 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Policy Learning for 6-DOF Position Control of Underwater Vehicles
Dec 15, 2025Autonomous Underwater Vehicles (AUVs) require reliable six-degree-of-freedom (6-DOF) position control to operate effectively in complex and dynamic marine environments. Traditional controllers are effective under nominal conditions but exhibit degraded performance when faced with unmodeled dynamics or environmental disturbances. Reinforcement learning (RL) provides a powerful alternative but training is typically slow and sim-to-real transfer remains challenging. This work introduces a GPU-accelerated RL training pipeline built in JAX and MuJoCo-XLA (MJX). By jointly JIT-compiling large-scale parallel physics simulation and learning updates, we achieve training times of under two minutes.Through systematic evaluation of multiple RL algorithms, we show robust 6-DOF trajectory tracking and effective disturbance rejection in real underwater experiments, with policies transferred zero-shot from simulation. Our results provide the first explicit real-world demonstration of RL-based AUV position control across all six degrees of freedom.
On the Inherent Robustness of One-Stage Object Detection against Out-of-Distribution Data
Nov 07, 2024



Robustness is a fundamental aspect for developing safe and trustworthy models, particularly when they are deployed in the open world. In this work we analyze the inherent capability of one-stage object detectors to robustly operate in the presence of out-of-distribution (OoD) data. Specifically, we propose a novel detection algorithm for detecting unknown objects in image data, which leverages the features extracted by the model from each sample. Differently from other recent approaches in the literature, our proposal does not require retraining the object detector, thereby allowing for the use of pretrained models. Our proposed OoD detector exploits the application of supervised dimensionality reduction techniques to mitigate the effects of the curse of dimensionality on the features extracted by the model. Furthermore, it utilizes high-resolution feature maps to identify potential unknown objects in an unsupervised fashion. Our experiments analyze the Pareto trade-off between the performance detecting known and unknown objects resulting from different algorithmic configurations and inference confidence thresholds. We also compare the performance of our proposed algorithm to that of logits-based post-hoc OoD methods, as well as possible fusion strategies. Finally, we discuss on the competitiveness of all tested methods against state-of-the-art OoD approaches for object detection models over the recently published Unknown Object Detection benchmark. The obtained results verify that the performance of avant-garde post-hoc OoD detectors can be further improved when combined with our proposed algorithm.
On the Black-box Explainability of Object Detection Models for Safe and Trustworthy Industrial Applications
Oct 28, 2024



In the realm of human-machine interaction, artificial intelligence has become a powerful tool for accelerating data modeling tasks. Object detection methods have achieved outstanding results and are widely used in critical domains like autonomous driving and video surveillance. However, their adoption in high-risk applications, where errors may cause severe consequences, remains limited. Explainable Artificial Intelligence (XAI) methods aim to address this issue, but many existing techniques are model-specific and designed for classification tasks, making them less effective for object detection and difficult for non-specialists to interpret. In this work we focus on model-agnostic XAI methods for object detection models and propose D-MFPP, an extension of the Morphological Fragmental Perturbation Pyramid (MFPP), which uses segmentation-based mask generation. Additionally, we introduce D-Deletion, a novel metric combining faithfulness and localization, adapted specifically to meet the unique demands of object detectors. We evaluate these methods on real-world industrial and robotic datasets, examining the influence of parameters such as the number of masks, model size, and image resolution on the quality of explanations. Our experiments use single-stage object detection models applied to two safety-critical robotic environments: i) a shared human-robot workspace where safety is of paramount importance, and ii) an assembly area of battery kits, where safety is critical due to the potential for damage among high-risk components. Our findings evince that D-Deletion effectively gauges the performance of explanations when multiple elements of the same class appear in the same scene, while D-MFPP provides a promising alternative to D-RISE when fewer masks are used.
