 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improving Exploration in Self-Imitation Learning using Intrinsic Motivation
Paper and Code
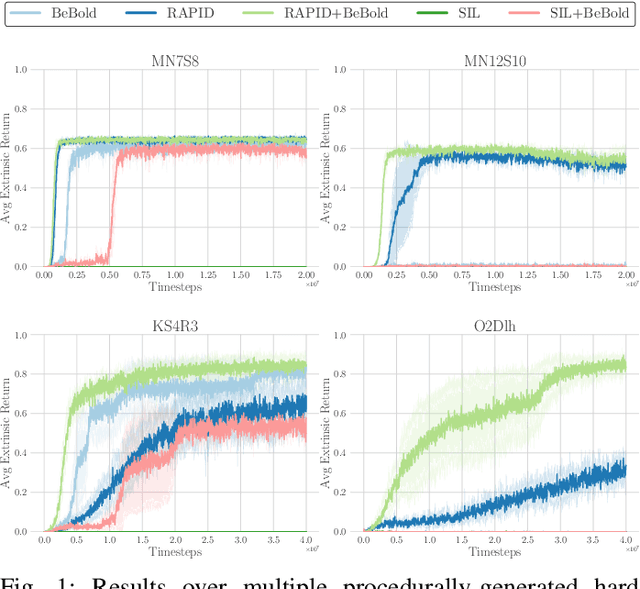
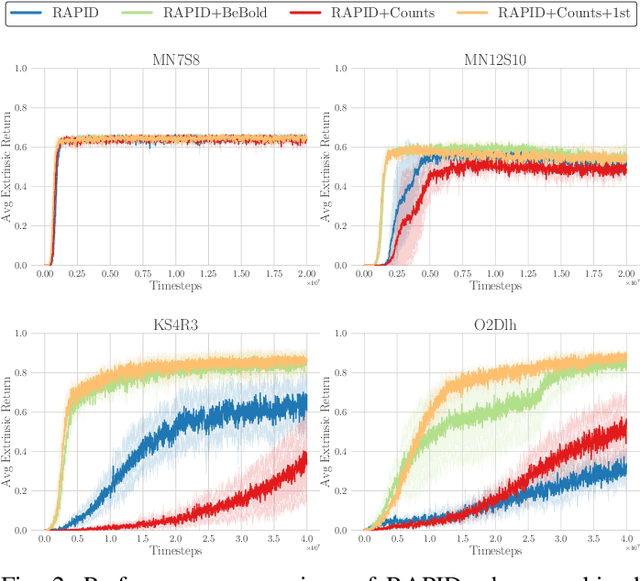
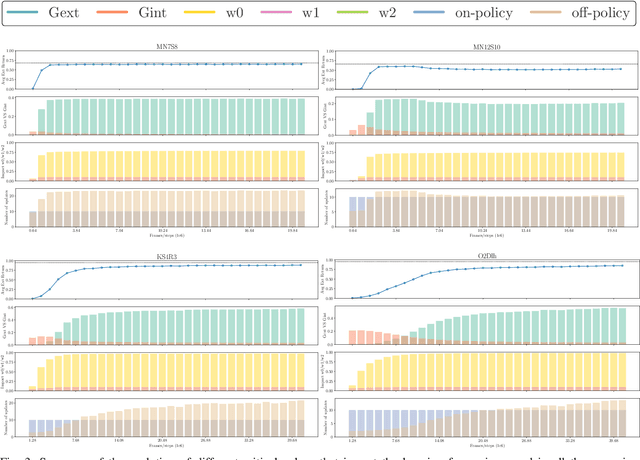
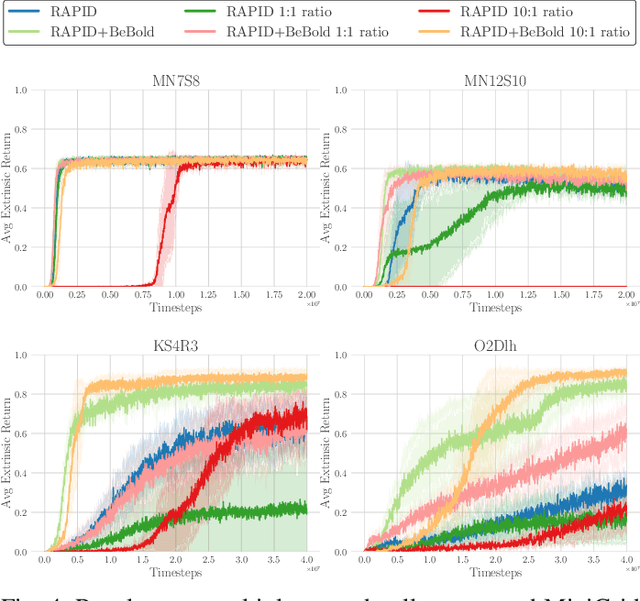
Reinforcement Learning has emerged as a strong alternative to solve optimization tasks efficiently. The use of these algorithms highly depends on the feedback signals provided by the environment in charge of informing about how good (or bad) the decisions made by the learned agent are. Unfortunately, in a broad range of problems the design of a good reward function is not trivial, so in such cases sparse reward signals are instead adopted. The lack of a dense reward function poses new challenges, mostly related to exploration. Imitation Learning has addressed those problems by leveraging demonstrations from experts. In the absence of an expert (and its subsequent demonstrations), an option is to prioritize well-suited exploration experiences collected by the agent in order to bootstrap its learning process with good exploration behaviors. However, this solution highly depends on the ability of the agent to discover such trajectories in the early stages of its learning process. To tackle this issue, we propose to combine imitation learning with intrinsic motivation, two of the most widely adopted techniques to address problems with sparse reward. In this work intrinsic motivation is used to encourage the agent to explore the environment based on its curiosity, whereas imitation learning allows repeating the most promising experiences to accelerate the learning process. This combination is shown to yield an improved performance and better generalization in procedurally-generated environments, outperforming previously reported self-imitation learning methods and achieving equal or better sample efficiency with respect to intrinsic motivation in isolation.