 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Black-box Explainability of Object Detection Models for Safe and Trustworthy Industrial Applications
Oct 28, 2024



In the realm of human-machine interaction, artificial intelligence has become a powerful tool for accelerating data modeling tasks. Object detection methods have achieved outstanding results and are widely used in critical domains like autonomous driving and video surveillance. However, their adoption in high-risk applications, where errors may cause severe consequences, remains limited. Explainable Artificial Intelligence (XAI) methods aim to address this issue, but many existing techniques are model-specific and designed for classification tasks, making them less effective for object detection and difficult for non-specialists to interpret. In this work we focus on model-agnostic XAI methods for object detection models and propose D-MFPP, an extension of the Morphological Fragmental Perturbation Pyramid (MFPP), which uses segmentation-based mask generation. Additionally, we introduce D-Deletion, a novel metric combining faithfulness and localization, adapted specifically to meet the unique demands of object detectors. We evaluate these methods on real-world industrial and robotic datasets, examining the influence of parameters such as the number of masks, model size, and image resolution on the quality of explanations. Our experiments use single-stage object detection models applied to two safety-critical robotic environments: i) a shared human-robot workspace where safety is of paramount importance, and ii) an assembly area of battery kits, where safety is critical due to the potential for damage among high-risk components. Our findings evince that D-Deletion effectively gauges the performance of explanations when multiple elements of the same class appear in the same scene, while D-MFPP provides a promising alternative to D-RISE when fewer masks are used.
On the Connection between Concept Drift and Uncertainty in Industrial Artificial Intelligence
Mar 14, 2023
AI-based digital twins are at the leading edge of the Industry 4.0 revolution, which are technologically empowered by the Internet of Things and real-time data analysis. Information collected from industrial assets is produced in a continuous fashion, yielding data streams that must be processed under stringent timing constraints. Such data streams are usually subject to non-stationary phenomena, causing that the data distribution of the streams may change, and thus the knowledge captured by models used for data analysis may become obsolete (leading to the so-called concept drift effect). The early detection of the change (drift) is crucial for updating the model's knowledge, which is challenging especially in scenarios where the ground truth associated to the stream data is not readily available. Among many other techniques, the estimation of the model's confidence has been timidly suggested in a few studies as a criterion for detecting drifts in unsupervised settings. The goal of this manuscript is to confirm and expose solidly the connection between the model's confidence in its output and the presence of a concept drift, showcasing it experimentally and advocating for a major consideration of uncertainty estimation in comparative studies to be reported in the future.
Measuring the Confidence of Traffic Forecasting Models: Techniques, Experimental Comparison and Guidelines towards Their Actionability
Oct 28, 2022



The estimation of the amount of uncertainty featured by predictive machine learning models has acquired a great momentum in recent years. Uncertainty estimation provides the user with augmented information about the model's confidence in its predicted outcome. Despite the inherent utility of this information for the trustworthiness of the user, there is a thin consensus around the different types of uncertainty that one can gauge in machine learning models and the suitability of different techniques that can be used to quantify the uncertainty of a specific model. This subject is mostly non existent within the traffic modeling domain, even though the measurement of the confidence associated to traffic forecasts can favor significantly their actionability in practical traffic management systems. This work aims to cover this lack of research by reviewing different techniques and metrics of uncertainty available in the literature, and by critically discussing how confidence levels computed for traffic forecasting models can be helpful for researchers and practitioners working in this research area. To shed light with empirical evidence, this critical discussion is further informed by experimental results produced by different uncertainty estimation techniques over real traffic data collected in Madrid (Spain), rendering a general overview of the benefits and caveats of every technique, how they can be compared to each other, and how the measured uncertainty decreases depending on the amount, quality and diversity of data used to produce the forecasts.
