 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiGAS-dEVL-RC: An Adaptive Growing Neural Gas Model for Recurrently Drifting Unsupervised Data Streams
Apr 10, 2025


Concept drift and extreme verification latency pose significant challenges in data stream learning, particularly when dealing with recurring concept changes in dynamic environments. This work introduces a novel method based on the Growing Neural Gas (GNG) algorithm, designed to effectively handle abrupt recurrent drifts while adapting to incrementally evolving data distributions (incremental drifts). Leveraging the self-organizing and topological adaptability of GNG, the proposed approach maintains a compact yet informative memory structure, allowing it to efficiently store and retrieve knowledge of past or recurring concepts, even under conditions of delayed or sparse stream supervision. Our experiments highlight the superiority of our approach over existing data stream learning methods designed to cope with incremental non-stationarities and verification latency, demonstrating its ability to quickly adapt to new drifts, robustly manage recurring patterns, and maintain high predictive accuracy with a minimal memory footprint. Unlike other techniques that fail to leverage recurring knowledge, our proposed approach is proven to be a robust and efficient online learning solution for unsupervised drifting data flows.
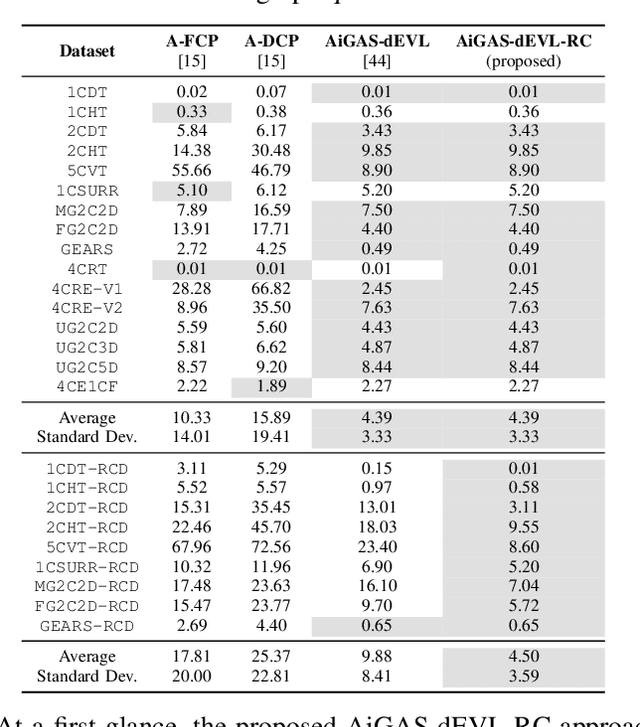
AiGAS-dEVL: An Adaptive Incremental Neural Gas Model for Drifting Data Streams under Extreme Verification Latency
Jul 07, 2024The ever-growing speed at which data are generated nowadays, together with the substantial cost of labeling processes cause Machine Learning models to face scenarios in which data are partially labeled. The extreme case where such a supervision is indefinitely unavailable is referred to as extreme verification latency. On the other hand, in streaming setups data flows are affected by exogenous factors that yield non-stationarities in the patterns (concept drift), compelling models learned incrementally from the data streams to adapt their modeled knowledge to the concepts within the stream. In this work we address the casuistry in which these two conditions occur together, by which adaptation mechanisms to accommodate drifts within the stream are challenged by the lack of supervision, requiring further mechanisms to track the evolution of concepts in the absence of verification. To this end we propose a novel approach, AiGAS-dEVL (Adaptive Incremental neural GAS model for drifting Streams under Extreme Verification Latency), which relies on growing neural gas to characterize the distributions of all concepts detected within the stream over time. Our approach exposes that the online analysis of the behavior of these prototypical points over time facilitates the definition of the evolution of concepts in the feature space, the detection of changes in their behavior, and the design of adaptation policies to mitigate the effect of such changes in the model. We assess the performance of AiGAS-dEVL over several synthetic datasets, comparing it to that of state-of-the-art approaches proposed in the recent past to tackle this stream learning setup. Our results reveal that AiGAS-dEVL performs competitively with respect to the rest of baselines, exhibiting a superior adaptability over several datasets in the benchmark while ensuring a simple and interpretable instance-based adaptation strategy.
