 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWords as Beacons: Guiding RL Agents with High-Level Language Prompts
Paper and Code
Oct 11, 2024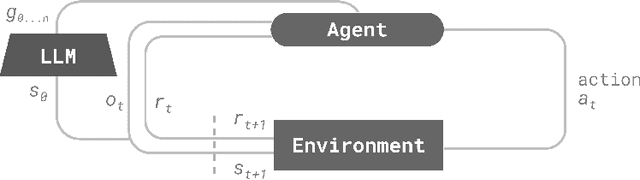

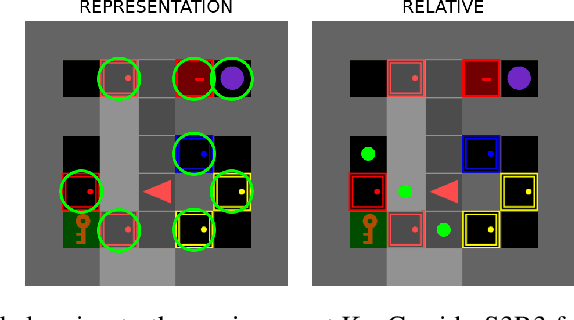
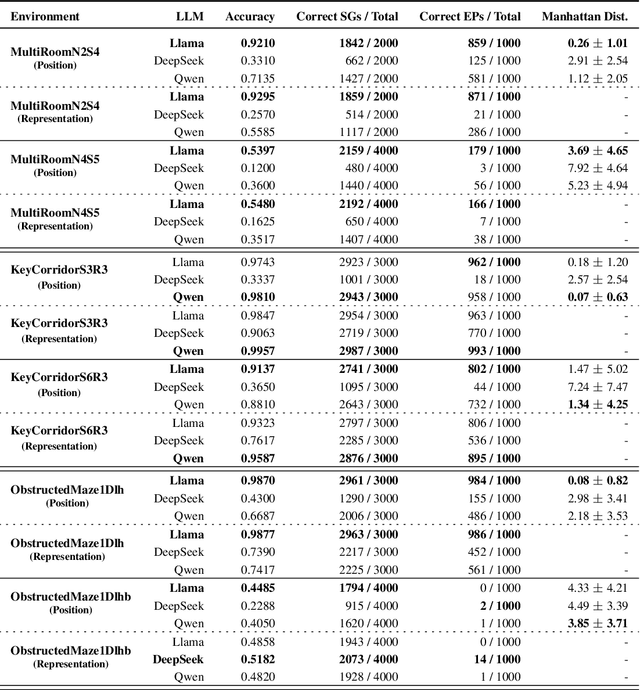
Sparse reward environments in reinforcement learning (RL) pose significant challenges for exploration, often leading to inefficient or incomplete learning processes. To tackle this issue, this work proposes a teacher-student RL framework that leverages Large Language Models (LLMs) as "teachers" to guide the agent's learning process by decomposing complex tasks into subgoals. Due to their inherent capability to understand RL environments based on a textual description of structure and purpose, LLMs can provide subgoals to accomplish the task defined for the environment in a similar fashion to how a human would do. In doing so, three types of subgoals are proposed: positional targets relative to the agent, object representations, and language-based instructions generated directly by the LLM. More importantly, we show that it is possible to query the LLM only during the training phase, enabling agents to operate within the environment without any LLM intervention. We assess the performance of this proposed framework by evaluating three state-of-the-art open-source LLMs (Llama, DeepSeek, Qwen) eliciting subgoals across various procedurally generated environment of the MiniGrid benchmark. Experimental results demonstrate that this curriculum-based approach accelerates learning and enhances exploration in complex tasks, achieving up to 30 to 200 times faster convergence in training steps compared to recent baselines designed for sparse reward environments.