Words as Beacons: Guiding RL Agents with High-Level Language Prompts
Oct 11, 2024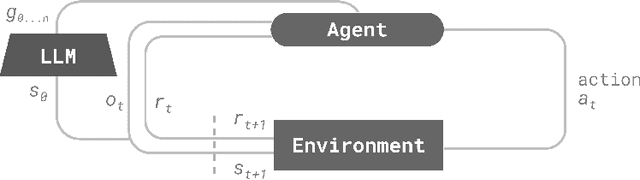

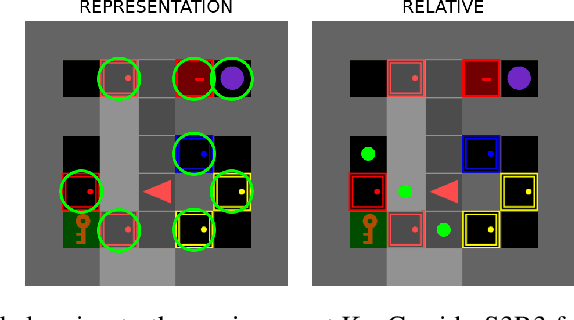
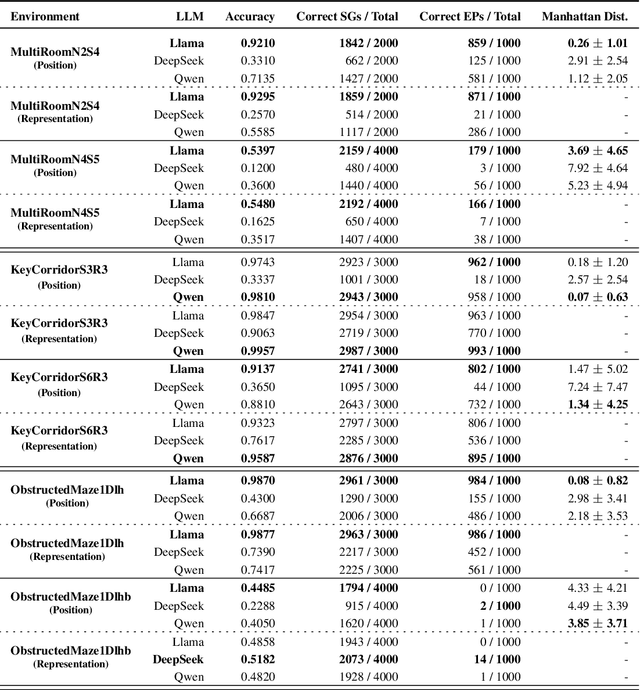
Sparse reward environments in reinforcement learning (RL) pose significant challenges for exploration, often leading to inefficient or incomplete learning processes. To tackle this issue, this work proposes a teacher-student RL framework that leverages Large Language Models (LLMs) as "teachers" to guide the agent's learning process by decomposing complex tasks into subgoals. Due to their inherent capability to understand RL environments based on a textual description of structure and purpose, LLMs can provide subgoals to accomplish the task defined for the environment in a similar fashion to how a human would do. In doing so, three types of subgoals are proposed: positional targets relative to the agent, object representations, and language-based instructions generated directly by the LLM. More importantly, we show that it is possible to query the LLM only during the training phase, enabling agents to operate within the environment without any LLM intervention. We assess the performance of this proposed framework by evaluating three state-of-the-art open-source LLMs (Llama, DeepSeek, Qwen) eliciting subgoals across various procedurally generated environment of the MiniGrid benchmark. Experimental results demonstrate that this curriculum-based approach accelerates learning and enhances exploration in complex tasks, achieving up to 30 to 200 times faster convergence in training steps compared to recent baselines designed for sparse reward environments.