On the Post-hoc Explainability of Deep Echo State Networks for Time Series Forecasting, Image and Video Classification
Feb 17, 2021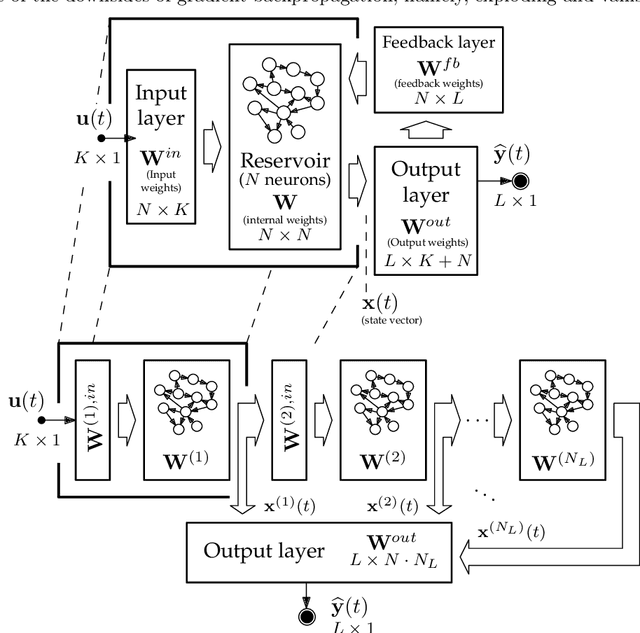
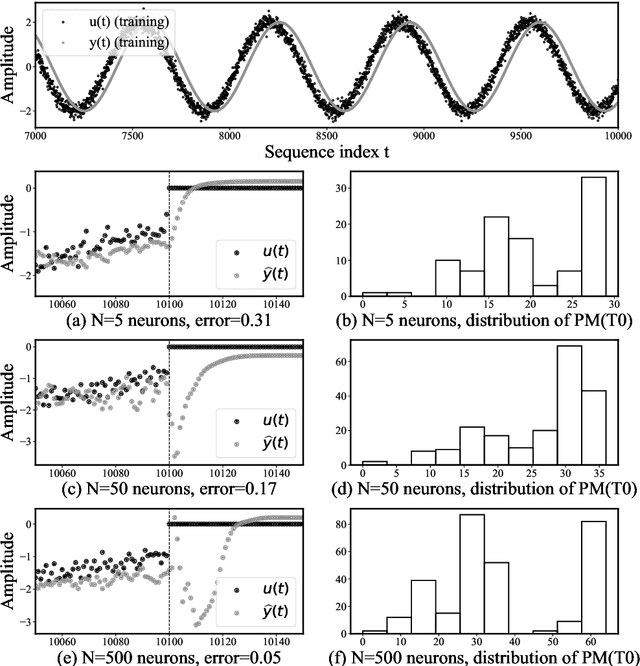
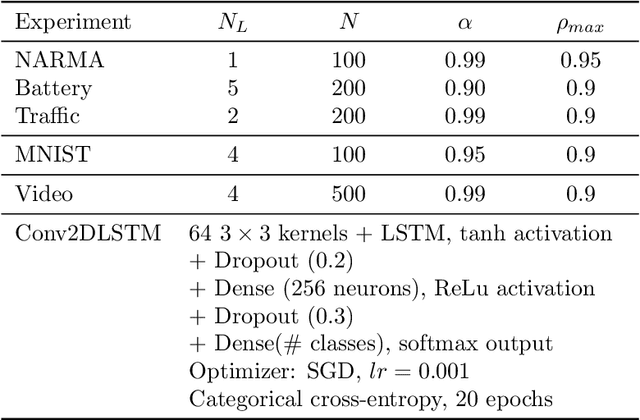
Since their inception, learning techniques under the Reservoir Computing paradigm have shown a great modeling capability for recurrent systems without the computing overheads required for other approaches. Among them, different flavors of echo state networks have attracted many stares through time, mainly due to the simplicity and computational efficiency of their learning algorithm. However, these advantages do not compensate for the fact that echo state networks remain as black-box models whose decisions cannot be easily explained to the general audience. This work addresses this issue by conducting an explainability study of Echo State Networks when applied to learning tasks with time series, image and video data. Specifically, the study proposes three different techniques capable of eliciting understandable information about the knowledge grasped by these recurrent models, namely, potential memory, temporal patterns and pixel absence effect. Potential memory addresses questions related to the effect of the reservoir size in the capability of the model to store temporal information, whereas temporal patterns unveils the recurrent relationships captured by the model over time. Finally, pixel absence effect attempts at evaluating the effect of the absence of a given pixel when the echo state network model is used for image and video classification. We showcase the benefits of our proposed suite of techniques over three different domains of applicability: time series modeling, image and, for the first time in the related literature, video classification. Our results reveal that the proposed techniques not only allow for a informed understanding of the way these models work, but also serve as diagnostic tools capable of detecting issues inherited from data (e.g. presence of hidden bias).
