 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Sampling for MRI-based Sequential Decision Making
May 07, 2025Despite the superior diagnostic capability of Magnetic Resonance Imaging (MRI), its use as a Point-of-Care (PoC) device remains limited by high cost and complexity. To enable such a future by reducing the magnetic field strength, one key approach will be to improve sampling strategies. Previous work has shown that it is possible to make diagnostic decisions directly from k-space with fewer samples. Such work shows that single diagnostic decisions can be made, but if we aspire to see MRI as a true PoC, multiple and sequential decisions are necessary while minimizing the number of samples acquired. We present a novel multi-objective reinforcement learning framework enabling comprehensive, sequential, diagnostic evaluation from undersampled k-space data. Our approach during inference actively adapts to sequential decisions to optimally sample. To achieve this, we introduce a training methodology that identifies the samples that contribute the best to each diagnostic objective using a step-wise weighting reward function. We evaluate our approach in two sequential knee pathology assessment tasks: ACL sprain detection and cartilage thickness loss assessment. Our framework achieves diagnostic performance competitive with various policy-based benchmarks on disease detection, severity quantification, and overall sequential diagnosis, while substantially saving k-space samples. Our approach paves the way for the future of MRI as a comprehensive and affordable PoC device. Our code is publicly available at https://github.com/vios-s/MRI_Sequential_Active_Sampling
Surgical Task Automation Using Actor-Critic Frameworks and Self-Supervised Imitation Learning
Sep 04, 2024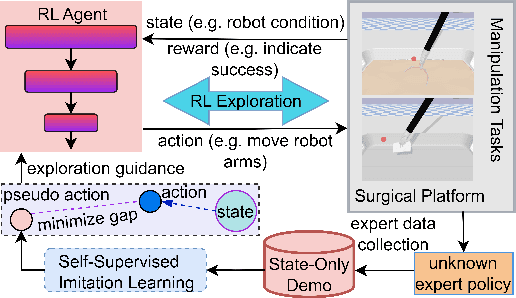
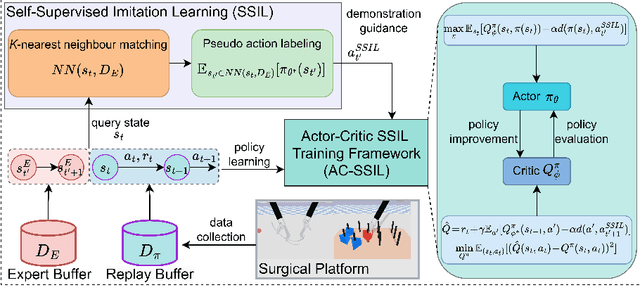
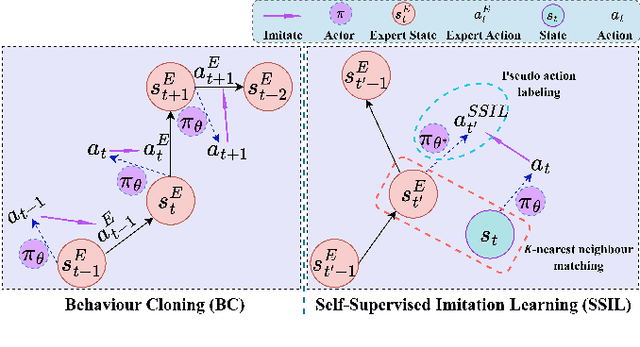
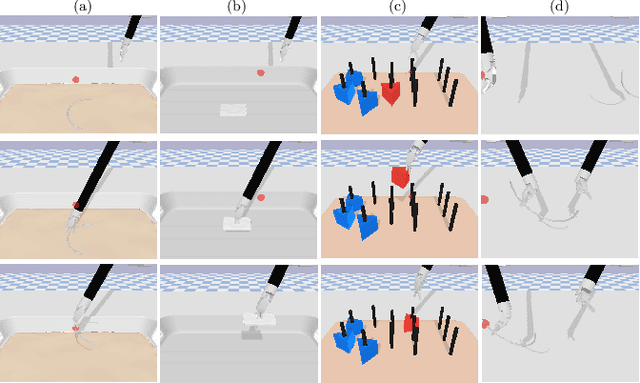
Surgical robot task automation has recently attracted great attention due to its potential to benefit both surgeons and patients. Reinforcement learning (RL) based approaches have demonstrated promising ability to provide solutions to automated surgical manipulations on various tasks. To address the exploration challenge, expert demonstrations can be utilized to enhance the learning efficiency via imitation learning (IL) approaches. However, the successes of such methods normally rely on both states and action labels. Unfortunately action labels can be hard to capture or their manual annotation is prohibitively expensive owing to the requirement for expert knowledge. It therefore remains an appealing and open problem to leverage expert demonstrations composed of pure states in RL. In this work, we present an actor-critic RL framework, termed AC-SSIL, to overcome this challenge of learning with state-only demonstrations collected by following an unknown expert policy. It adopts a self-supervised IL method, dubbed SSIL, to effectively incorporate demonstrated states into RL paradigms by retrieving from demonstrates the nearest neighbours of the query state and utilizing the bootstrapping of actor networks. We showcase through experiments on an open-source surgical simulation platform that our method delivers remarkable improvements over the RL baseline and exhibits comparable performance against action based IL methods, which implies the efficacy and potential of our method for expert demonstration-guided learning scenarios.
