 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWiFT: Soft-Mask Weight Fine-tuning for Bias Mitigation
Aug 26, 2025Recent studies have shown that Machine Learning (ML) models can exhibit bias in real-world scenarios, posing significant challenges in ethically sensitive domains such as healthcare. Such bias can negatively affect model fairness, model generalization abilities and further risks amplifying social discrimination. There is a need to remove biases from trained models. Existing debiasing approaches often necessitate access to original training data and need extensive model retraining; they also typically exhibit trade-offs between model fairness and discriminative performance. To address these challenges, we propose Soft-Mask Weight Fine-Tuning (SWiFT), a debiasing framework that efficiently improves fairness while preserving discriminative performance with much less debiasing costs. Notably, SWiFT requires only a small external dataset and only a few epochs of model fine-tuning. The idea behind SWiFT is to first find the relative, and yet distinct, contributions of model parameters to both bias and predictive performance. Then, a two-step fine-tuning process updates each parameter with different gradient flows defined by its contribution. Extensive experiments with three bias sensitive attributes (gender, skin tone, and age) across four dermatological and two chest X-ray datasets demonstrate that SWiFT can consistently reduce model bias while achieving competitive or even superior diagnostic accuracy under common fairness and accuracy metrics, compared to the state-of-the-art. Specifically, we demonstrate improved model generalization ability as evidenced by superior performance on several out-of-distribution (OOD) datasets.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2025:015
CRCE: Coreference-Retention Concept Erasure in Text-to-Image Diffusion Models
Mar 18, 2025Text-to-Image diffusion models can produce undesirable content that necessitates concept erasure techniques. However, existing methods struggle with under-erasure, leaving residual traces of targeted concepts, or over-erasure, mistakenly eliminating unrelated but visually similar concepts. To address these limitations, we introduce CRCE, a novel concept erasure framework that leverages Large Language Models to identify both semantically related concepts that should be erased alongside the target and distinct concepts that should be preserved. By explicitly modeling coreferential and retained concepts semantically, CRCE enables more precise concept removal, without unintended erasure. Experiments demonstrate that CRCE outperforms existing methods on diverse erasure tasks.
BMFT: Achieving Fairness via Bias-based Weight Masking Fine-tuning
Aug 13, 2024Developing models with robust group fairness properties is paramount, particularly in ethically sensitive domains such as medical diagnosis. Recent approaches to achieving fairness in machine learning require a substantial amount of training data and depend on model retraining, which may not be practical in real-world scenarios. To mitigate these challenges, we propose Bias-based Weight Masking Fine-Tuning (BMFT), a novel post-processing method that enhances the fairness of a trained model in significantly fewer epochs without requiring access to the original training data. BMFT produces a mask over model parameters, which efficiently identifies the weights contributing the most towards biased predictions. Furthermore, we propose a two-step debiasing strategy, wherein the feature extractor undergoes initial fine-tuning on the identified bias-influenced weights, succeeded by a fine-tuning phase on a reinitialised classification layer to uphold discriminative performance. Extensive experiments across four dermatological datasets and two sensitive attributes demonstrate that BMFT outperforms existing state-of-the-art (SOTA) techniques in both diagnostic accuracy and fairness metrics. Our findings underscore the efficacy and robustness of BMFT in advancing fairness across various out-of-distribution (OOD) settings. Our code is available at: https://github.com/vios-s/BMFT
ASteISR: Adapting Single Image Super-resolution Pre-trained Model for Efficient Stereo Image Super-resolution
Jul 04, 2024Despite advances in the paradigm of pre-training then fine-tuning in low-level vision tasks, significant challenges persist particularly regarding the increased size of pre-trained models such as memory usage and training time. Another concern often encountered is the unsatisfying results yielded when directly applying pre-trained single-image models to multi-image domain. In this paper, we propose a efficient method for transferring a pre-trained single-image super-resolution (SISR) transformer network to the domain of stereo image super-resolution (SteISR) through a parameter-efficient fine-tuning (PEFT) method. Specifically, we introduce the concept of stereo adapters and spatial adapters which are incorporated into the pre-trained SISR transformer network. Subsequently, the pre-trained SISR model is frozen, enabling us to fine-tune the adapters using stereo datasets along. By adopting this training method, we enhance the ability of the SISR model to accurately infer stereo images by 0.79dB on the Flickr1024 dataset. This method allows us to train only 4.8% of the original model parameters, achieving state-of-the-art performance on four commonly used SteISR benchmarks. Compared to the more complicated full fine-tuning approach, our method reduces training time and memory consumption by 57% and 15%, respectively.