Fostering Intrinsic Motivation in Reinforcement Learning with Pretrained Foundation Models
Oct 09, 2024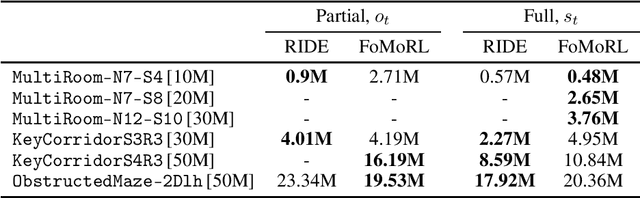

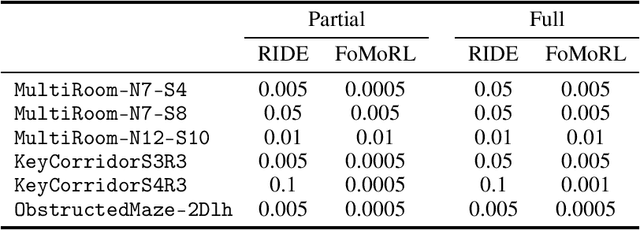

Exploration remains a significant challenge in reinforcement learning, especially in environments where extrinsic rewards are sparse or non-existent. The recent rise of foundation models, such as CLIP, offers an opportunity to leverage pretrained, semantically rich embeddings that encapsulate broad and reusable knowledge. In this work we explore the potential of these foundation models not just to drive exploration, but also to analyze the critical role of the episodic novelty term in enhancing exploration effectiveness of the agent. We also investigate whether providing the intrinsic module with complete state information -- rather than just partial observations -- can improve exploration, despite the difficulties in handling small variations within large state spaces. Our experiments in the MiniGrid domain reveal that intrinsic modules can effectively utilize full state information, significantly increasing sample efficiency while learning an optimal policy. Moreover, we show that the embeddings provided by foundation models are sometimes even better than those constructed by the agent during training, further accelerating the learning process, especially when coupled with the episodic novelty term to enhance exploration.
Surgical Task Automation Using Actor-Critic Frameworks and Self-Supervised Imitation Learning
Sep 04, 2024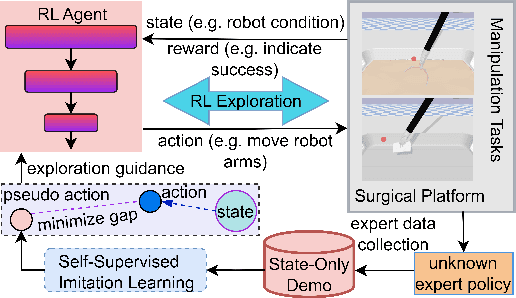
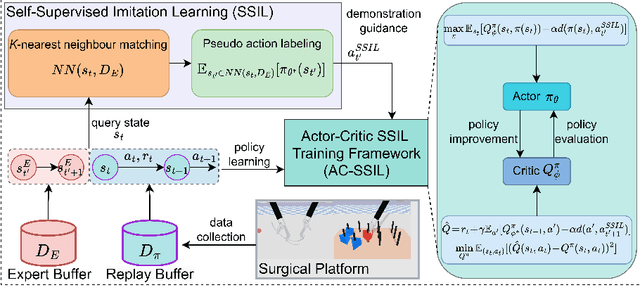
