 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen does predictive inverse dynamics outperform behavior cloning?
Jan 29, 2026Behavior cloning (BC) is a practical offline imitation learning method, but it often fails when expert demonstrations are limited. Recent works have introduced a class of architectures named predictive inverse dynamics models (PIDM) that combine a future state predictor with an inverse dynamics model (IDM). While PIDM often outperforms BC, the reasons behind its benefits remain unclear. In this paper, we provide a theoretical explanation: PIDM introduces a bias-variance tradeoff. While predicting the future state introduces bias, conditioning the IDM on the prediction can significantly reduce variance. We establish conditions on the state predictor bias for PIDM to achieve lower prediction error and higher sample efficiency than BC, with the gap widening when additional data sources are available. We validate the theoretical insights empirically in 2D navigation tasks, where BC requires up to five times (three times on average) more demonstrations than PIDM to reach comparable performance; and in a complex 3D environment in a modern video game with high-dimensional visual inputs and stochastic transitions, where BC requires over 66\% more samples than PIDM.
Adapting a World Model for Trajectory Following in a 3D Game
Apr 16, 2025



Imitation learning is a powerful tool for training agents by leveraging expert knowledge, and being able to replicate a given trajectory is an integral part of it. In complex environments, like modern 3D video games, distribution shift and stochasticity necessitate robust approaches beyond simple action replay. In this study, we apply Inverse Dynamics Models (IDM) with different encoders and policy heads to trajectory following in a modern 3D video game -- Bleeding Edge. Additionally, we investigate several future alignment strategies that address the distribution shift caused by the aleatoric uncertainty and imperfections of the agent. We measure both the trajectory deviation distance and the first significant deviation point between the reference and the agent's trajectory and show that the optimal configuration depends on the chosen setting. Our results show that in a diverse data setting, a GPT-style policy head with an encoder trained from scratch performs the best, DINOv2 encoder with the GPT-style policy head gives the best results in the low data regime, and both GPT-style and MLP-style policy heads had comparable results when pre-trained on a diverse setting and fine-tuned for a specific behaviour setting.
Blind Image Restoration via Fast Diffusion Inversion
May 29, 2024



Recently, various methods have been proposed to solve Image Restoration (IR) tasks using a pre-trained diffusion model leading to state-of-the-art performance. However, most of these methods assume that the degradation operator in the IR task is completely known. Furthermore, a common characteristic among these approaches is that they alter the diffusion sampling process in order to satisfy the consistency with the degraded input image. This choice has recently been shown to be sub-optimal and to cause the restored image to deviate from the data manifold. To address these issues, we propose Blind Image Restoration via fast Diffusion inversion (BIRD) a blind IR method that jointly optimizes for the degradation model parameters and the restored image. To ensure that the restored images lie onto the data manifold, we propose a novel sampling technique on a pre-trained diffusion model. A key idea in our method is not to modify the reverse sampling, i.e., not to alter all the intermediate latents, once an initial noise is sampled. This is ultimately equivalent to casting the IR task as an optimization problem in the space of the input noise. Moreover, to mitigate the computational cost associated with inverting a fully unrolled diffusion model, we leverage the inherent capability of these models to skip ahead in the forward diffusion process using large time steps. We experimentally validate BIRD on several image restoration tasks and show that it achieves state of the art performance on all of them. Our code is available at https://github.com/hamadichihaoui/BIRD.
SemiGPC: Distribution-Aware Label Refinement for Imbalanced Semi-Supervised Learning Using Gaussian Processes
Nov 03, 2023
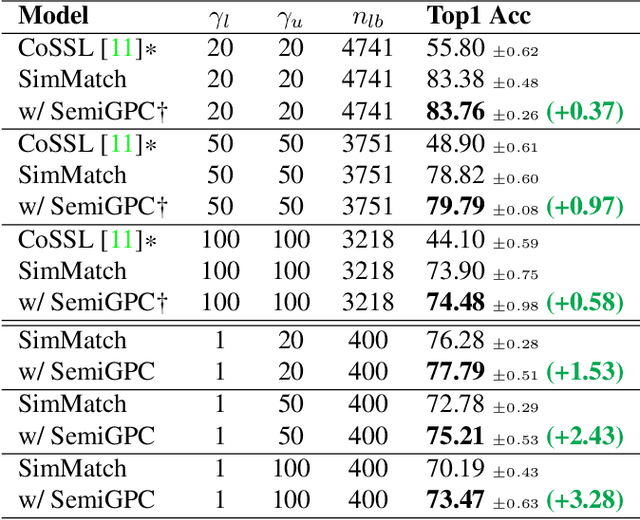