Erase to Enhance: Data-Efficient Machine Unlearning in MRI Reconstruction
May 24, 2024



Machine unlearning is a promising paradigm for removing unwanted data samples from a trained model, towards ensuring compliance with privacy regulations and limiting harmful biases. Although unlearning has been shown in, e.g., classification and recommendation systems, its potential in medical image-to-image translation, specifically in image recon-struction, has not been thoroughly investigated. This paper shows that machine unlearning is possible in MRI tasks and has the potential to benefit for bias removal. We set up a protocol to study how much shared knowledge exists between datasets of different organs, allowing us to effectively quantify the effect of unlearning. Our study reveals that combining training data can lead to hallucinations and reduced image quality in the reconstructed data. We use unlearning to remove hallucinations as a proxy exemplar of undesired data removal. Indeed, we show that machine unlearning is possible without full retraining. Furthermore, our observations indicate that maintaining high performance is feasible even when using only a subset of retain data. We have made our code publicly accessible.
The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024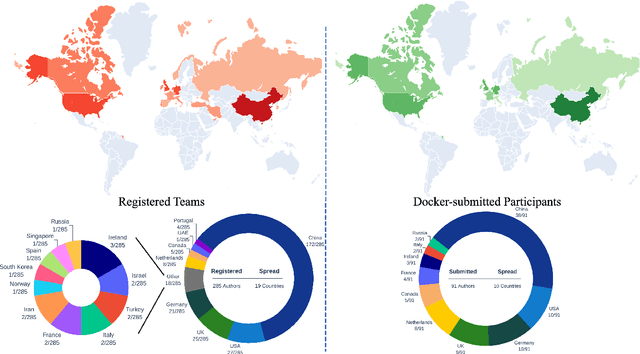
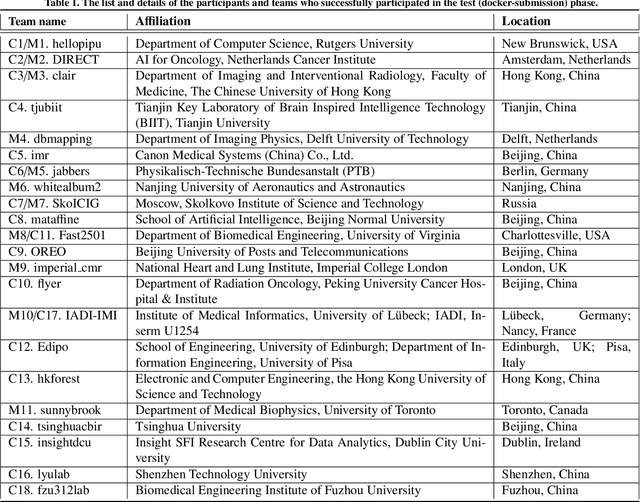
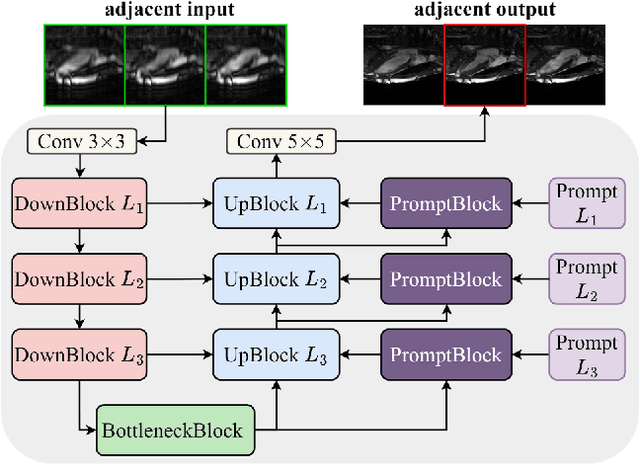
Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
Inference Stage Denoising for Undersampled MRI Reconstruction
Feb 12, 2024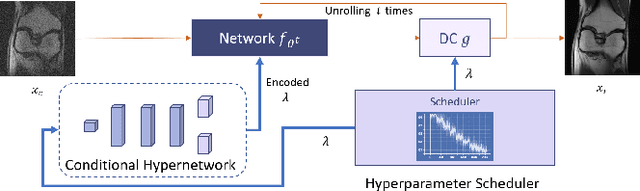


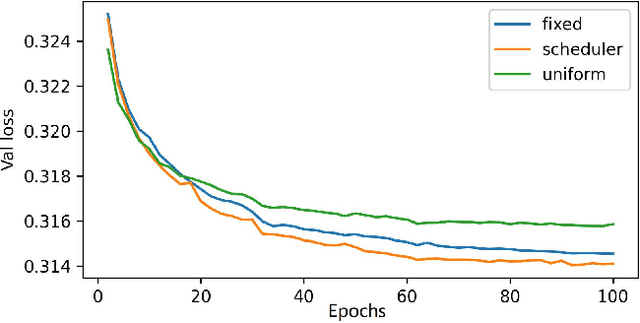
Reconstruction of magnetic resonance imaging (MRI) data has been positively affected by deep learning. A key challenge remains: to improve generalisation to distribution shifts between the training and testing data. Most approaches aim to address this via inductive design or data augmentation. However, they can be affected by misleading data, e.g. random noise, and cases where the inference stage data do not match assumptions in the modelled shifts. In this work, by employing a conditional hyperparameter network, we eliminate the need of augmentation, yet maintain robust performance under various levels of Gaussian noise. We demonstrate that our model withstands various input noise levels while producing high-definition reconstructions during the test stage. Moreover, we present a hyperparameter sampling strategy that accelerates the convergence of training. Our proposed method achieves the highest accuracy and image quality in all settings compared to baseline methods.
Toward Real World Stereo Image Super-Resolution via Hybrid Degradation Model and Discriminator for Implied Stereo Image Information