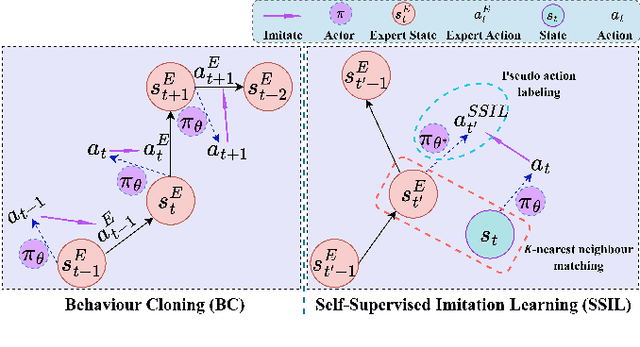
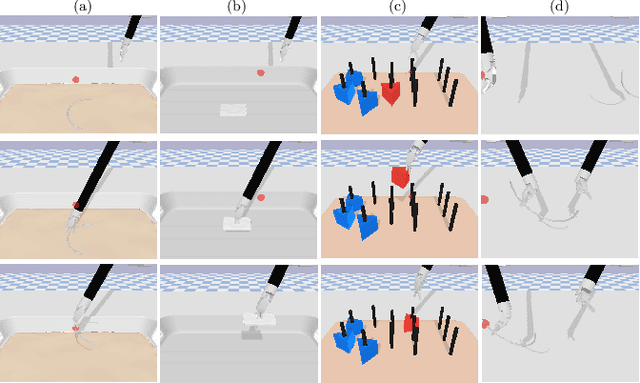
Surgical robot task automation has recently attracted great attention due to its potential to benefit both surgeons and patients. Reinforcement learning (RL) based approaches have demonstrated promising ability to provide solutions to automated surgical manipulations on various tasks. To address the exploration challenge, expert demonstrations can be utilized to enhance the learning efficiency via imitation learning (IL) approaches. However, the successes of such methods normally rely on both states and action labels. Unfortunately action labels can be hard to capture or their manual annotation is prohibitively expensive owing to the requirement for expert knowledge. It therefore remains an appealing and open problem to leverage expert demonstrations composed of pure states in RL. In this work, we present an actor-critic RL framework, termed AC-SSIL, to overcome this challenge of learning with state-only demonstrations collected by following an unknown expert policy. It adopts a self-supervised IL method, dubbed SSIL, to effectively incorporate demonstrated states into RL paradigms by retrieving from demonstrates the nearest neighbours of the query state and utilizing the bootstrapping of actor networks. We showcase through experiments on an open-source surgical simulation platform that our method delivers remarkable improvements over the RL baseline and exhibits comparable performance against action based IL methods, which implies the efficacy and potential of our method for expert demonstration-guided learning scenarios.
