 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Autoregressive Video Generation with Diagonal Decoding
Mar 18, 2025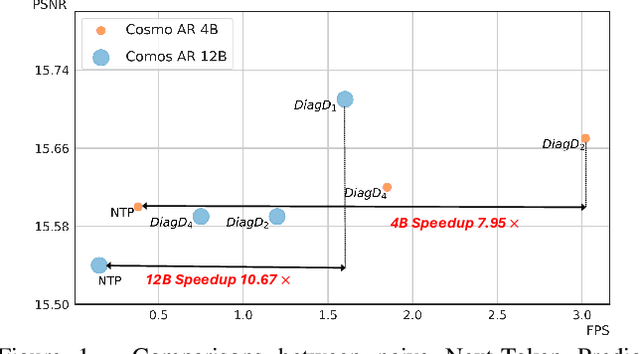
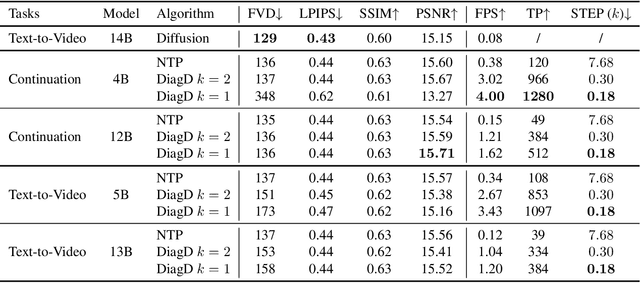
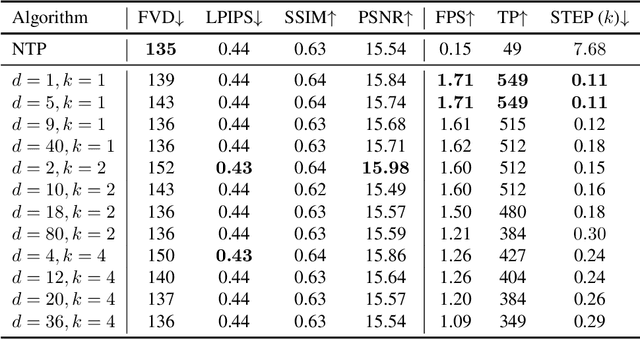
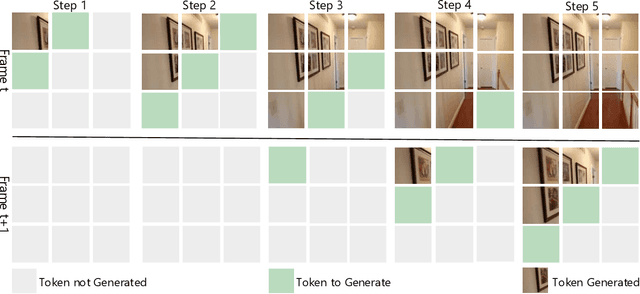
Autoregressive Transformer models have demonstrated impressive performance in video generation, but their sequential token-by-token decoding process poses a major bottleneck, particularly for long videos represented by tens of thousands of tokens. In this paper, we propose Diagonal Decoding (DiagD), a training-free inference acceleration algorithm for autoregressively pre-trained models that exploits spatial and temporal correlations in videos. Our method generates tokens along diagonal paths in the spatial-temporal token grid, enabling parallel decoding within each frame as well as partially overlapping across consecutive frames. The proposed algorithm is versatile and adaptive to various generative models and tasks, while providing flexible control over the trade-off between inference speed and visual quality. Furthermore, we propose a cost-effective finetuning strategy that aligns the attention patterns of the model with our decoding order, further mitigating the training-inference gap on small-scale models. Experiments on multiple autoregressive video generation models and datasets demonstrate that DiagD achieves up to $10\times$ speedup compared to naive sequential decoding, while maintaining comparable visual fidelity.
Scaling Laws for Pre-training Agents and World Models
Nov 07, 2024



The performance of embodied agents has been shown to improve by increasing model parameters, dataset size, and compute. This has been demonstrated in domains from robotics to video games, when generative learning objectives on offline datasets (pre-training) are used to model an agent's behavior (imitation learning) or their environment (world modeling). This paper characterizes the role of scale in these tasks more precisely. Going beyond the simple intuition that `bigger is better', we show that the same types of power laws found in language modeling (e.g. between loss and optimal model size), also arise in world modeling and imitation learning. However, the coefficients of these laws are heavily influenced by the tokenizer, task \& architecture -- this has important implications on the optimal sizing of models and data.
