 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen does predictive inverse dynamics outperform behavior cloning?
Jan 29, 2026Behavior cloning (BC) is a practical offline imitation learning method, but it often fails when expert demonstrations are limited. Recent works have introduced a class of architectures named predictive inverse dynamics models (PIDM) that combine a future state predictor with an inverse dynamics model (IDM). While PIDM often outperforms BC, the reasons behind its benefits remain unclear. In this paper, we provide a theoretical explanation: PIDM introduces a bias-variance tradeoff. While predicting the future state introduces bias, conditioning the IDM on the prediction can significantly reduce variance. We establish conditions on the state predictor bias for PIDM to achieve lower prediction error and higher sample efficiency than BC, with the gap widening when additional data sources are available. We validate the theoretical insights empirically in 2D navigation tasks, where BC requires up to five times (three times on average) more demonstrations than PIDM to reach comparable performance; and in a complex 3D environment in a modern video game with high-dimensional visual inputs and stochastic transitions, where BC requires over 66\% more samples than PIDM.
Adapting a World Model for Trajectory Following in a 3D Game
Apr 16, 2025



Imitation learning is a powerful tool for training agents by leveraging expert knowledge, and being able to replicate a given trajectory is an integral part of it. In complex environments, like modern 3D video games, distribution shift and stochasticity necessitate robust approaches beyond simple action replay. In this study, we apply Inverse Dynamics Models (IDM) with different encoders and policy heads to trajectory following in a modern 3D video game -- Bleeding Edge. Additionally, we investigate several future alignment strategies that address the distribution shift caused by the aleatoric uncertainty and imperfections of the agent. We measure both the trajectory deviation distance and the first significant deviation point between the reference and the agent's trajectory and show that the optimal configuration depends on the chosen setting. Our results show that in a diverse data setting, a GPT-style policy head with an encoder trained from scratch performs the best, DINOv2 encoder with the GPT-style policy head gives the best results in the low data regime, and both GPT-style and MLP-style policy heads had comparable results when pre-trained on a diverse setting and fine-tuned for a specific behaviour setting.
Imitating Human Behaviour with Diffusion Models
Jan 25, 2023



Diffusion models have emerged as powerful generative models in the text-to-image domain. This paper studies their application as observation-to-action models for imitating human behaviour in sequential environments. Human behaviour is stochastic and multimodal, with structured correlations between action dimensions. Meanwhile, standard modelling choices in behaviour cloning are limited in their expressiveness and may introduce bias into the cloned policy. We begin by pointing out the limitations of these choices. We then propose that diffusion models are an excellent fit for imitating human behaviour, since they learn an expressive distribution over the joint action space. We introduce several innovations to make diffusion models suitable for sequential environments; designing suitable architectures, investigating the role of guidance, and developing reliable sampling strategies. Experimentally, diffusion models closely match human demonstrations in a simulated robotic control task and a modern 3D gaming environment.
* Published in ICLR 2023
Fully Distributed Actor-Critic Architecture for Multitask Deep Reinforcement Learning
Oct 23, 2021We propose a fully distributed actor-critic architecture, named Diff-DAC, with application to multitask reinforcement learning (MRL). During the learning process, agents communicate their value and policy parameters to their neighbours, diffusing the information across a network of agents with no need for a central station. Each agent can only access data from its local task, but aims to learn a common policy that performs well for the whole set of tasks. The architecture is scalable, since the computational and communication cost per agent depends on the number of neighbours rather than the overall number of agents. We derive Diff-DAC from duality theory and provide novel insights into the actor-critic framework, showing that it is actually an instance of the dual ascent method. We prove almost sure convergence of Diff-DAC to a common policy under general assumptions that hold even for deep-neural network approximations. For more restrictive assumptions, we also prove that this common policy is a stationary point of an approximation of the original problem. Numerical results on multitask extensions of common continuous control benchmarks demonstrate that Diff-DAC stabilises learning and has a regularising effect that induces higher performance and better generalisation properties than previous architectures.