On the Design of Graph Embeddings for the Sensorless Estimation of Road Traffic Profiles
Jan 11, 2022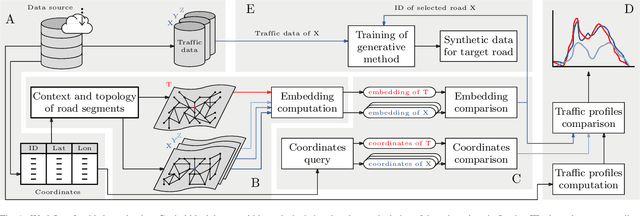
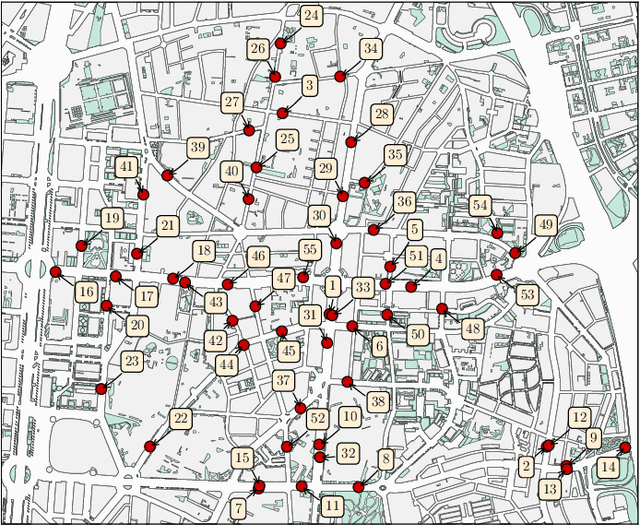

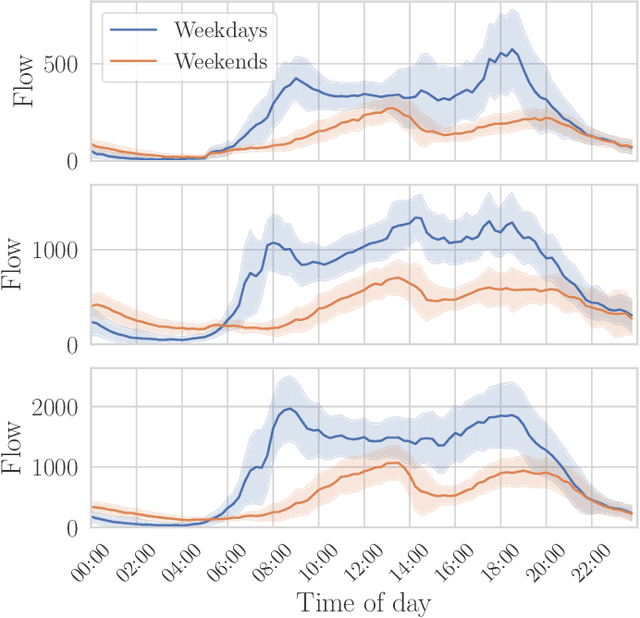
Traffic forecasting models rely on data that needs to be sensed, processed, and stored. This requires the deployment and maintenance of traffic sensing infrastructure, often leading to unaffordable monetary costs. The lack of sensed locations can be complemented with synthetic data simulations that further lower the economical investment needed for traffic monitoring. One of the most common data generative approaches consists of producing real-like traffic patterns, according to data distributions from analogous roads. The process of detecting roads with similar traffic is the key point of these systems. However, without collecting data at the target location no flow metrics can be employed for this similarity-based search. We present a method to discover locations among those with available traffic data by inspecting topological features of road segments. Relevant topological features are extracted as numerical representations (embeddings) to compare different locations and eventually find the most similar roads based on the similarity between their embeddings. The performance of this novel selection system is examined and compared to simpler traffic estimation approaches. After finding a similar source of data, a generative method is used to synthesize traffic profiles. Depending on the resemblance of the traffic behavior at the sensed road, the generation method can be fed with data from one road only. Several generation approaches are analyzed in terms of the precision of the synthesized samples. Above all, this work intends to stimulate further research efforts towards enhancing the quality of synthetic traffic samples and thereby, reducing the need for sensing infrastructure.