BMFT: Achieving Fairness via Bias-based Weight Masking Fine-tuning
Aug 13, 2024Developing models with robust group fairness properties is paramount, particularly in ethically sensitive domains such as medical diagnosis. Recent approaches to achieving fairness in machine learning require a substantial amount of training data and depend on model retraining, which may not be practical in real-world scenarios. To mitigate these challenges, we propose Bias-based Weight Masking Fine-Tuning (BMFT), a novel post-processing method that enhances the fairness of a trained model in significantly fewer epochs without requiring access to the original training data. BMFT produces a mask over model parameters, which efficiently identifies the weights contributing the most towards biased predictions. Furthermore, we propose a two-step debiasing strategy, wherein the feature extractor undergoes initial fine-tuning on the identified bias-influenced weights, succeeded by a fine-tuning phase on a reinitialised classification layer to uphold discriminative performance. Extensive experiments across four dermatological datasets and two sensitive attributes demonstrate that BMFT outperforms existing state-of-the-art (SOTA) techniques in both diagnostic accuracy and fairness metrics. Our findings underscore the efficacy and robustness of BMFT in advancing fairness across various out-of-distribution (OOD) settings. Our code is available at: https://github.com/vios-s/BMFT
Erase to Enhance: Data-Efficient Machine Unlearning in MRI Reconstruction
May 24, 2024



Machine unlearning is a promising paradigm for removing unwanted data samples from a trained model, towards ensuring compliance with privacy regulations and limiting harmful biases. Although unlearning has been shown in, e.g., classification and recommendation systems, its potential in medical image-to-image translation, specifically in image recon-struction, has not been thoroughly investigated. This paper shows that machine unlearning is possible in MRI tasks and has the potential to benefit for bias removal. We set up a protocol to study how much shared knowledge exists between datasets of different organs, allowing us to effectively quantify the effect of unlearning. Our study reveals that combining training data can lead to hallucinations and reduced image quality in the reconstructed data. We use unlearning to remove hallucinations as a proxy exemplar of undesired data removal. Indeed, we show that machine unlearning is possible without full retraining. Furthermore, our observations indicate that maintaining high performance is feasible even when using only a subset of retain data. We have made our code publicly accessible.
Fine-grained MRI Reconstruction using Attentive Selection Generative Adversarial Networks
Mar 13, 2021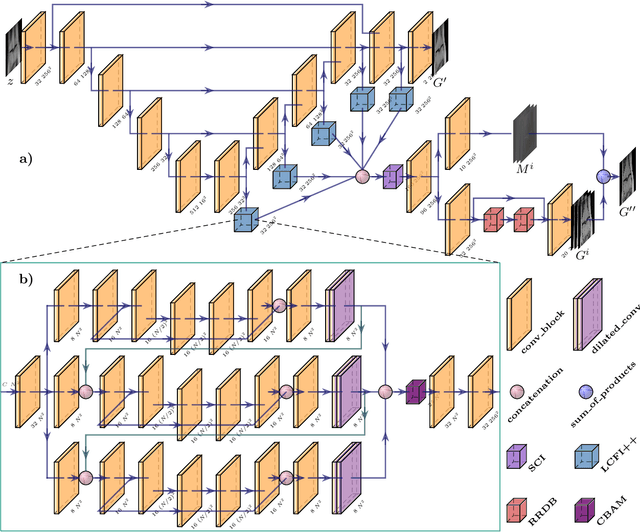
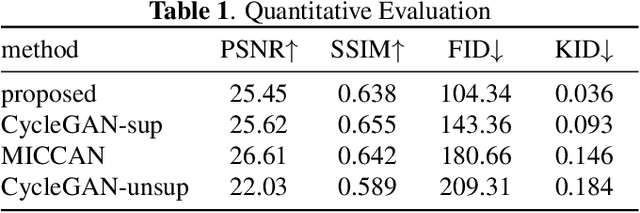
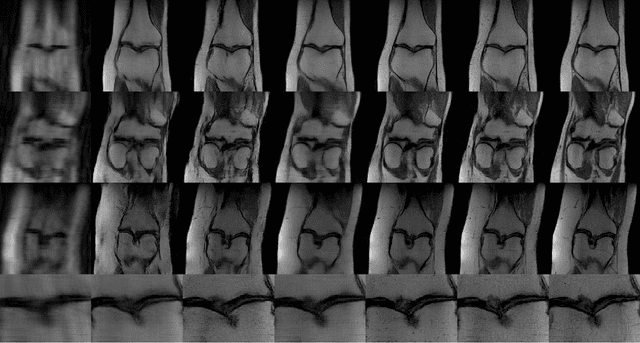
Compressed sensing (CS) leverages the sparsity prior to provide the foundation for fast magnetic resonance imaging (fastMRI). However, iterative solvers for ill-posed problems hinder their adaption to time-critical applications. Moreover, such a prior can be neither rich to capture complicated anatomical structures nor applicable to meet the demand of high-fidelity reconstructions in modern MRI. Inspired by the state-of-the-art methods in image generation, we propose a novel attention-based deep learning framework to provide high-quality MRI reconstruction. We incorporate large-field contextual feature integration and attention selection in a generative adversarial network (GAN) framework. We demonstrate that the proposed model can produce superior results compared to other deep learning-based methods in terms of image quality, and relevance to the MRI reconstruction in an extremely low sampling rate diet.