Aligning Agents like Large Language Models
Jun 06, 2024Training agents to behave as desired in complex 3D environments from high-dimensional sensory information is challenging. Imitation learning from diverse human behavior provides a scalable approach for training an agent with a sensible behavioral prior, but such an agent may not perform the specific behaviors of interest when deployed. To address this issue, we draw an analogy between the undesirable behaviors of imitation learning agents and the unhelpful responses of unaligned large language models (LLMs). We then investigate how the procedure for aligning LLMs can be applied to aligning agents in a 3D environment from pixels. For our analysis, we utilize an academically illustrative part of a modern console game in which the human behavior distribution is multi-modal, but we want our agent to imitate a single mode of this behavior. We demonstrate that we can align our agent to consistently perform the desired mode, while providing insights and advice for successfully applying this approach to training agents. Project webpage at https://adamjelley.github.io/aligning-agents-like-llms .
Visual Encoders for Data-Efficient Imitation Learning in Modern Video Games
Dec 04, 2023Video games have served as useful benchmarks for the decision making community, but going beyond Atari games towards training agents in modern games has been prohibitively expensive for the vast majority of the research community. Recent progress in the research, development and open release of large vision models has the potential to amortize some of these costs across the community. However, it is currently unclear which of these models have learnt representations that retain information critical for sequential decision making. Towards enabling wider participation in the research of gameplaying agents in modern games, we present a systematic study of imitation learning with publicly available visual encoders compared to the typical, task-specific, end-to-end training approach in Minecraft, Minecraft Dungeons and Counter-Strike: Global Offensive.
Imitating Human Behaviour with Diffusion Models
Jan 25, 2023



Diffusion models have emerged as powerful generative models in the text-to-image domain. This paper studies their application as observation-to-action models for imitating human behaviour in sequential environments. Human behaviour is stochastic and multimodal, with structured correlations between action dimensions. Meanwhile, standard modelling choices in behaviour cloning are limited in their expressiveness and may introduce bias into the cloned policy. We begin by pointing out the limitations of these choices. We then propose that diffusion models are an excellent fit for imitating human behaviour, since they learn an expressive distribution over the joint action space. We introduce several innovations to make diffusion models suitable for sequential environments; designing suitable architectures, investigating the role of guidance, and developing reliable sampling strategies. Experimentally, diffusion models closely match human demonstrations in a simulated robotic control task and a modern 3D gaming environment.
* Published in ICLR 2023
Softmax with Regularization: Better Value Estimation in Multi-Agent Reinforcement Learning
Mar 22, 2021

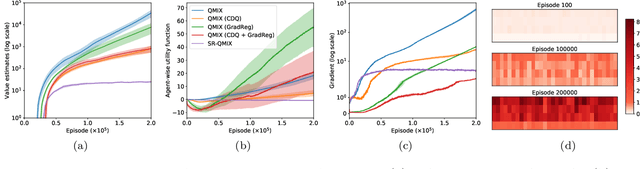

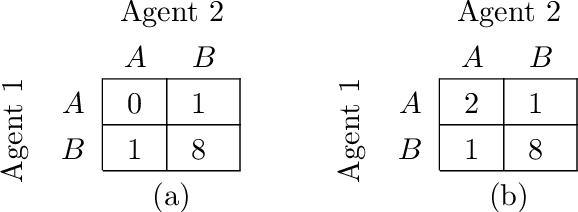
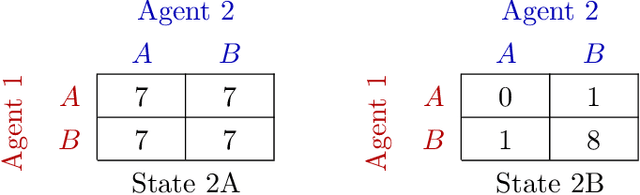
Overestimation in $Q$-learning is an important problem that has been extensively studied in single-agent reinforcement learning, but has received comparatively little attention in the multi-agent setting. In this work, we empirically demonstrate that QMIX, a popular $Q$-learning algorithm for cooperative multi-agent reinforcement learning (MARL), suffers from a particularly severe overestimation problem which is not mitigated by existing approaches. We rectify this by designing a novel regularization-based update scheme that penalizes large joint action-values deviating from a baseline and demonstrate its effectiveness in stabilizing learning. We additionally propose to employ a softmax operator, which we efficiently approximate in the multi-agent setting, to further reduce the potential overestimation bias. We demonstrate that our Softmax with Regularization (SR) method, when applied to QMIX, accomplishes its goal of avoiding severe overestimation and significantly improves performance in a variety of cooperative multi-agent tasks. To demonstrate the versatility of our method, we apply it to other $Q$-learning based MARL algorithms and achieve similar performance gains. Finally, we show that our method provides a consistent performance improvement on a set of challenging StarCraft II micromanagement tasks.