On the Post-hoc Explainability of Deep Echo State Networks for Time Series Forecasting, Image and Video Classification
Feb 17, 2021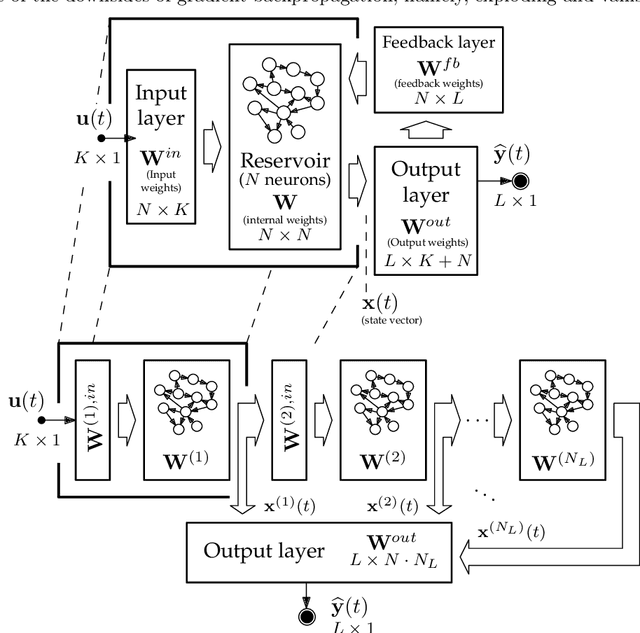
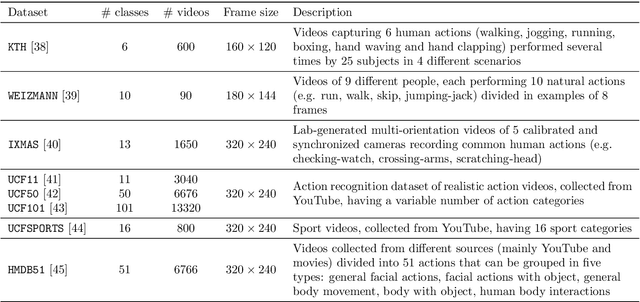
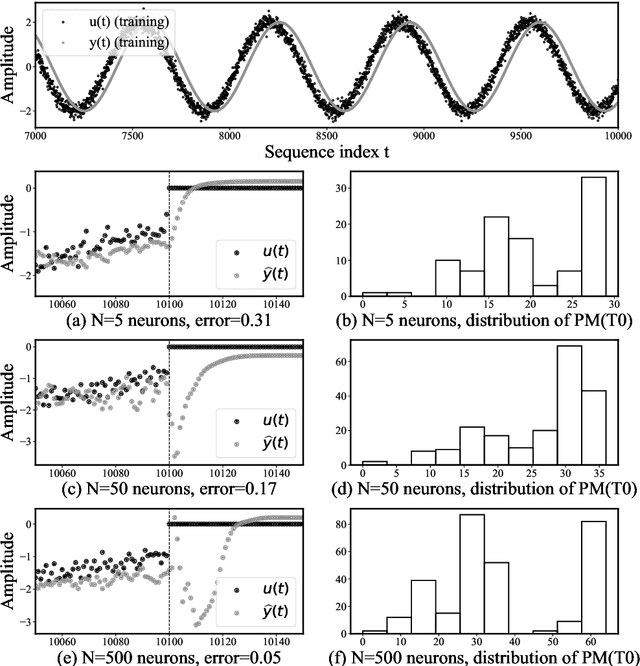
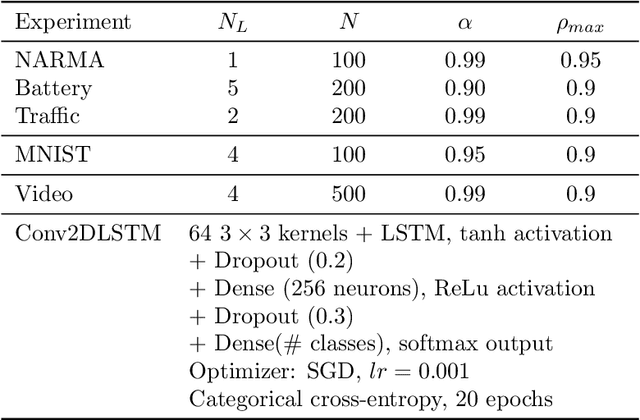
Since their inception, learning techniques under the Reservoir Computing paradigm have shown a great modeling capability for recurrent systems without the computing overheads required for other approaches. Among them, different flavors of echo state networks have attracted many stares through time, mainly due to the simplicity and computational efficiency of their learning algorithm. However, these advantages do not compensate for the fact that echo state networks remain as black-box models whose decisions cannot be easily explained to the general audience. This work addresses this issue by conducting an explainability study of Echo State Networks when applied to learning tasks with time series, image and video data. Specifically, the study proposes three different techniques capable of eliciting understandable information about the knowledge grasped by these recurrent models, namely, potential memory, temporal patterns and pixel absence effect. Potential memory addresses questions related to the effect of the reservoir size in the capability of the model to store temporal information, whereas temporal patterns unveils the recurrent relationships captured by the model over time. Finally, pixel absence effect attempts at evaluating the effect of the absence of a given pixel when the echo state network model is used for image and video classification. We showcase the benefits of our proposed suite of