 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Additively Compositional Latent Actions for Embodied AI
Apr 03, 2026Latent action learning infers pseudo-action labels from visual transitions, providing an approach to leverage internet-scale video for embodied AI. However, most methods learn latent actions without structural priors that encode the additive, compositional structure of physical motion. As a result, latents often entangle irrelevant scene details or information about future observations with true state changes and miscalibrate motion magnitude. We introduce Additively Compositional Latent Action Model (AC-LAM), which enforces scene-wise additive composition structure over short horizons on the latent action space. These AC constraints encourage simple algebraic structure in the latent action space~(identity, inverse, cycle consistency) and suppress information that does not compose additively. Empirically, AC-LAM learns more structured, motion-specific, and displacement-calibrated latent actions and provides stronger supervision for downstream policy learning, outperforming state-of-the-art LAMs across simulated and real-world tabletop tasks.
Beyond Pixel Histories: World Models with Persistent 3D State
Mar 03, 2026Interactive world models continually generate video by responding to a user's actions, enabling open-ended generation capabilities. However, existing models typically lack a 3D representation of the environment, meaning 3D consistency must be implicitly learned from data, and spatial memory is restricted to limited temporal context windows. This results in an unrealistic user experience and presents significant obstacles to down-stream tasks such as training agents. To address this, we present PERSIST, a new paradigm of world model which simulates the evolution of a latent 3D scene: environment, camera, and renderer. This allows us to synthesize new frames with persistent spatial memory and consistent geometry. Both quantitative metrics and a qualitative user study show substantial improvements in spatial memory, 3D consistency, and long-horizon stability over existing methods, enabling coherent, evolving 3D worlds. We further demonstrate novel capabilities, including synthesising diverse 3D environments from a single image, as well as enabling fine-grained, geometry-aware control over generated experiences by supporting environment editing and specification directly in 3D space. Project page: https://francelico.github.io/persist.github.io
MineWorld: a Real-Time and Open-Source Interactive World Model on Minecraft
Apr 11, 2025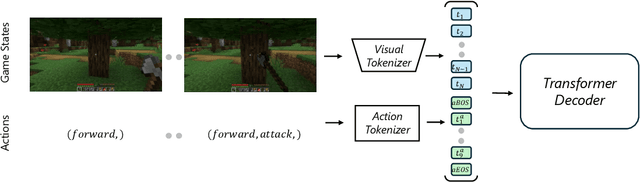

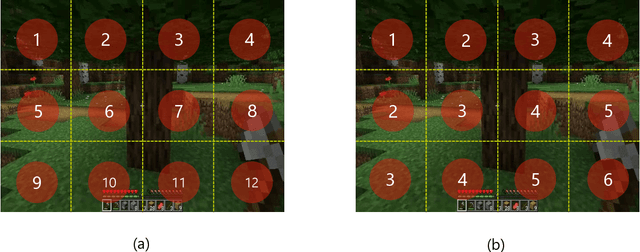
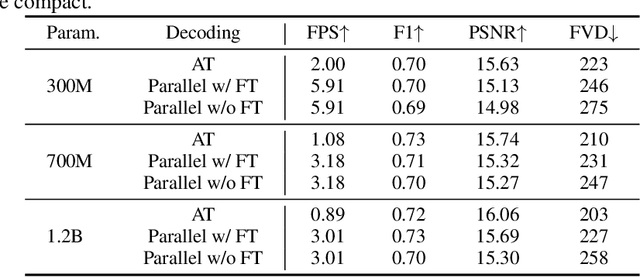
World modeling is a crucial task for enabling intelligent agents to effectively interact with humans and operate in dynamic environments. In this work, we propose MineWorld, a real-time interactive world model on Minecraft, an open-ended sandbox game which has been utilized as a common testbed for world modeling. MineWorld is driven by a visual-action autoregressive Transformer, which takes paired game scenes and corresponding actions as input, and generates consequent new scenes following the actions. Specifically, by transforming visual game scenes and actions into discrete token ids with an image tokenizer and an action tokenizer correspondingly, we consist the model input with the concatenation of the two kinds of ids interleaved. The model is then trained with next token prediction to learn rich representations of game states as well as the conditions between states and actions simultaneously. In inference, we develop a novel parallel decoding algorithm that predicts the spatial redundant tokens in each frame at the same time, letting models in different scales generate $4$ to $7$ frames per second and enabling real-time interactions with game players. In evaluation, we propose new metrics to assess not only visual quality but also the action following capacity when generating new scenes, which is crucial for a world model. Our comprehensive evaluation shows the efficacy of MineWorld, outperforming SoTA open-sourced diffusion based world models significantly. The code and model have been released.