Enhanced Generalization through Prioritization and Diversity in Self-Imitation Reinforcement Learning over Procedural Environments with Sparse Rewards
Nov 01, 2023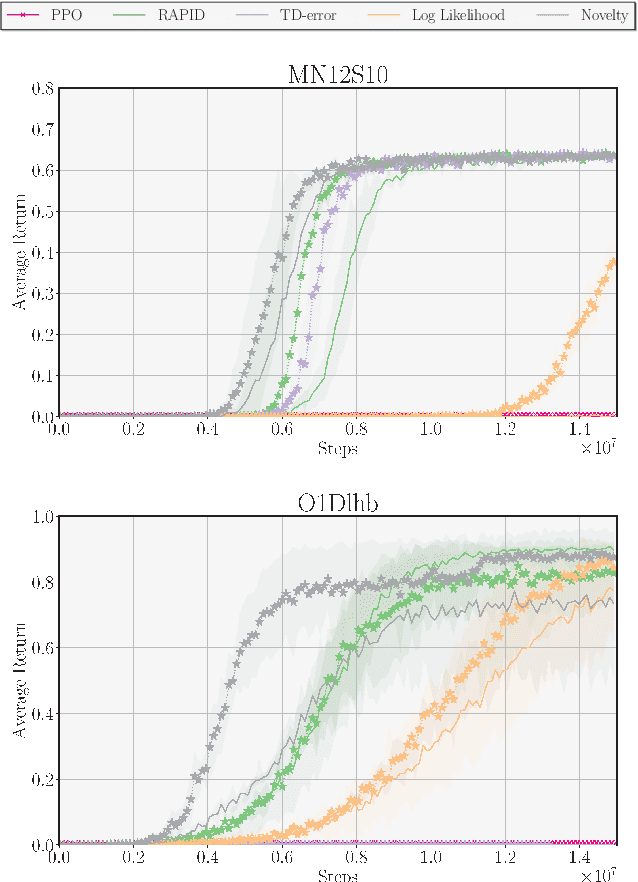
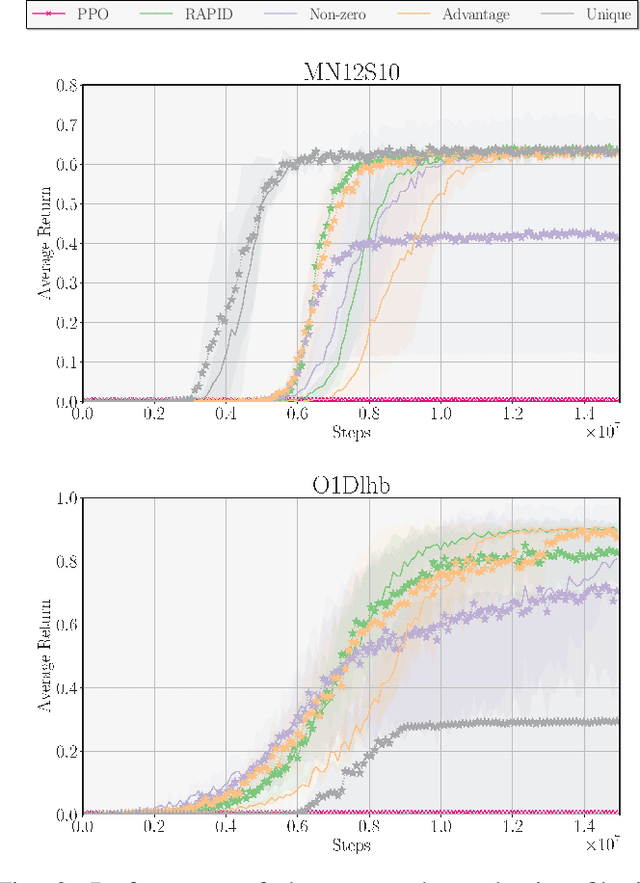

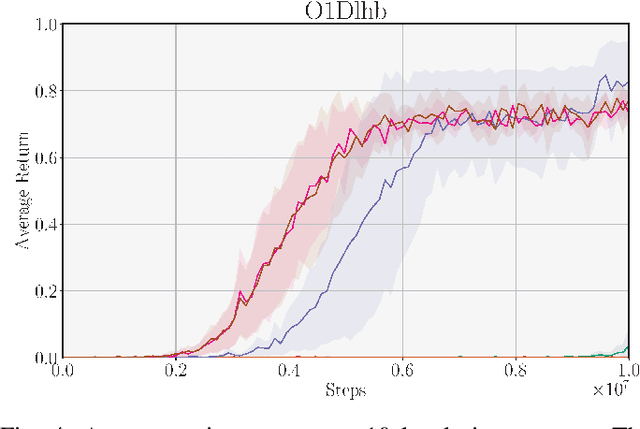
Exploration poses a fundamental challenge in Reinforcement Learning (RL) with sparse rewards, limiting an agent's ability to learn optimal decision-making due to a lack of informative feedback signals. Self-Imitation Learning (self-IL) has emerged as a promising approach for exploration, leveraging a replay buffer to store and reproduce successful behaviors. However, traditional self-IL methods, which rely on high-return transitions and assume singleton environments, face challenges in generalization, especially in procedurally-generated (PCG) environments. Therefore, new self-IL methods have been proposed to rank which experiences to persist, but they replay transitions uniformly regardless of their significance, and do not address the diversity of the stored demonstrations. In this work, we propose tailored self-IL sampling strategies by prioritizing transitions in different ways and extending prioritization techniques to PCG environments. We also address diversity loss through modifications to counteract the impact of generalization requirements and bias introduced by prioritization techniques. Our experimental analysis, conducted over three PCG sparse reward environments, including MiniGrid and ProcGen, highlights the benefits of our proposed modifications, achieving a new state-of-the-art performance in the MiniGrid-MultiRoom-N12-S10 environment.