Estimating $α$-Rank by Maximizing Information Gain
Jan 22, 2021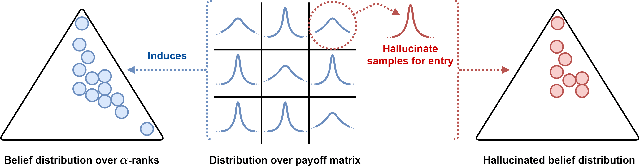
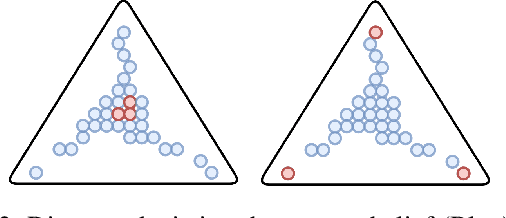
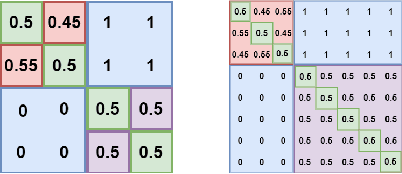
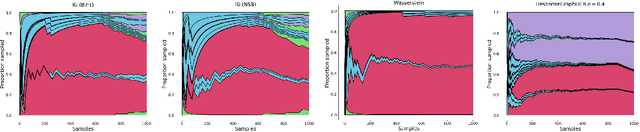
Game theory has been increasingly applied in settings where the game is not known outright, but has to be estimated by sampling. For example, meta-games that arise in multi-agent evaluation can only be accessed by running a succession of expensive experiments that may involve simultaneous deployment of several agents. In this paper, we focus on $\alpha$-rank, a popular game-theoretic solution concept designed to perform well in such scenarios. We aim to estimate the $\alpha$-rank of the game using as few samples as possible. Our algorithm maximizes information gain between an epistemic belief over the $\alpha$-ranks and the observed payoff. This approach has two main benefits. First, it allows us to focus our sampling on the entries that matter the most for identifying the $\alpha$-rank. Second, the Bayesian formulation provides a facility to build in modeling assumptions by using a prior over game payoffs. We show the benefits of using information gain as compared to the confidence interval criterion of ResponseGraphUCB (Rowland et al. 2019), and provide theoretical results justifying our method.
Weighted QMIX: Expanding Monotonic Value Function Factorisation
Jun 18, 2020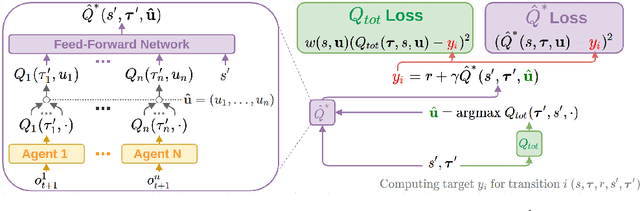
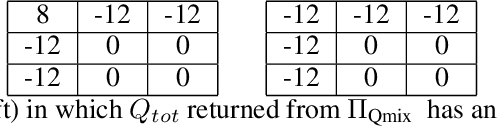
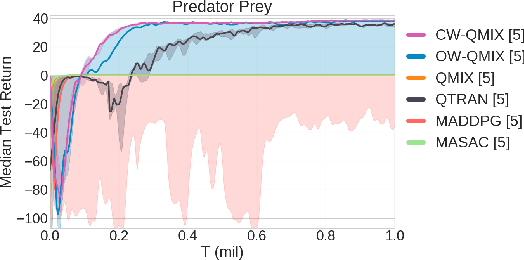

QMIX is a popular $Q$-learning algorithm for cooperative MARL in the centralised training and decentralised execution paradigm. In order to enable easy decentralisation, QMIX restricts the joint action $Q$-values it can represent to be a monotonic mixing of each agent's utilities. However, this restriction prevents it from representing value functions in which an agent's ordering over its actions can depend on other agents' actions. To analyse this representational limitation, we first formalise the objective QMIX optimises, which allows us to view QMIX as an operator that first computes the $Q$-learning targets and then projects them into the space representable by QMIX. This projection returns a representable $Q$-value that minimises the unweighted squared error across all joint actions. We show in particular that this projection can fail to recover the optimal policy even with access to $Q^*$, which primarily stems from the equal weighting placed on each joint action. We rectify this by introducing a weighting into the projection, in order to place more importance on the better joint actions. We propose two weighting schemes and prove that they recover the correct maximal action for any joint action $Q$-values, and therefore for $Q^*$ as well. Based on our analysis and results in the tabular setting we introduce two scalable versions of our algorithm, Centrally-Weighted (CW) QMIX and Optimistically-Weighted (OW) QMIX and demonstrate improved performance on both predator-prey and challenging multi-agent StarCraft benchmark tasks.
Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
Mar 19, 2020
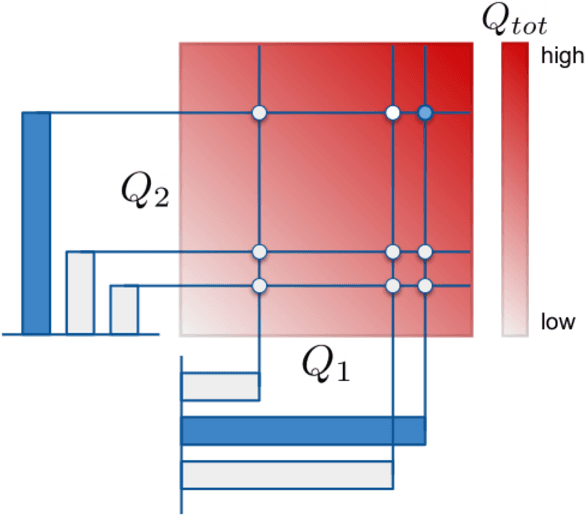
In many real-world settings, a team of agents must coordinate its behaviour while acting in a decentralised fashion. At the same time, it is often possible to train the agents in a centralised fashion where global state information is available and communication constraints are lifted. Learning joint action-values conditioned on extra state information is an attractive way to exploit centralised learning, but the best strategy for then extracting decentralised policies is unclear. Our solution is QMIX, a novel value-based method that can train decentralised policies in a centralised end-to-end fashion. QMIX employs a mixing network that estimates joint action-values as a monotonic combination of per-agent values. We structurally enforce that the joint-action value is monotonic in the per-agent values, through the use of non-negative weights in the mixing network, which guarantees consistency between the centralised and decentralised policies. To evaluate the performance of QMIX, we propose the StarCraft Multi-Agent Challenge (SMAC) as a new benchmark for deep multi-agent reinforcement learning. We evaluate QMIX on a challenging set of SMAC scenarios and show that it significantly outperforms existing multi-agent reinforcement learning methods.
Optimistic Exploration even with a Pessimistic Initialisation
Feb 26, 2020



Optimistic initialisation is an effective strategy for efficient exploration in reinforcement learning (RL). In the tabular case, all provably efficient model-free algorithms rely on it. However, model-free deep RL algorithms do not use optimistic initialisation despite taking inspiration from these provably efficient tabular algorithms. In particular, in scenarios with only positive rewards, Q-values are initialised at their lowest possible values due to commonly used network initialisation schemes, a pessimistic initialisation. Merely initialising the network to output optimistic Q-values is not enough, since we cannot ensure that they remain optimistic for novel state-action pairs, which is crucial for exploration. We propose a simple count-based augmentation to pessimistically initialised Q-values that separates the source of optimism from the neural network. We show that this scheme is provably efficient in the tabular setting and extend it to the deep RL setting. Our algorithm, Optimistic Pessimistically Initialised Q-Learning (OPIQ), augments the Q-value estimates of a DQN-based agent with count-derived bonuses to ensure optimism during both action selection and bootstrapping. We show that OPIQ outperforms non-optimistic DQN variants that utilise a pseudocount-based intrinsic motivation in hard exploration tasks, and that it predicts optimistic estimates for novel state-action pairs.