techniques over three different domains of applicability: time series modeling, image and, for the first time in the related literature, video classification. Our results reveal that the proposed techniques not only allow for a informed understanding of the way these models work, but also serve as diagnostic tools capable of detecting issues inherited from data (e.g. presence of hidden bias).
Deep Learning for Road Traffic Forecasting: Does it Make a Difference?
Dec 02, 2020
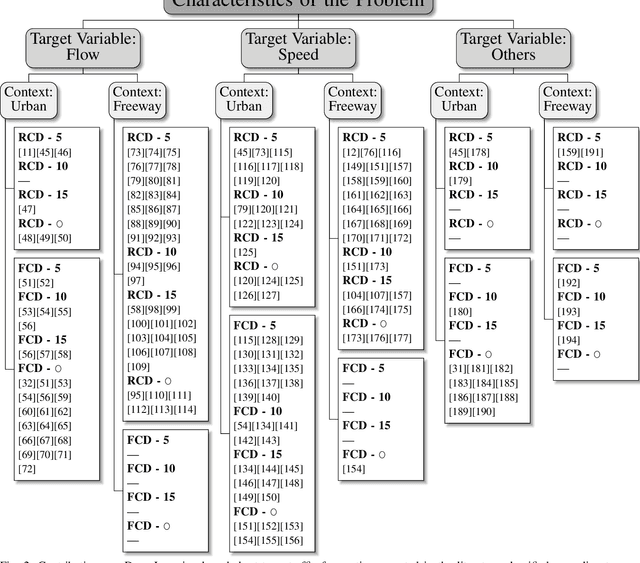

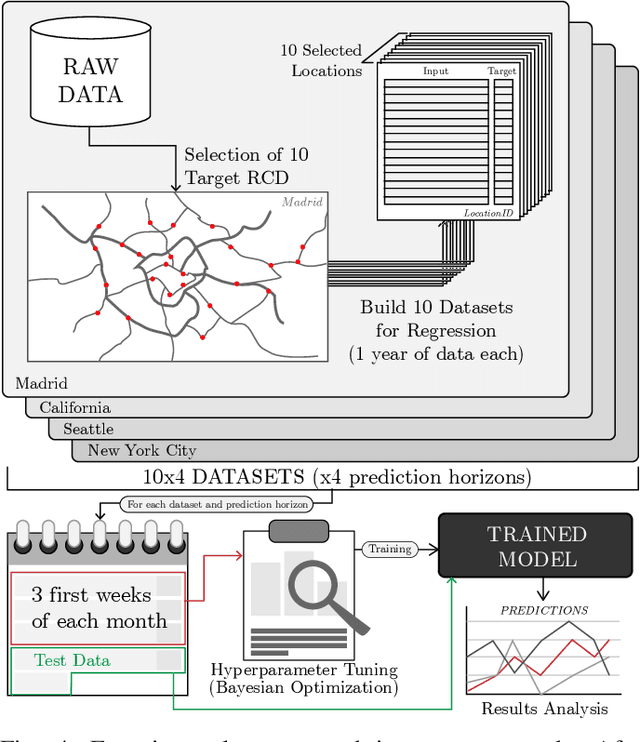
Deep Learning methods have been proven to be flexible to model complex phenomena. This has also been the case of Intelligent Transportation Systems (ITS), in which several areas such as vehicular perception and traffic analysis have widely embraced Deep Learning as a core modeling technology. Particularly in short-term traffic forecasting, the capability of Deep Learning to deliver good results has generated a prevalent inertia towards using Deep Learning models, without examining in depth their benefits and downsides. This paper focuses on critically analyzing the state of the art in what refers to the use of Deep Learning for this particular ITS research area. To this end, we elaborate on the findings distilled from a review of publications from recent years, based on two taxonomic criteria. A posterior critical analysis is held to formulate questions and trigger a necessary debate about the issues of Deep Learning for traffic forecasting. The study is completed with a benchmark of diverse short-term traffic forecasting methods over traffic datasets of different nature, aimed to cover a wide spectrum of possible scenarios. Our experimentation