Fast Autoregressive Video Generation with Diagonal Decoding
Mar 18, 2025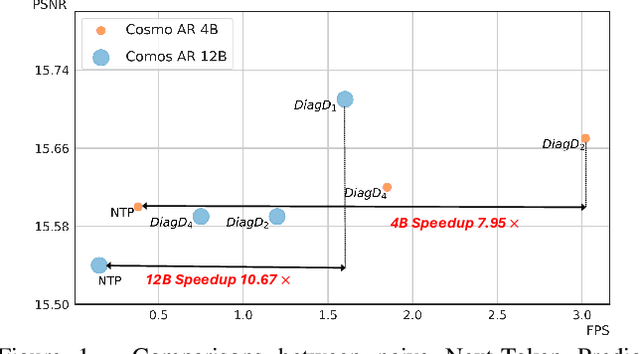
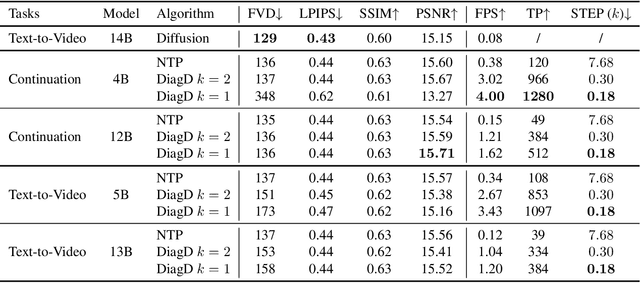
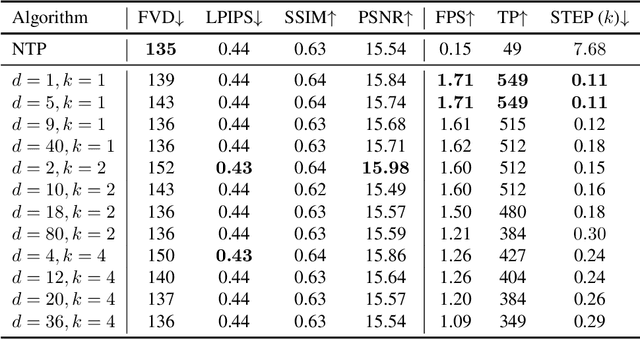
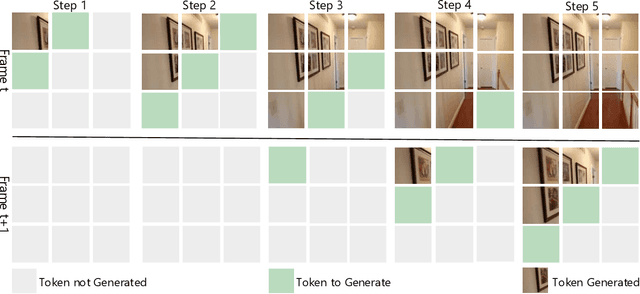
Autoregressive Transformer models have demonstrated impressive performance in video generation, but their sequential token-by-token decoding process poses a major bottleneck, particularly for long videos represented by tens of thousands of tokens. In this paper, we propose Diagonal Decoding (DiagD), a training-free inference acceleration algorithm for autoregressively pre-trained models that exploits spatial and temporal correlations in videos. Our method generates tokens along diagonal paths in the spatial-temporal token grid, enabling parallel decoding within each frame as well as partially overlapping across consecutive frames. The proposed algorithm is versatile and adaptive to various generative models and tasks, while providing flexible control over the trade-off between inference speed and visual quality. Furthermore, we propose a cost-effective finetuning strategy that aligns the attention patterns of the model with our decoding order, further mitigating the training-inference gap on small-scale models. Experiments on multiple autoregressive video generation models and datasets demonstrate that DiagD achieves up to $10\times$ speedup compared to naive sequential decoding, while maintaining comparable visual fidelity.
Scaling Laws for Pre-training Agents and World Models
Nov 07, 2024



The performance of embodied agents has been shown to improve by increasing model parameters, dataset size, and compute. This has been demonstrated in domains from robotics to video games, when generative learning objectives on offline datasets (pre-training) are used to model an agent's behavior (imitation learning) or their environment (world modeling). This paper characterizes the role of scale in these tasks more precisely. Going beyond the simple intuition that `bigger is better', we show that the same types of power laws found in language modeling (e.g. between loss and optimal model size), also arise in world modeling and imitation learning. However, the coefficients of these laws are heavily influenced by the tokenizer, task \& architecture -- this has important implications on the optimal sizing of models and data.
