 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftmax with Regularization: Better Value Estimation in Multi-Agent Reinforcement Learning
Paper and Code


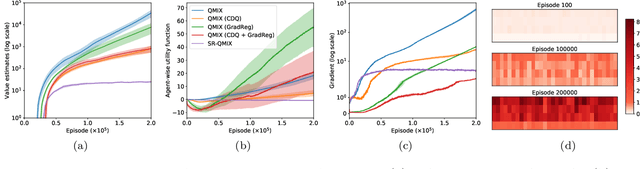

Overestimation in $Q$-learning is an important problem that has been extensively studied in single-agent reinforcement learning, but has received comparatively little attention in the multi-agent setting. In this work, we empirically demonstrate that QMIX, a popular $Q$-learning algorithm for cooperative multi-agent reinforcement learning (MARL), suffers from a particularly severe overestimation problem which is not mitigated by existing approaches. We rectify this by designing a novel regularization-based update scheme that penalizes large joint action-values deviating from a baseline and demonstrate its effectiveness in stabilizing learning. We additionally propose to employ a softmax operator, which we efficiently approximate in the multi-agent setting, to further reduce the potential overestimation bias. We demonstrate that our Softmax with Regularization (SR) method, when applied to QMIX, accomplishes its goal of avoiding severe overestimation and significantly improves performance in a variety of cooperative multi-agent tasks. To demonstrate the versatility of our method, we apply it to other $Q$-learning based MARL algorithms and achieve similar performance gains. Finally, we show that our method provides a consistent performance improvement on a set of challenging StarCraft II micromanagement tasks.