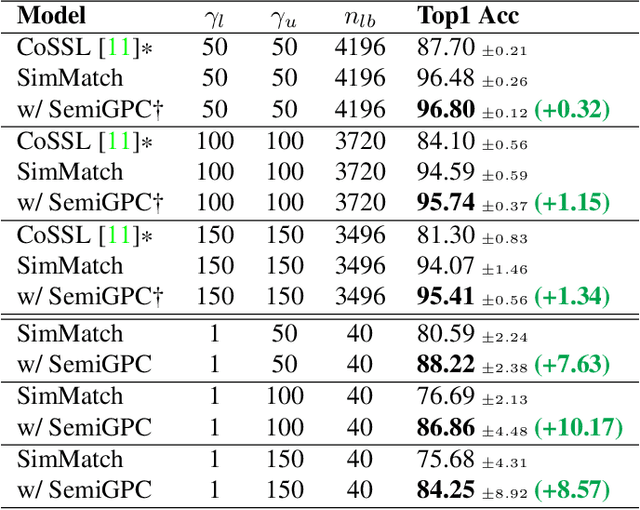
In this paper we introduce SemiGPC, a distribution-aware label refinement strategy based on Gaussian Processes where the predictions of the model are derived from the labels posterior distribution. Differently from other buffer-based semi-supervised methods such as CoMatch and SimMatch, our SemiGPC includes a normalization term that addresses imbalances in the global data distribution while maintaining local sensitivity. This explicit control allows SemiGPC to be more robust to confirmation bias especially under class imbalance. We show that SemiGPC improves performance when paired with different Semi-Supervised methods such as FixMatch, ReMixMatch, SimMatch and FreeMatch and different pre-training strategies including MSN and Dino. We also show that SemiGPC achieves state of the art results under different degrees of class imbalance on standard CIFAR10-LT/CIFAR100-LT especially in the low data-regime. Using SemiGPC also results in about 2% avg.accuracy increase compared to a new competitive baseline on the more challenging benchmarks SemiAves, SemiCUB, SemiFungi and Semi-iNat.
Towards Sleep Scoring Generalization Through Self-Supervised Meta-Learning
Jul 27, 2022