Using Offline Data to Speed-up Reinforcement Learning in Procedurally Generated Environments
Apr 18, 2023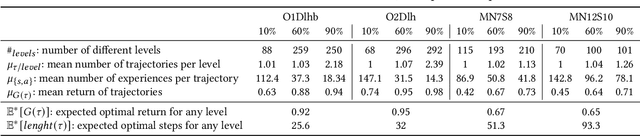
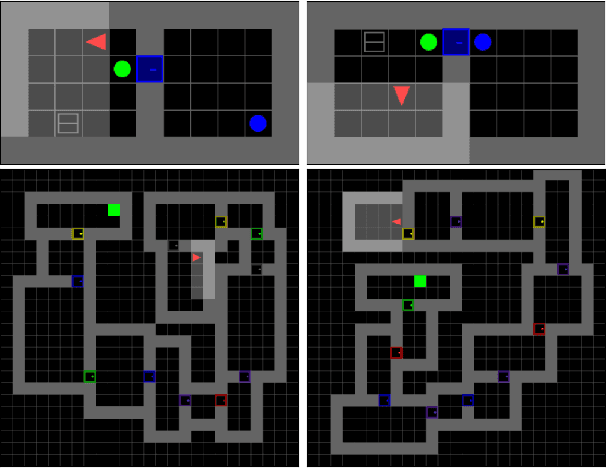
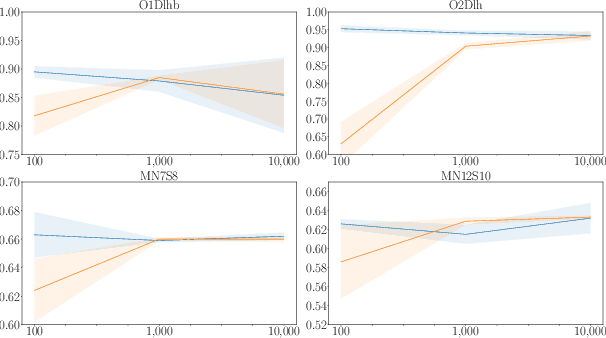
One of the key challenges of Reinforcement Learning (RL) is the ability of agents to generalise their learned policy to unseen settings. Moreover, training RL agents requires large numbers of interactions with the environment. Motivated by the recent success of Offline RL and Imitation Learning (IL), we conduct a study to investigate whether agents can leverage offline data in the form of trajectories to improve the sample-efficiency in procedurally generated environments. We consider two settings of using IL from offline data for RL: (1) pre-training a policy before online RL training and (2) concurrently training a policy with online RL and IL from offline data. We analyse the impact of the quality (optimality of trajectories) and diversity (number of trajectories and covered level) of available offline trajectories on the effectiveness of both approaches. Across four well-known sparse reward tasks in the MiniGrid environment, we find that using IL for pre-training and concurrently during online RL training both consistently improve the sample-efficiency while converging to optimal policies. Furthermore, we show that pre-training a policy from as few as two trajectories can make the difference between learning an optimal policy at the end of online training and not learning at all. Our findings motivate the widespread adoption of IL for pre-training and concurrent IL in procedurally generated environments whenever offline trajectories are available or can be generated.
Towards Improving Exploration in Self-Imitation Learning using Intrinsic Motivation