reveals that Deep Learning could not be the best modeling technique for every case, which unveils some caveats unconsidered to date that should be addressed by the community in prospective studies. These insights reveal new challenges and research opportunities in road traffic forecasting, which are enumerated and discussed thoroughly, with the intention of inspiring and guiding future research efforts in this field.
On the Transferability of Knowledge among Vehicle Routing Problems by using Cellular Evolutionary Multitasking
May 17, 2020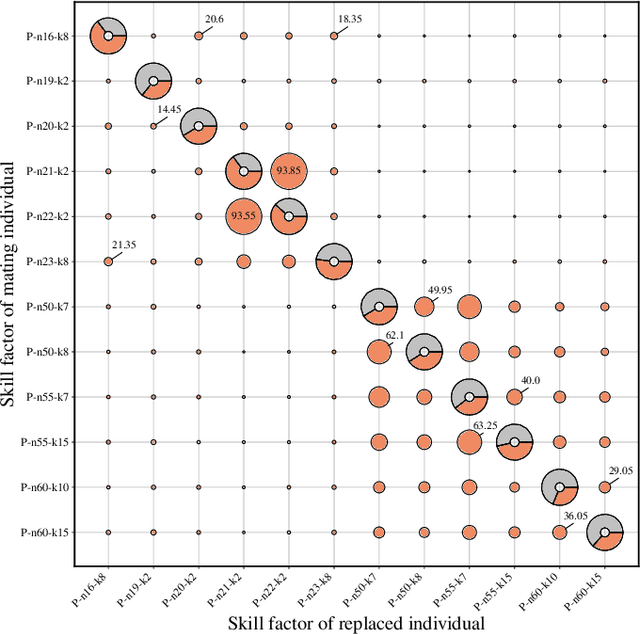
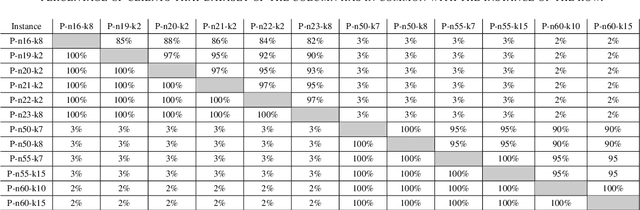
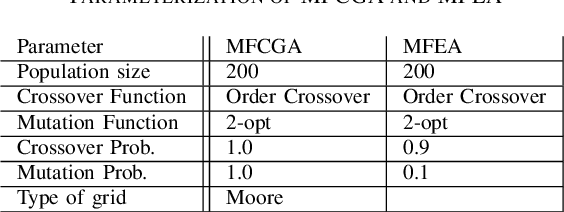
Multitasking optimization is a recently introduced paradigm, focused on the simultaneous solving of multiple optimization problem instances (tasks). The goal of multitasking environments is to dynamically exploit existing complementarities and synergies among tasks, helping each other through the transfer of genetic material. More concretely, Evolutionary Multitasking (EM) regards to the resolution of multitasking scenarios using concepts inherited from Evolutionary Computation. EM approaches such as the well-known Multifactorial Evolutionary Algorithm (MFEA) are lately gaining a notable research momentum when facing with multiple optimization problems. This work is focused on the application of the recently proposed Multifactorial Cellular Genetic Algorithm (MFCGA) to the well-known Capacitated Vehicle Routing Problem (CVRP). In overall, 11 different multitasking setups have been built using 12 datasets. The contribution of this research is twofold. On the one hand, it is the first application of the MFCGA to the Vehicle Routing