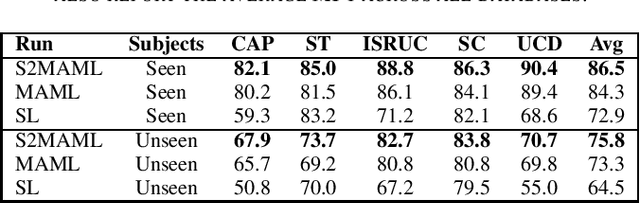

In this work we introduce a novel meta-learning method for sleep scoring based on self-supervised learning. Our approach aims at building models for sleep scoring that can generalize across different patients and recording facilities, but do not require a further adaptation step to the target data. Towards this goal, we build our method on top of the Model Agnostic Meta-Learning (MAML) framework by incorporating a self-supervised learning (SSL) stage, and call it S2MAML. We show that S2MAML can significantly outperform MAML. The gain in performance comes from the SSL stage, which we base on a general purpose pseudo-task that limits the overfitting to the subject-specific patterns present in the training dataset. We show that S2MAML outperforms standard supervised learning and MAML on the SC, ST, ISRUC, UCD and CAP datasets.
Generative Adversarial Learning via Kernel Density Discrimination
Jul 13, 2021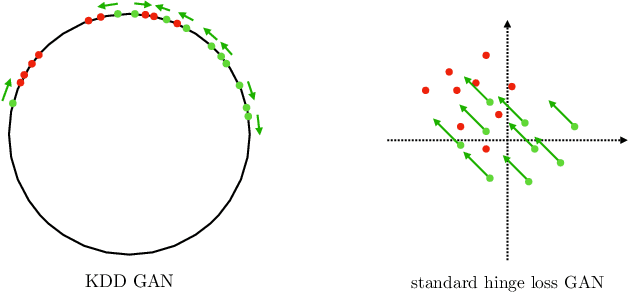
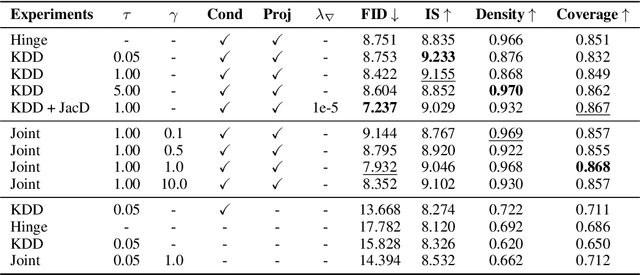

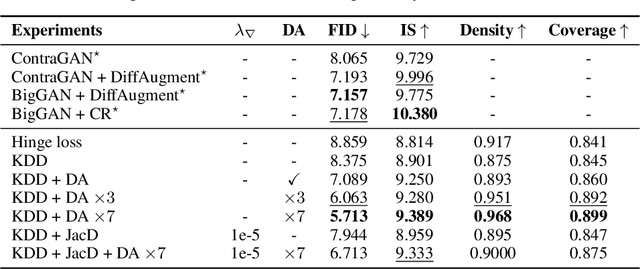
We introduce Kernel Density Discrimination GAN (KDD GAN), a novel method for generative adversarial learning. KDD GAN formulates the training as a likelihood ratio optimization problem where the data distributions are written explicitly via (local) Kernel Density Estimates (KDE). This is inspired by the recent progress in contrastive learning and its relation to KDE. We define the KDEs directly in feature space and forgo the requirement of invertibility of the kernel feature mappings. In our approach, features are no longer optimized for linear separability, as in the original GAN formulation, but for the more general discrimination of distributions in the feature space. We analyze the gradient of our loss with respect to the feature representation and show that it is better behaved than that of the original hinge loss. We perform experiments with the proposed KDE-based loss, used either as a training loss or a regularization term, on both CIFAR10 and scaled versions of ImageNet. We use BigGAN/SA-GAN as a backbone and baseline, since our focus is not to design the architecture of the networks. We show a boost in the quality of generated samples with respect to FID from 10% to 40% compared to the baseline. Code will be made available.
Boosting Generalization in Bio-Signal Classification by Learning the Phase-Amplitude Coupling
Sep 16, 2020
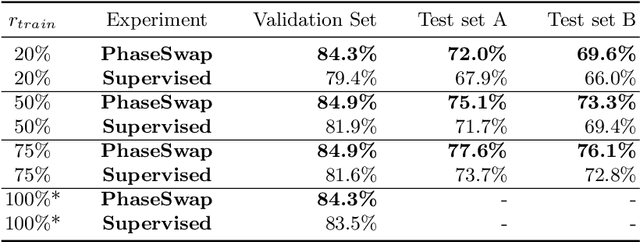


Various hand-crafted features representations of bio-signals rely primarily on the amplitude or power of the signal in specific frequency bands. The phase component is often discarded as it is more sample specific, and thus more sensitive to noise, than the amplitude. However, in general, the phase component also carries information relevant to the underlying biological processes. In fact, in this paper we show the benefits of learning the coupling of both phase and amplitude components of a bio-signal. We do so by introducing a novel self-supervised learning task, which we call Phase-Swap, that detects if bio-signals have been obtained by merging the amplitude and phase from different sources. We show in our evaluation that neural networks trained on this task generalize better across subjects and recording sessions than their fully supervised counterpart.