Nov 30, 2022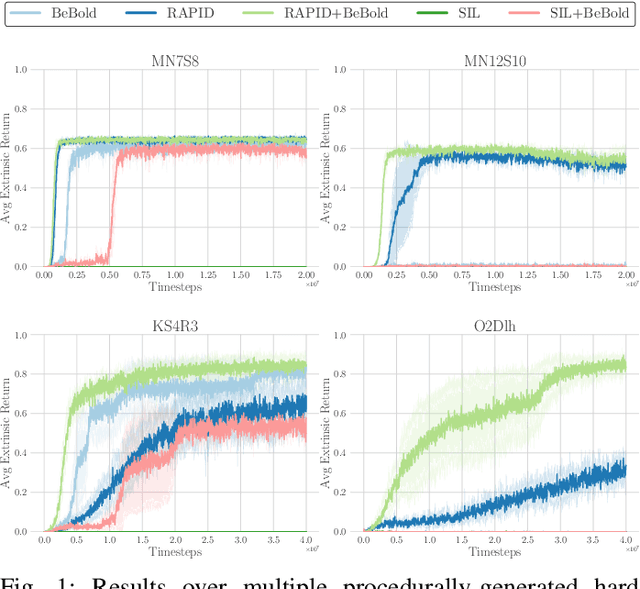
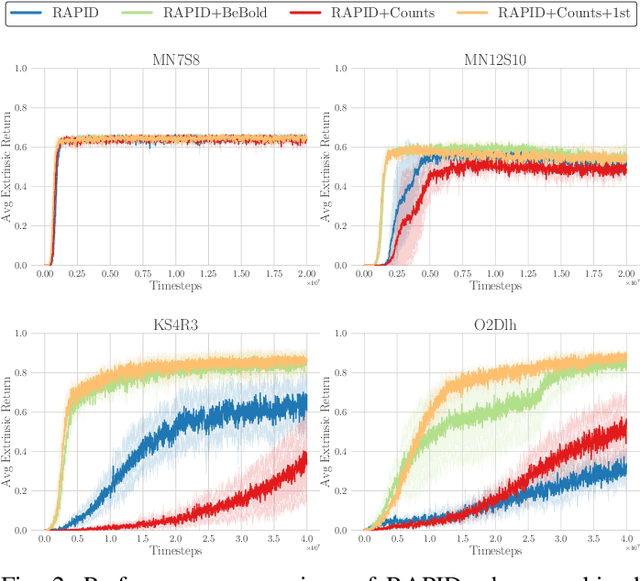
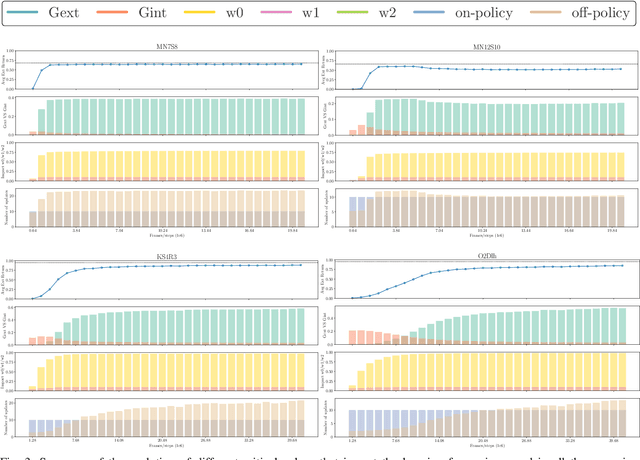
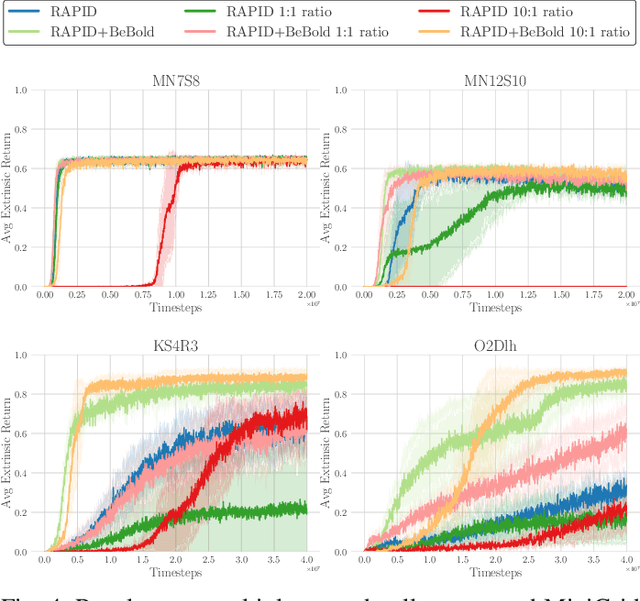
Reinforcement Learning has emerged as a strong alternative to solve optimization tasks efficiently. The use of these algorithms highly depends on the feedback signals provided by the environment in charge of informing about how good (or bad) the decisions made by the learned agent are. Unfortunately, in a broad range of problems the design of a good reward function is not trivial, so in such cases sparse reward signals are instead adopted. The lack of a dense reward function poses new challenges, mostly related to exploration. Imitation Learning has addressed those problems by leveraging demonstrations from experts. In the absence of an expert (and its subsequent demonstrations), an option is to prioritize well-suited exploration experiences collected by the agent in order to bootstrap its learning process with good exploration behaviors. However, this solution highly depends on the ability of the agent to discover such trajectories in the early stages of its learning process. To tackle this issue, we propose to combine imitation learning with intrinsic motivation, two of the most widely adopted techniques to address problems with sparse reward. In this work intrinsic motivation is used to encourage the agent to explore the environment based on its curiosity, whereas imitation learning allows repeating the most promising experiences to accelerate the learning process. This combination is shown to yield an improved performance and better generalization in procedurally-generated environments, outperforming previously reported self-imitation learning methods and achieving equal or better sample efficiency with respect to intrinsic motivation in isolation.
