 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Design of Graph Embeddings for the Sensorless Estimation of Road Traffic Profiles
Jan 11, 2022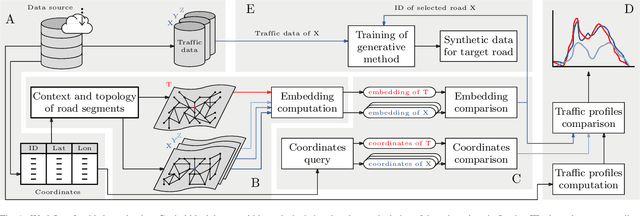

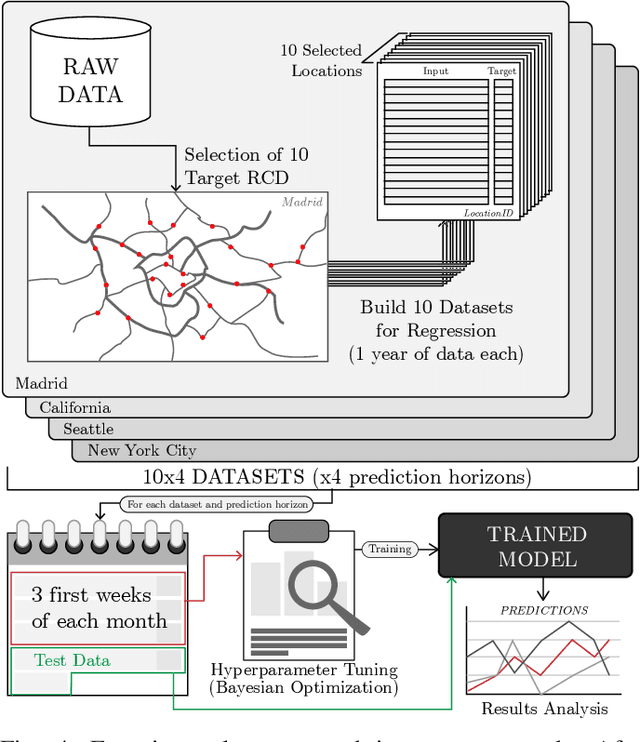
Traffic forecasting models rely on data that needs to be sensed, processed, and stored. This requires the deployment and maintenance of traffic sensing infrastructure, often leading to unaffordable monetary costs. The lack of sensed locations can be complemented with synthetic data simulations that further lower the economical investment needed for traffic monitoring. One of the most common data generative approaches consists of producing real-like traffic patterns, according to data distributions from analogous roads. The process of detecting roads with similar traffic is the key point of these systems. However, without collecting data at the target location no flow metrics can be employed for this similarity-based search. We present a method to discover locations among those with available traffic data by inspecting topological features of road segments. Relevant topological features are extracted as numerical representations (embeddings) to compare different locations and eventually find the most similar roads based on the similarity between their embeddings. The performance of this novel selection system is examined and compared to simpler traffic estimation approaches. After finding a similar source of data, a generative method is used to synthesize traffic profiles. Depending on the resemblance of the traffic behavior at the sensed road, the generation method can be fed with data from one road only. Several generation approaches are analyzed in terms of the precision of the synthesized samples. Above all, this work intends to stimulate further research efforts towards enhancing the quality of synthetic traffic samples and thereby, reducing the need for sensing infrastructure.
Deep Learning for Road Traffic Forecasting: Does it Make a Difference?
Dec 02, 2020

Deep Learning methods have been proven to be flexible to model complex phenomena. This has also been the case of Intelligent Transportation Systems (ITS), in which several areas such as vehicular perception and traffic analysis have widely embraced Deep Learning as a core modeling technology. Particularly in short-term traffic forecasting, the capability of Deep Learning to deliver good results has generated a prevalent inertia towards using Deep Learning models, without examining in depth their benefits and downsides. This paper focuses on critically analyzing the state of the art in what refers to the use of Deep Learning for this particular ITS research area. To this end, we elaborate on the findings distilled from a review of publications from recent years, based on two taxonomic criteria. A posterior critical analysis is held to formulate questions and trigger a necessary debate about the issues of Deep Learning for traffic forecasting. The study is completed with a benchmark of diverse short-term traffic forecasting methods over traffic datasets of different nature, aimed to cover a wide spectrum of possible scenarios. Our experimentation reveals that Deep Learning could not be the best modeling technique for every case, which unveils some caveats unconsidered to date that should be addressed by the community in prospective studies. These insights reveal new challenges and research opportunities in road traffic forecasting, which are enumerated and discussed thoroughly, with the intention of inspiring and guiding future research efforts in this field.