Problem family of problems. On the other hand, equally interesting is the second contribution, which is focused on the quantitative analysis of the positive genetic transferability among the problem instances. To do that, we provide an empirical demonstration of the synergies arisen between the different optimization tasks.
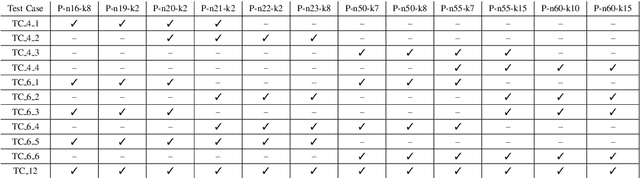
Transfer Learning and Online Learning for Traffic Forecasting under Different Data Availability Conditions: Alternatives and Pitfalls
May 08, 2020
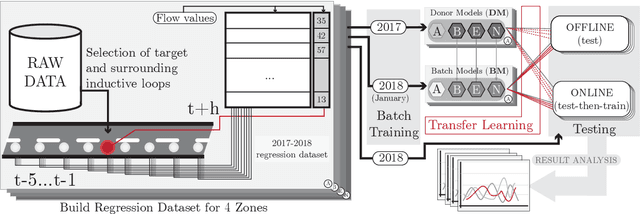
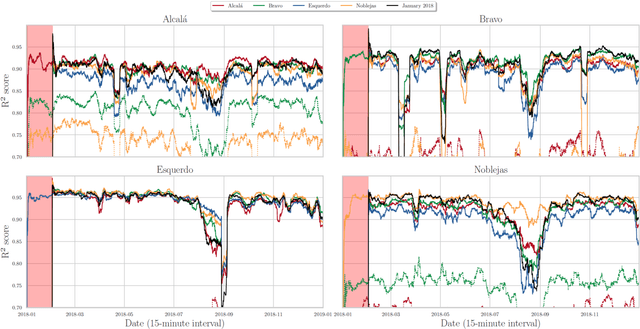
This work aims at unveiling the potential of Transfer Learning (TL) for developing a traffic flow forecasting model in scenarios of absent data. Knowledge transfer from high-quality predictive models becomes feasible under the TL paradigm, enabling the generation of new proper models with few data. In order to explore this capability, we identify three different levels of data absent scenarios, where TL techniques are applied among Deep Learning (DL) methods for traffic forecasting. Then, traditional batch learning is compared against TL based models using real traffic flow data, collected by deployed loops managed by the City Council of Madrid (Spain). In addition, we apply Online Learning (OL) techniques, where model receives an update after each prediction, in order to adapt to traffic flow trend changes and incrementally learn from new incoming traffic data. The obtained experimental results shed light on the advantages of transfer and online learning for traffic flow forecasting, and draw practical insights on their interplay with the amount of available training data at the location of interest.