Dec 13, 2023Real-world stereo image super-resolution has a significant influence on enhancing the performance of computer vision systems. Although existing methods for single-image super-resolution can be applied to improve stereo images, these methods often introduce notable modifications to the inherent disparity, resulting in a loss in the consistency of disparity between the original and the enhanced stereo images. To overcome this limitation, this paper proposes a novel approach that integrates a implicit stereo information discriminator and a hybrid degradation model. This combination ensures effective enhancement while preserving disparity consistency. The proposed method bridges the gap between the complex degradations in real-world stereo domain and the simpler degradations in real-world single-image super-resolution domain. Our results demonstrate impressive performance on synthetic and real datasets, enhancing visual perception while maintaining disparity consistency. The complete code is available at the following \href{https://github.com/fzuzyb/SCGLANet}{link}.
Unveiling Fairness Biases in Deep Learning-Based Brain MRI Reconstruction
Sep 25, 2023Deep learning (DL) reconstruction particularly of MRI has led to improvements in image fidelity and reduction of acquisition time. In neuroimaging, DL methods can reconstruct high-quality images from undersampled data. However, it is essential to consider fairness in DL algorithms, particularly in terms of demographic characteristics. This study presents the first fairness analysis in a DL-based brain MRI reconstruction model. The model utilises the U-Net architecture for image reconstruction and explores the presence and sources of unfairness by implementing baseline Empirical Risk Minimisation (ERM) and rebalancing strategies. Model performance is evaluated using image reconstruction metrics. Our findings reveal statistically significant performance biases between the gender and age subgroups. Surprisingly, data imbalance and training discrimination are not the main sources of bias. This analysis provides insights of fairness in DL-based image reconstruction and aims to improve equity in medical AI applications.
Cine cardiac MRI reconstruction using a convolutional recurrent network with refinement
Sep 23, 2023Cine Magnetic Resonance Imaging (MRI) allows for understanding of the heart's function and condition in a non-invasive manner. Undersampling of the $k$-space is employed to reduce the scan duration, thus increasing patient comfort and reducing the risk of motion artefacts, at the cost of reduced image quality. In this challenge paper, we investigate the use of a convolutional recurrent neural network (CRNN) architecture to exploit temporal correlations in supervised cine cardiac MRI reconstruction. This is combined with a single-image super-resolution refinement module to improve single coil reconstruction by 4.4\% in structural similarity and 3.9\% in normalised mean square error compared to a plain CRNN implementation. We deploy a high-pass filter to our $\ell_1$ loss to allow greater emphasis on high-frequency details which are missing in the original data. The proposed model demonstrates considerable enhancements compared to the baseline case and holds promising potential for further improving cardiac MRI reconstruction.