Reconciling Kaplan and Chinchilla Scaling Laws
Jun 12, 2024



Kaplan et al. [2020] (`Kaplan') and Hoffmann et al. [2022] (`Chinchilla') studied the scaling behavior of transformers trained on next-token language prediction. These studies produced different estimates for how the number of parameters ($N$) and training tokens ($D$) should be set to achieve the lowest possible loss for a given compute budget ($C$). Kaplan: $N_\text{optimal} \propto C^{0.73}$, Chinchilla: $N_\text{optimal} \propto C^{0.50}$. This note finds that much of this discrepancy can be attributed to Kaplan counting non-embedding rather than total parameters, combined with their analysis being performed at small scale. Simulating the Chinchilla study under these conditions produces biased scaling coefficients close to Kaplan's. Hence, this note reaffirms Chinchilla's scaling coefficients, by explaining the cause of Kaplan's original overestimation.
Diffusion for World Modeling: Visual Details Matter in Atari
May 20, 2024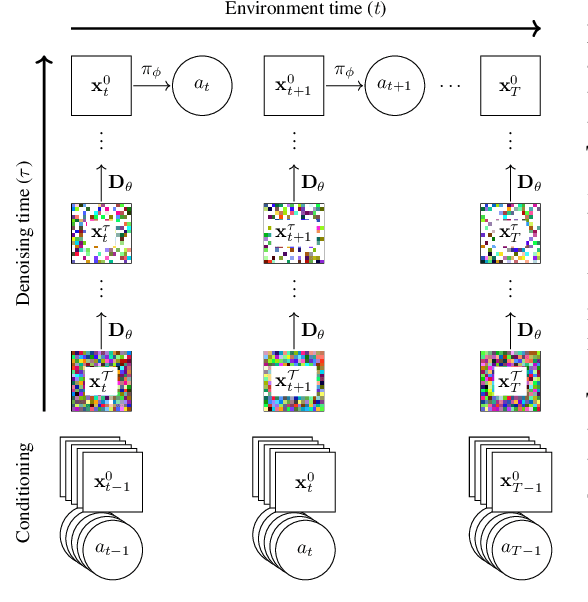
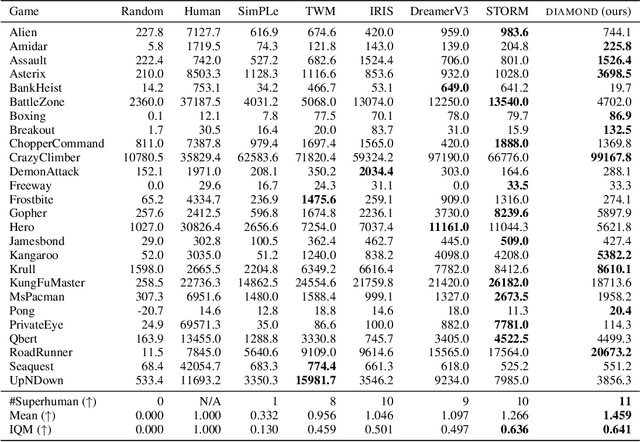
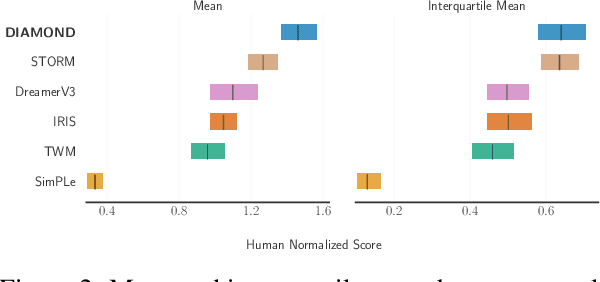
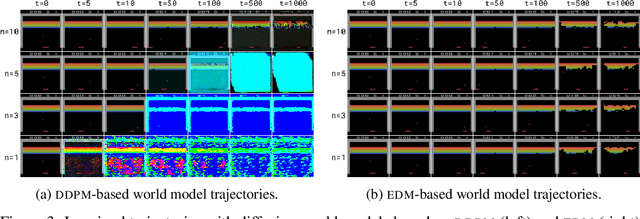
World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. To foster future research on diffusion for world modeling, we release our code, agents and playable world models at https://github.com/eloialonso/diamond.