Transfer Learning and Online Learning for Traffic Forecasting under Different Data Availability Conditions: Alternatives and Pitfalls
May 08, 2020
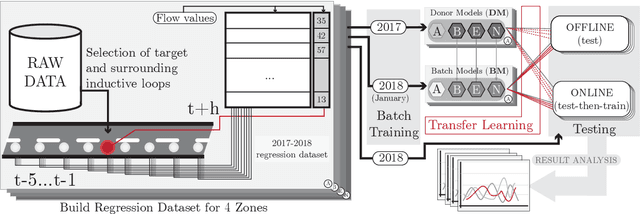
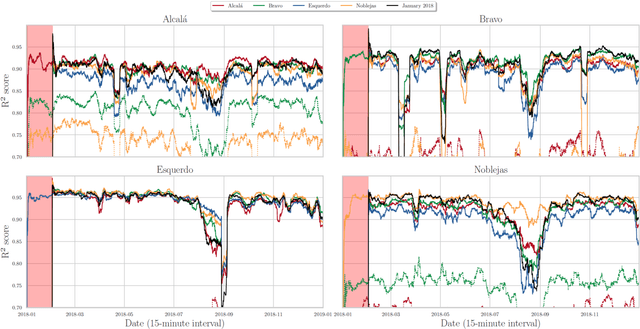
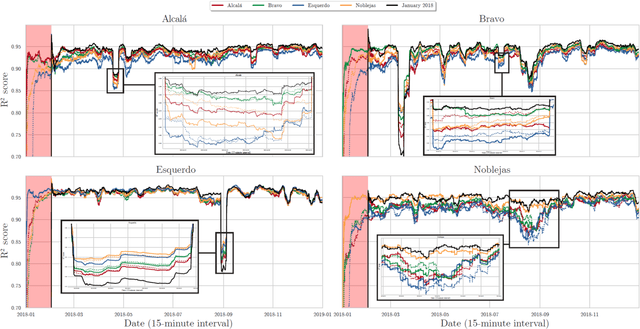
This work aims at unveiling the potential of Transfer Learning (TL) for developing a traffic flow forecasting model in scenarios of absent data. Knowledge transfer from high-quality predictive models becomes feasible under the TL paradigm, enabling the generation of new proper models with few data. In order to explore this capability, we identify three different levels of data absent scenarios, where TL techniques are applied among Deep Learning (DL) methods for traffic forecasting. Then, traditional batch learning is compared against TL based models using real traffic flow data, collected by deployed loops managed by the City Council of Madrid (Spain). In addition, we apply Online Learning (OL) techniques, where model receives an update after each prediction, in order to adapt to traffic flow trend changes and incrementally learn from new incoming traffic data. The obtained experimental results shed light on the advantages of transfer and online learning for traffic flow forecasting, and draw practical insights on their interplay with the amount of available training data at the location of interest.
Deep Echo State Networks for Short-Term Traffic Forecasting: Performance Comparison and Statistical Assessment
Apr 17, 2020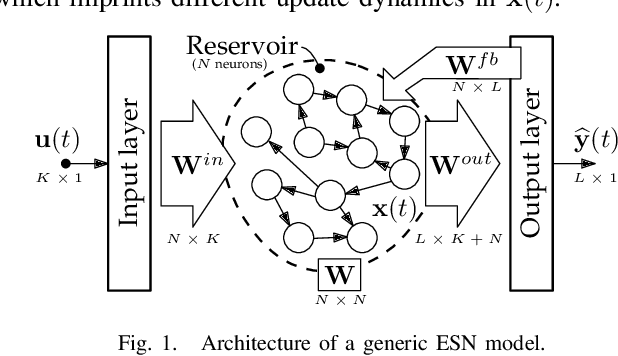
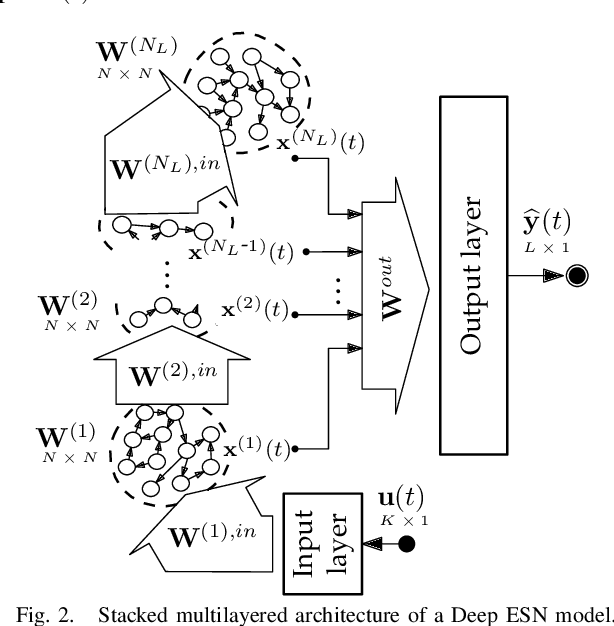

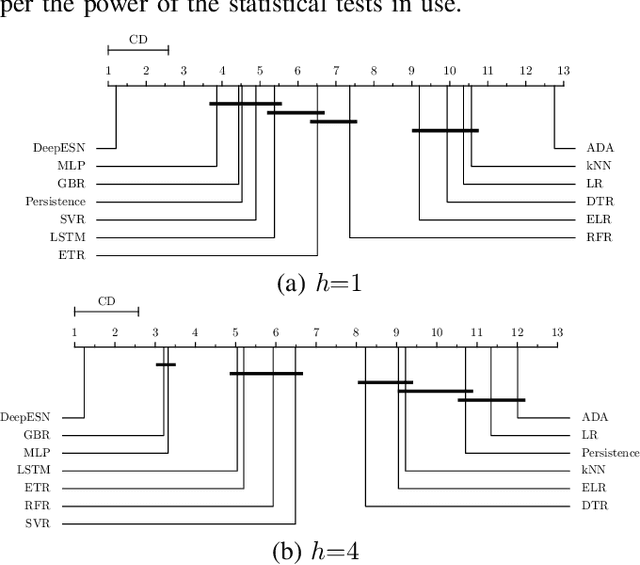
In short-term traffic forecasting, the goal is to accurately predict future values of a traffic parameter of interest occurring shortly after the prediction is queried. The activity reported in this long-standing research field has been lately dominated by different Deep Learning approaches, yielding overly complex forecasting models that in general achieve accuracy gains of questionable practical utility. In this work we elaborate on the performance of Deep Echo State Networks for this particular task. The efficient learning algorithm and simpler parametric configuration of these alternative modeling approaches make them emerge as a competitive traffic forecasting method for real ITS applications deployed in devices and systems with stringently limited