agent task embeddings (MATE). These task embeddings are trained using an encoder-decoder architecture optimised for reconstruction of the transition and reward functions which uniquely identify tasks. We show that a team of agents is able to adapt to novel tasks when provided with task embeddings. We propose three MATE training paradigms: independent MATE, centralised MATE, and mixed MATE which vary in the information used for the task encoding. We show that the embeddings learned by MATE identify tasks and provide useful information which agents leverage during adaptation to novel tasks.
Learning Representations for Control with Hierarchical Forward Models
Jun 22, 2022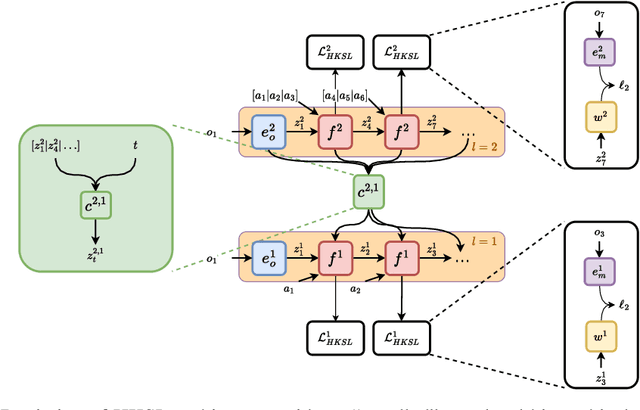
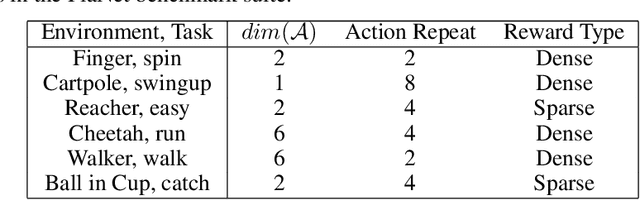
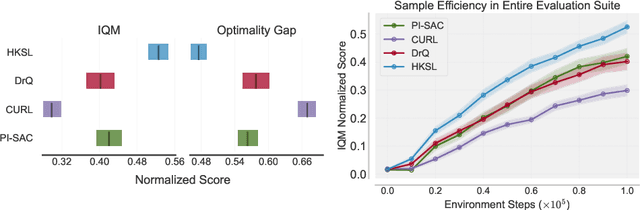

Learning control from pixels is difficult for reinforcement learning (RL) agents because representation learning and policy learning are intertwined. Previous approaches remedy this issue with auxiliary representation learning tasks, but they either do not consider the temporal aspect of the problem or only consider single-step transitions. Instead, we propose Hierarchical $k$-Step Latent (HKSL), an auxiliary task that learns representations via a hierarchy of forward models that operate at varying magnitudes of step skipping while also learning to communicate between levels in the hierarchy. We evaluate HKSL in a suite of 30 robotic control tasks and find that HKSL either reaches higher episodic returns or converges to maximum performance more quickly than several current baselines. Also, we find that levels in HKSL's hierarchy can learn to specialize in long- or short-term consequences of agent actions, thereby providing the downstream control policy with more informative representations. Finally, we determine that communication channels between hierarchy levels organize information based on both sides of the communication process, which improves sample efficiency.
Robust On-Policy Data Collection for Data-Efficient Policy Evaluation
Nov 29, 2021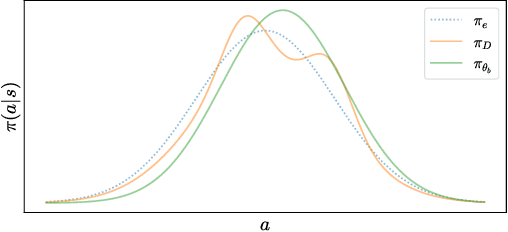

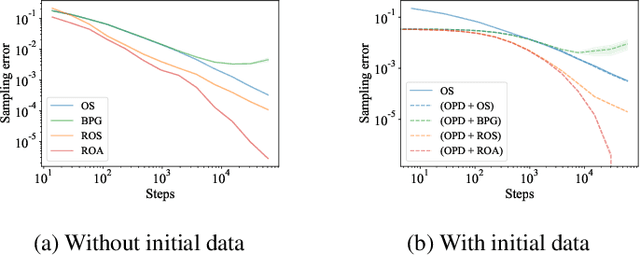
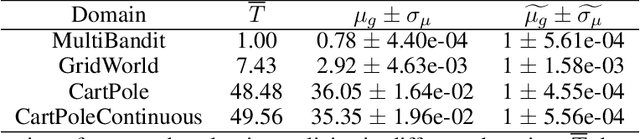
This paper considers how to complement offline reinforcement learning (RL) data with additional data collection for the task of policy evaluation. In policy evaluation, the task is to estimate the expected return of an evaluation policy on an environment of interest. Prior work on offline policy evaluation typically only considers a static dataset. We consider a setting where we can collect a small amount of additional data to combine with a potentially larger offline RL dataset. We show that simply running the evaluation policy -- on-policy data collection -- is sub-optimal for this setting. We then introduce two new data collection strategies for policy evaluation, both of which consider previously collected data when collecting future data so as to reduce distribution shift (or sampling error) in the entire dataset collected. Our empirical results show that compared to on-policy sampling, our strategies produce data with lower sampling error and generally lead to lower mean-squared error in policy evaluation for any total dataset size. We also show that these strategies can start from initial off-policy data, collect additional data, and then use both the initial and new data to produce low mean-squared error policy evaluation without using off-policy corrections.