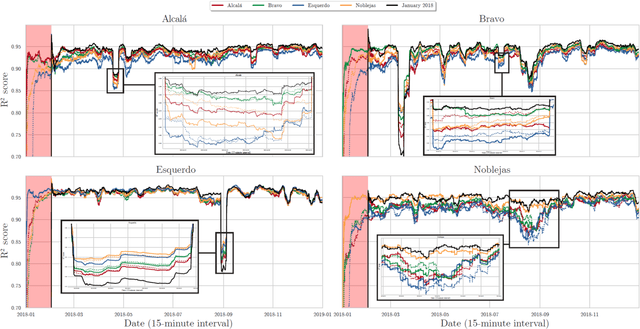
New Perspectives on the Use of Online Learning for Congestion Level Prediction over Traffic Data
Mar 27, 2020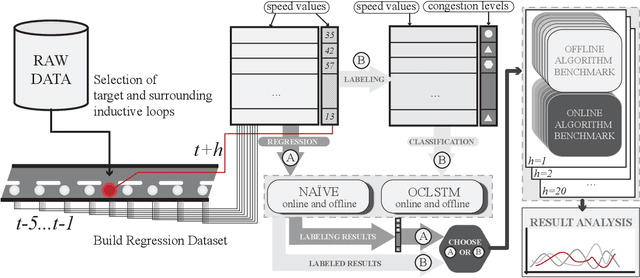


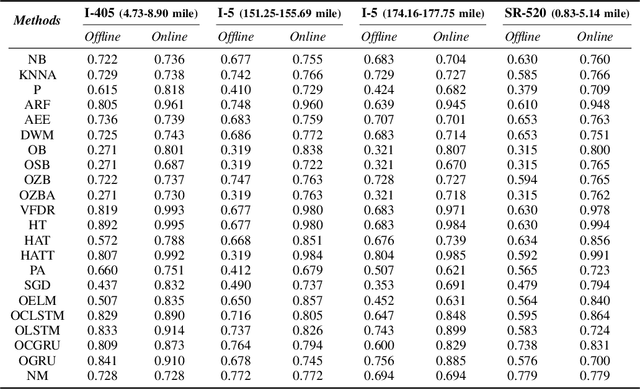
This work focuses on classification over time series data. When a time series is generated by non-stationary phenomena, the pattern relating the series with the class to be predicted may evolve over time (concept drift). Consequently, predictive models aimed to learn this pattern may become eventually obsolete, hence failing to sustain performance levels of practical use. To overcome this model degradation, online learning methods incrementally learn from new data samples arriving over time, and accommodate eventual changes along the data stream by implementing assorted concept drift strategies. In this manuscript we elaborate on the suitability of online learning methods to predict the road congestion level based on traffic speed time series data. We draw interesting insights on the performance degradation when the forecasting horizon is increased. As opposed to what is done in most literature, we provide evidence of the importance of assessing the distribution of classes over time before designing and tuning the learning model. This previous exercise may give a hint of the predictability of the different congestion levels under target. Experimental results are discussed over real traffic speed data captured by inductive loops deployed over Seattle (USA). Several online learning methods are analyzed, from traditional incremental learning algorithms to more elaborated deep learning models. As shown by the reported results, when increasing the prediction horizon, the performance of all models degrade severely due to the distribution of classes along time, which supports our claim about the importance of analyzing this distribution prior to the design of the model.