* 27 pages, 8 figures
Compatible features for Monotonic Policy Improvement
Oct 30, 2019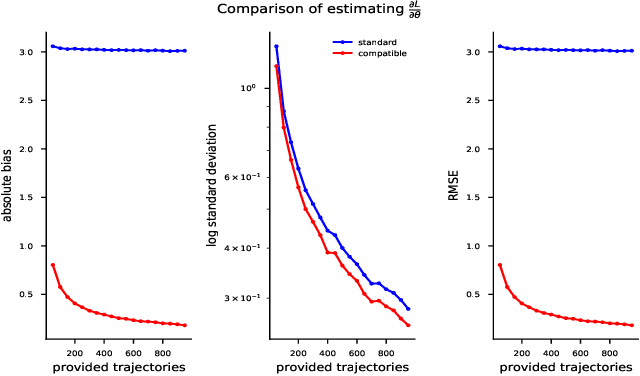
Recent policy optimization approaches have achieved substantial empirical success by constructing surrogate optimization objectives. The Approximate Policy Iteration objective (Schulman et al., 2015a; Kakade and Langford, 2002) has become a standard optimization target for reinforcement learning problems. Using this objective in practice requires an estimator of the advantage function. Policy optimization methods such as those proposed in Schulman et al. (2015b) estimate the advantages using a parametric critic. In this work we establish conditions under which the parametric approximation of the critic does not introduce bias to the updates of surrogate objective. These results hold for a general class of parametric policies, including deep neural networks. We obtain a result analogous to the compatible features derived for the original Policy Gradient Theorem (Sutton et al., 1999). As a result, we also identify a previously unknown bias that current state-of-the-art policy optimization algorithms (Schulman et al., 2015a, 2017) have introduced by not employing these compatible features.
Learning Parametric Closed-Loop Policies for Markov Potential Games
May 22, 2018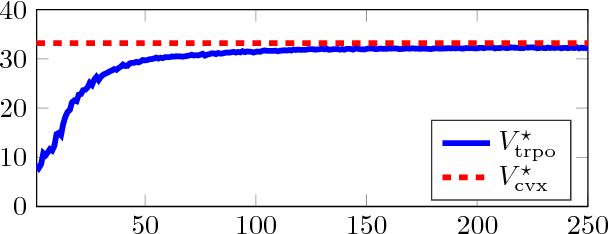
Multiagent systems where agents interact among themselves and with a stochastic environment can be formalized as stochastic games. We study a subclass named Markov potential games (MPGs) that appear often in economic and engineering applications when the agents share a common resource. We consider MPGs with continuous state-action variables, coupled constraints and nonconvex rewards. Previous analysis followed a variational approach that is only valid for very simple cases (convex rewards, invertible dynamics, and no coupled constraints); or considered deterministic dynamics and provided open-loop (OL) analysis, studying strategies that consist in predefined action sequences, which are not optimal for stochastic environments. We present a closed-loop (CL) analysis for MPGs and consider parametric policies that depend on the current state. We provide easily verifiable, sufficient and necessary conditions for a stochastic game to be an MPG, even for complex parametric functions (e.g., deep neural networks); and show that a closed-loop Nash equilibrium (NE) can be found (or at least approximated) by solving a related optimal control problem (OCP). This is useful since solving an OCP--which is a single-objective problem--is usually much simpler than solving the original set of coupled OCPs that form the game--which is a multiobjective control problem. This is a considerable improvement over the previously standard approach for the CL analysis of MPGs, which gives no approximate solution if no NE belongs to the chosen parametric family, and which is practical only for simple parametric forms. We illustrate the theoretical contributions with an example by applying our approach to a noncooperative communications engineering game. We then solve the game with a deep reinforcement learning algorithm that learns policies that closely approximates an exact variational NE of the game.