computational resources. An extensive comparison benchmark is designed with real traffic data captured over the city of Madrid (Spain), amounting to more than 130 automatic Traffic Readers (ATRs) and several shallow learning, ensembles and Deep Learning models. Results from this comparison benchmark and the analysis of the statistical significance of the reported performance gaps are decisive: Deep Echo State Networks achieve more accurate traffic forecasts than the rest of considered modeling counterparts.
New Perspectives on the Use of Online Learning for Congestion Level Prediction over Traffic Data
Mar 27, 2020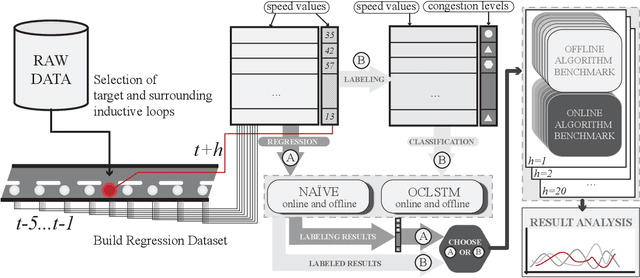


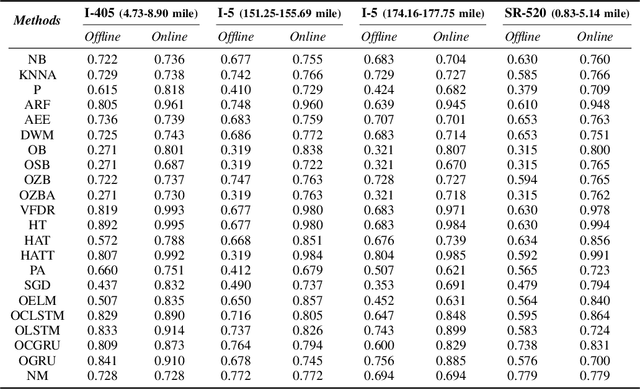
This work focuses on classification over time series data. When a time series is generated by non-stationary phenomena, the pattern relating the series with the class to be predicted may evolve over time (concept drift). Consequently, predictive models aimed to learn this pattern may become eventually obsolete, hence failing to sustain performance levels of practical use. To overcome this model degradation, online learning methods incrementally learn from new data samples arriving over time, and accommodate eventual changes along the data stream by implementing assorted concept drift strategies. In this manuscript we elaborate on the suitability of online learning methods to predict the road congestion level based on traffic speed time series data. We draw interesting insights on the performance degradation when the forecasting horizon is increased. As opposed to what is done in most literature, we provide evidence of the importance of assessing the distribution of classes over time before designing and tuning the learning model. This previous exercise may give a hint of the predictability of the different congestion levels under target. Experimental results are discussed over real traffic speed data captured by inductive loops deployed over Seattle (USA). Several online learning methods are analyzed, from traditional incremental learning algorithms to more elaborated deep learning models. As shown by the reported results, when increasing the prediction horizon, the performance of all models degrade severely due to the distribution of classes along time, which supports our claim about the importance of analyzing this distribution prior to the design of the model.