 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Generalization through Prioritization and Diversity in Self-Imitation Reinforcement Learning over Procedural Environments with Sparse Rewards
Paper and Code
Nov 01, 2023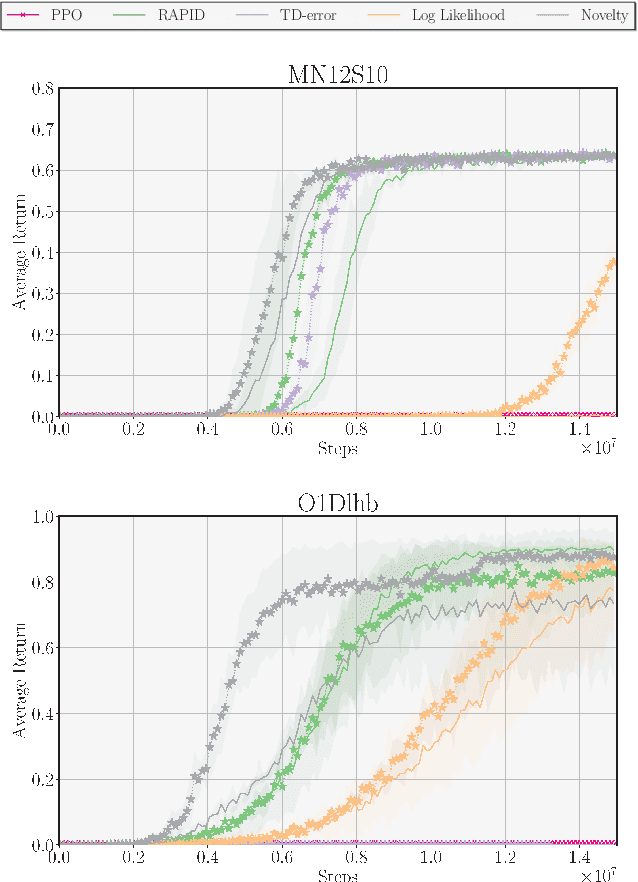
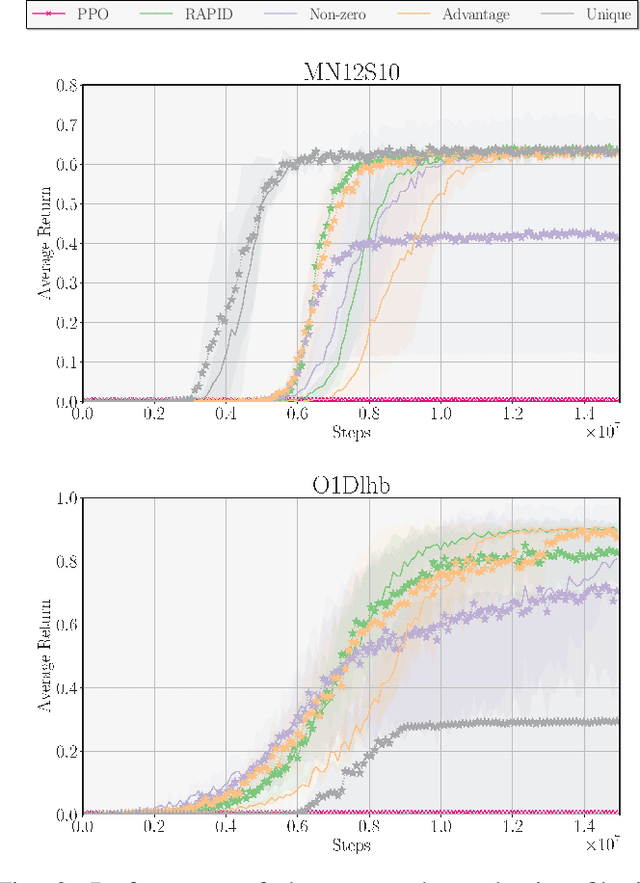

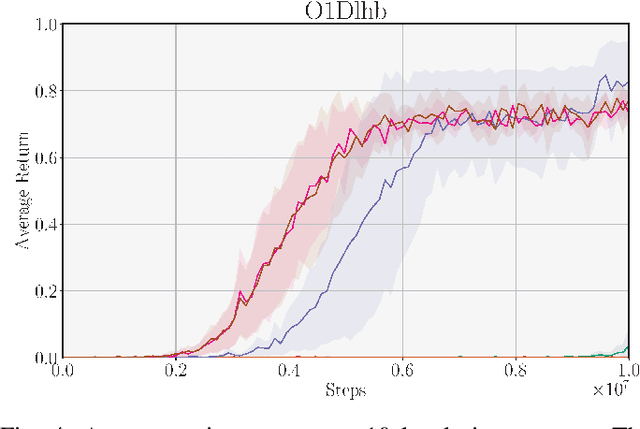
Exploration poses a fundamental challenge in Reinforcement Learning (RL) with sparse rewards, limiting an agent's ability to learn optimal decision-making due to a lack of informative feedback signals. Self-Imitation Learning (self-IL) has emerged as a promising approach for exploration, leveraging a replay buffer to store and reproduce successful behaviors. However, traditional self-IL methods, which rely on high-return transitions and assume singleton environments, face challenges in generalization, especially in procedurally-generated (PCG) environments. Therefore, new self-IL methods have been proposed to rank which experiences to persist, but they replay transitions uniformly regardless of their significance, and do not address the diversity of the stored demonstrations. In this work, we propose tailored self-IL sampling strategies by prioritizing transitions in different ways and extending prioritization techniques to PCG environments. We also address diversity loss through modifications to counteract the impact of generalization requirements and bias introduced by prioritization techniques. Our experimental analysis, conducted over three PCG sparse reward environments, including MiniGrid and ProcGen, highlights the benefits of our proposed modifications, achieving a new state-of-the-art performance in the MiniGrid-MultiRoom-N12-S10 environment.