An Evaluation Study of Intrinsic Motivation Techniques applied to Reinforcement Learning over Hard Exploration Environments
May 23, 2022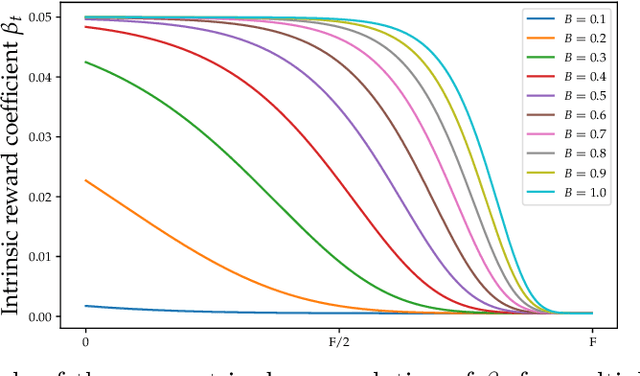
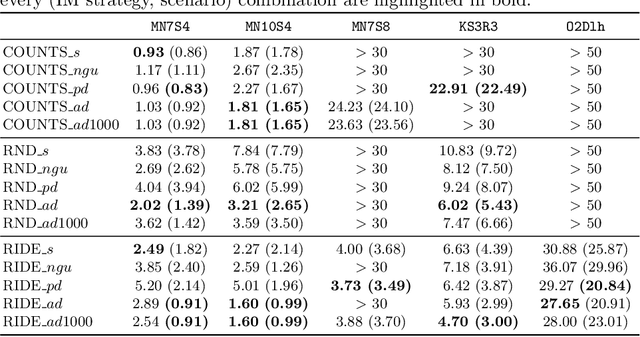

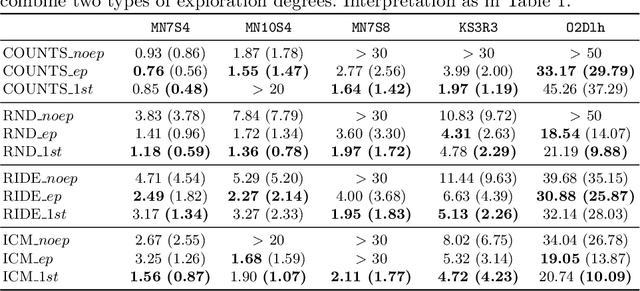
In the last few years, the research activity around reinforcement learning tasks formulated over environments with sparse rewards has been especially notable. Among the numerous approaches proposed to deal with these hard exploration problems, intrinsic motivation mechanisms are arguably among the most studied alternatives to date. Advances reported in this area over time have tackled the exploration issue by proposing new algorithmic ideas to generate alternative mechanisms to measure the novelty. However, most efforts in this direction have overlooked the influence of different design choices and parameter settings that have also been introduced to improve the effect of the generated intrinsic bonus, forgetting the application of those choices to other intrinsic motivation techniques that may also benefit of them. Furthermore, some of those intrinsic methods are applied with different base reinforcement algorithms (e.g. PPO, IMPALA) and neural network architectures, being hard to fairly compare the provided results and the actual progress provided by each solution. The goal of this work is to stress on this crucial matter in reinforcement learning over hard exploration environments, exposing the variability and susceptibility of avant-garde intrinsic motivation techniques to diverse design factors. Ultimately, our experiments herein reported underscore the importance of a careful selection of these design aspects coupled with the exploration requirements of the environment and the task in question under the same setup, so that fair comparisons can be guaranteed.