Diff-DAC: Distributed Actor-Critic for Average Multitask Deep Reinforcement Learning
Apr 22, 2018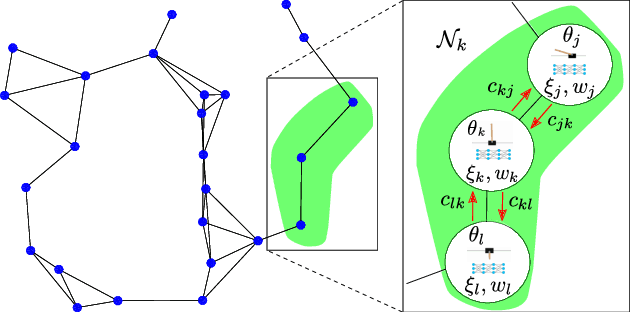
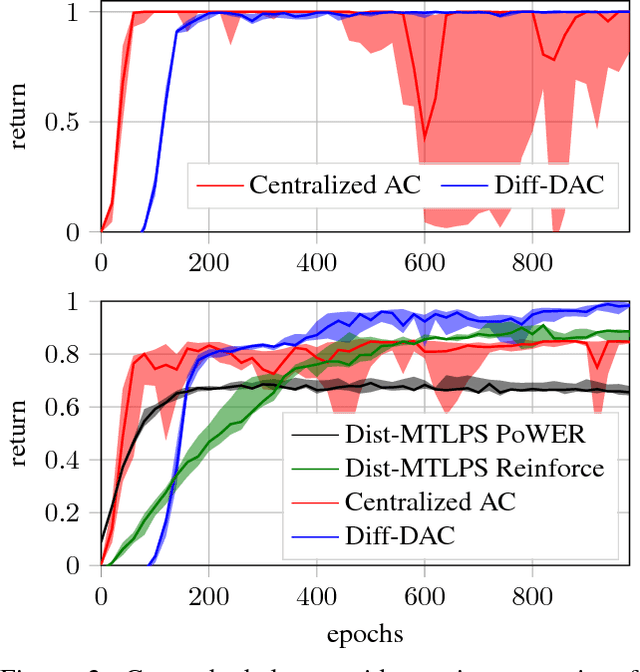
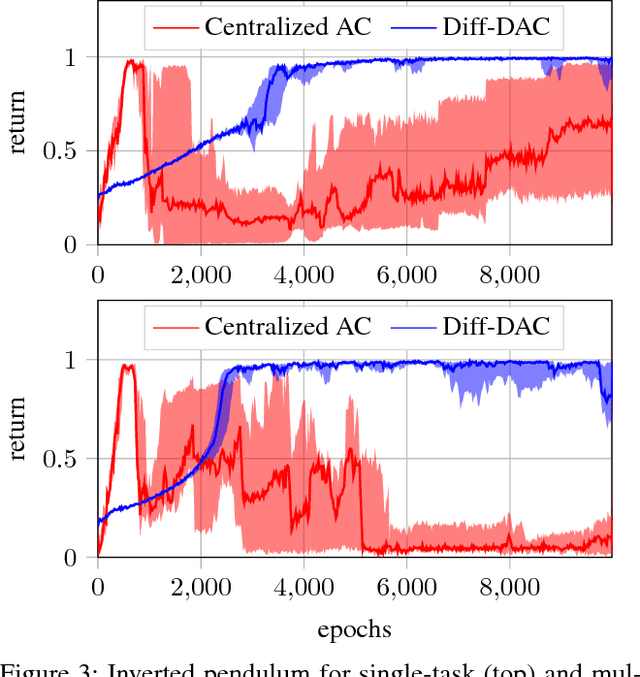
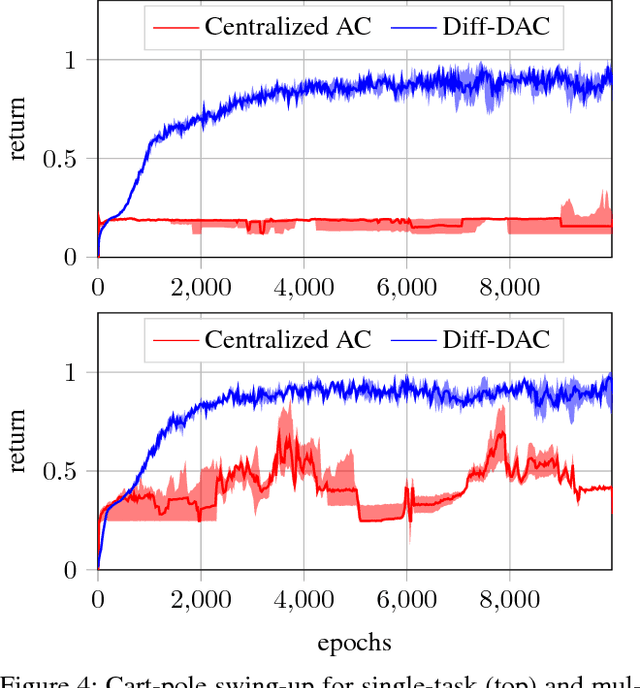
We propose a fully distributed actor-critic algorithm approximated by deep neural networks, named \textit{Diff-DAC}, with application to single-task and to average multitask reinforcement learning (MRL). Each agent has access to data from its local task only, but it aims to learn a policy that performs well on average for the whole set of tasks. During the learning process, agents communicate their value-policy parameters to their neighbors, diffusing the information across the network, so that they converge to a common policy, with no need for a central node. The method is scalable, since the computational and communication costs per agent grow with its number of neighbors. We derive Diff-DAC's from duality theory and provide novel insights into the standard actor-critic framework, showing that it is actually an instance of the dual ascent method that approximates the solution of a linear program. Experiments suggest that Diff-DAC can outperform the single previous distributed MRL approach (i.e., Dist-MTLPS) and even the centralized architecture.