Deep Echo State Networks for Short-Term Traffic Forecasting: Performance Comparison and Statistical Assessment
Apr 17, 2020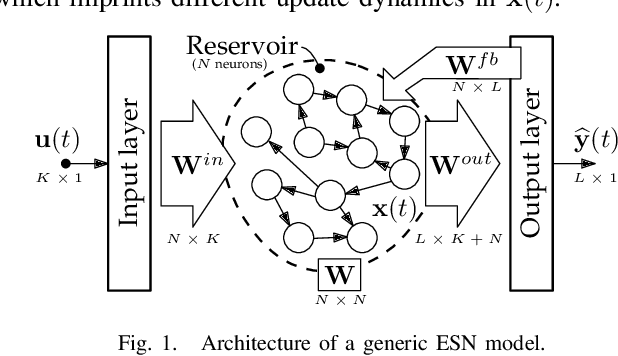
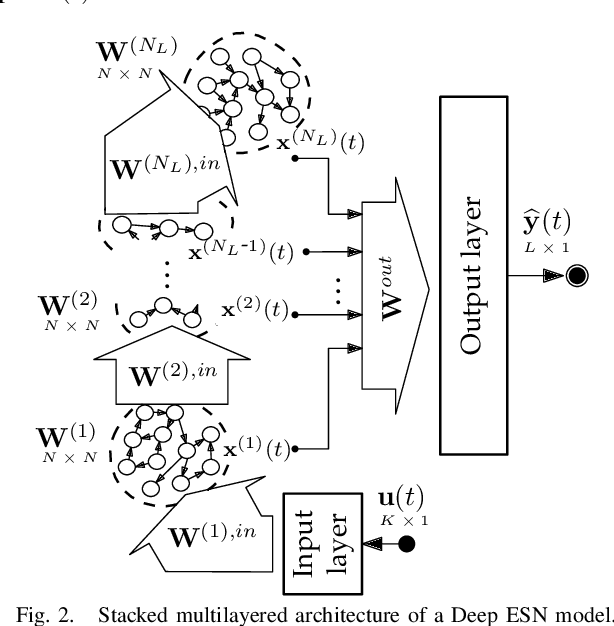

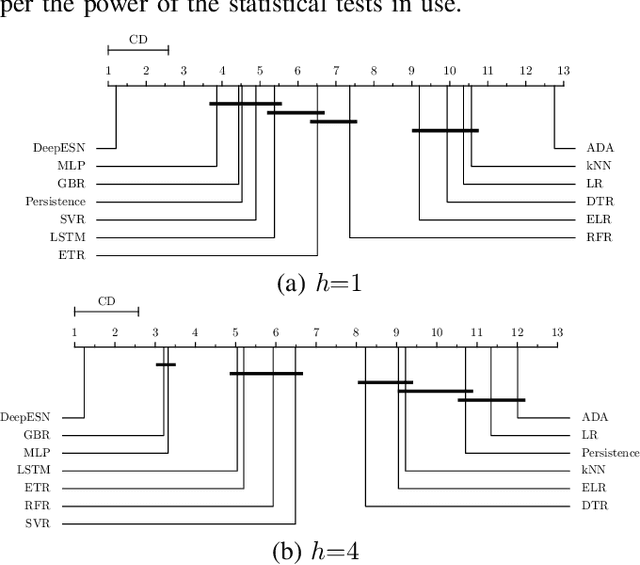
In short-term traffic forecasting, the goal is to accurately predict future values of a traffic parameter of interest occurring shortly after the prediction is queried. The activity reported in this long-standing research field has been lately dominated by different Deep Learning approaches, yielding overly complex forecasting models that in general achieve accuracy gains of questionable practical utility. In this work we elaborate on the performance of Deep Echo State Networks for this particular task. The efficient learning algorithm and simpler parametric configuration of these alternative modeling approaches make them emerge as a competitive traffic forecasting method for real ITS applications deployed in devices and systems with stringently limited computational resources. An extensive comparison benchmark is designed with real traffic data captured over the city of Madrid (Spain), amounting to more than 130 automatic Traffic Readers (ATRs) and several shallow learning, ensembles and Deep Learning models. Results from this comparison benchmark and the analysis of the statistical significance of the reported performance gaps are decisive: Deep Echo State Networks achieve more accurate traffic forecasts than the rest of considered modeling counterparts.