C-GAIL: Stabilizing Generative Adversarial Imitation Learning with Control Theory
Feb 26, 2024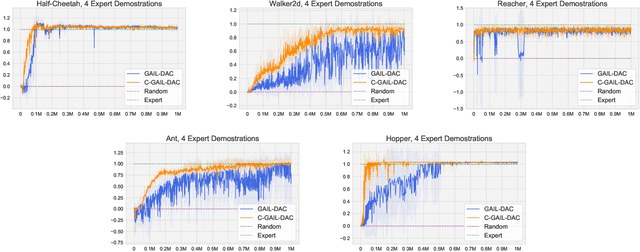

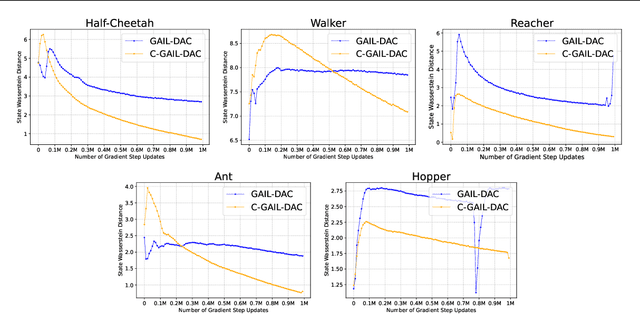
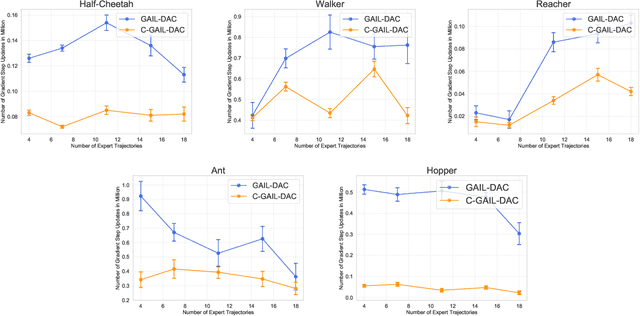
Generative Adversarial Imitation Learning (GAIL) trains a generative policy to mimic a demonstrator. It uses on-policy Reinforcement Learning (RL) to optimize a reward signal derived from a GAN-like discriminator. A major drawback of GAIL is its training instability - it inherits the complex training dynamics of GANs, and the distribution shift introduced by RL. This can cause oscillations during training, harming its sample efficiency and final policy performance. Recent work has shown that control theory can help with the convergence of a GAN's training. This paper extends this line of work, conducting a control-theoretic analysis of GAIL and deriving a novel controller that not only pushes GAIL to the desired equilibrium but also achieves asymptotic stability in a 'one-step' setting. Based on this, we propose a practical algorithm 'Controlled-GAIL' (C-GAIL). On MuJoCo tasks, our controlled variant is able to speed up the rate of convergence, reduce the range of oscillation and match the expert's distribution more closely both for vanilla GAIL and GAIL-DAC.
Fair collaborative vehicle routing: A deep multi-agent reinforcement learning approach
Oct 26, 2023Collaborative vehicle routing occurs when carriers collaborate through sharing their transportation requests and performing transportation requests on behalf of each other. This achieves economies of scale, thus reducing cost, greenhouse gas emissions and road congestion. But which carrier should partner with whom, and how much should each carrier be compensated? Traditional game theoretic solution concepts are expensive to calculate as the characteristic function scales exponentially with the number of agents. This would require solving the vehicle routing problem (NP-hard) an exponential number of times. We therefore propose to model this problem as a coalitional bargaining game solved using deep multi-agent reinforcement learning, where - crucially - agents are not given access to the characteristic function. Instead, we implicitly reason about the characteristic function; thus, when deployed in production, we only need to evaluate the expensive post-collaboration vehicle routing problem once. Our contribution is that we are the first to consider both the route allocation problem and gain sharing problem simultaneously - without access to the expensive characteristic function. Through decentralised machine learning, our agents bargain with each other and agree to outcomes that correlate well with the Shapley value - a fair profit allocation mechanism. Importantly, we are able to achieve a reduction in run-time of 88%.
* Final, published version can be found here: https://www.sciencedirect.com/science/article/pii/S0968090X23003662
Coalitional Bargaining via Reinforcement Learning: An Application to Collaborative Vehicle Routing
Oct 26, 2023Collaborative Vehicle Routing is where delivery companies cooperate by sharing their delivery information and performing delivery requests on behalf of each other. This achieves economies of scale and thus reduces cost, greenhouse gas emissions, and road congestion. But which company should partner with whom, and how much should each company be compensated? Traditional game theoretic solution concepts, such as the Shapley value or nucleolus, are difficult to calculate for the real-world problem of Collaborative Vehicle Routing due to the characteristic function scaling exponentially with the number of agents. This would require solving the Vehicle Routing Problem (an NP-Hard problem) an exponential number of times. We therefore propose to model this problem as a coalitional bargaining game where - crucially - agents are not given access to the characteristic function. Instead, we implicitly reason about the characteristic function, and thus eliminate the need to evaluate the VRP an exponential number of times - we only need to evaluate it once. Our contribution is that our decentralised approach is both scalable and considers the self-interested nature of companies. The agents learn using a modified Independent Proximal Policy Optimisation. Our RL agents outperform a strong heuristic bot. The agents correctly identify the optimal coalitions 79% of the time with an average optimality gap of 4.2% and reduction in run-time of 62%.