Distributed Policy Evaluation Under Multiple Behavior Strategies
Nov 05, 2014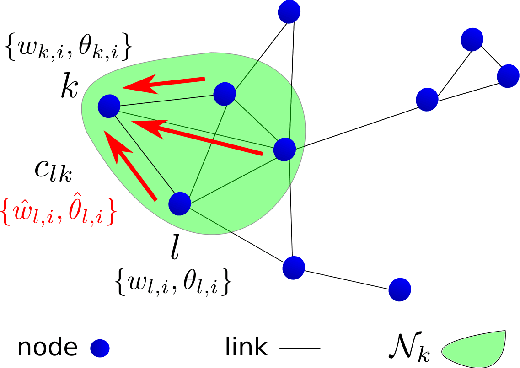
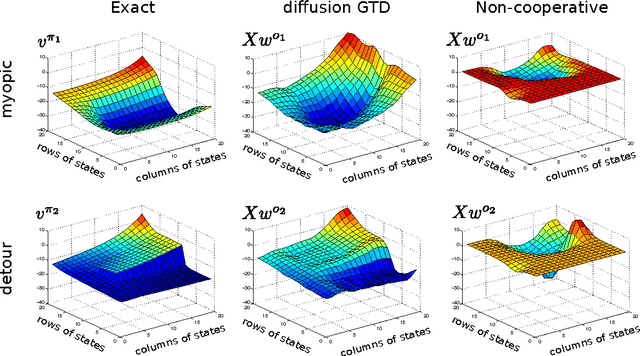
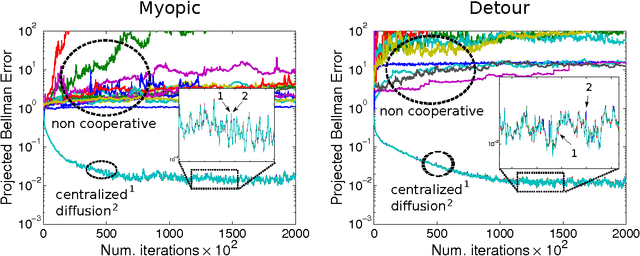
We apply diffusion strategies to develop a fully-distributed cooperative reinforcement learning algorithm in which agents in a network communicate only with their immediate neighbors to improve predictions about their environment. The algorithm can also be applied to off-policy learning, meaning that the agents can predict the response to a behavior different from the actual policies they are following. The proposed distributed strategy is efficient, with linear complexity in both computation time and memory footprint. We provide a mean-square-error performance analysis and establish convergence under constant step-size updates, which endow the network with continuous learning capabilities. The results show a clear gain from cooperation: when the individual agents can estimate the solution, cooperation increases stability and reduces bias and variance of the prediction error; but, more importantly, the network is able to approach the optimal solution even when none of the individual agents can (e.g., when the individual behavior policies restrict each agent to sample a small portion of the state space).