 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiGPC: Distribution-Aware Label Refinement for Imbalanced Semi-Supervised Learning Using Gaussian Processes
Nov 03, 2023
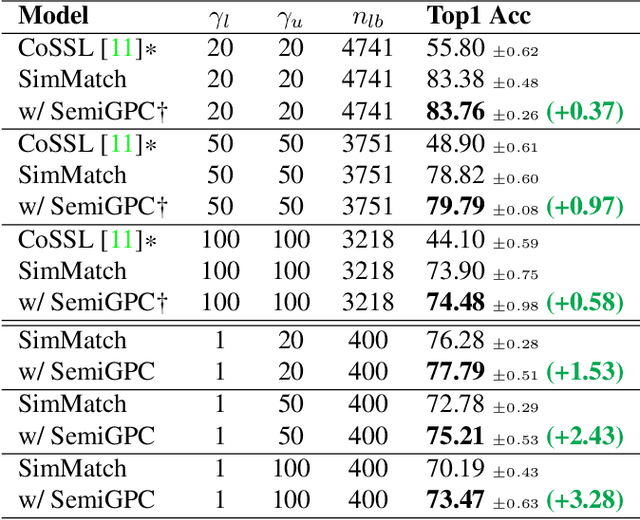

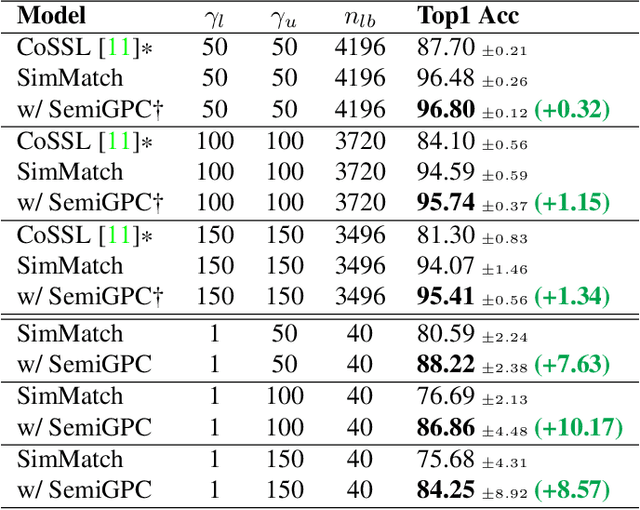
In this paper we introduce SemiGPC, a distribution-aware label refinement strategy based on Gaussian Processes where the predictions of the model are derived from the labels posterior distribution. Differently from other buffer-based semi-supervised methods such as CoMatch and SimMatch, our SemiGPC includes a normalization term that addresses imbalances in the global data distribution while maintaining local sensitivity. This explicit control allows SemiGPC to be more robust to confirmation bias especially under class imbalance. We show that SemiGPC improves performance when paired with different Semi-Supervised methods such as FixMatch, ReMixMatch, SimMatch and FreeMatch and different pre-training strategies including MSN and Dino. We also show that SemiGPC achieves state of the art results under different degrees of class imbalance on standard CIFAR10-LT/CIFAR100-LT especially in the low data-regime. Using SemiGPC also results in about 2% avg.accuracy increase compared to a new competitive baseline on the more challenging benchmarks SemiAves, SemiCUB, SemiFungi and Semi-iNat.
A Meta-Learning Approach to Predicting Performance and Data Requirements
Mar 02, 2023We propose an approach to estimate the number of samples required for a model to reach a target performance. We find that the power law, the de facto principle to estimate model performance, leads to large error when using a small dataset (e.g., 5 samples per class) for extrapolation. This is because the log-performance error against the log-dataset size follows a nonlinear progression in the few-shot regime followed by a linear progression in the high-shot regime. We introduce a novel piecewise power law (PPL) that handles the two data regimes differently. To estimate the parameters of the PPL, we introduce a random forest regressor trained via meta learning that generalizes across classification/detection tasks, ResNet/ViT based architectures, and random/pre-trained initializations. The PPL improves the performance estimation on average by 37% across 16 classification and 33% across 10 detection datasets, compared to the power law. We further extend the PPL to provide a confidence bound and use it to limit the prediction horizon that reduces over-estimation of data by 76% on classification and 91% on detection datasets.
ComplETR: Reducing the cost of annotations for object detection in dense scenes with vision transformers
Sep 13, 2022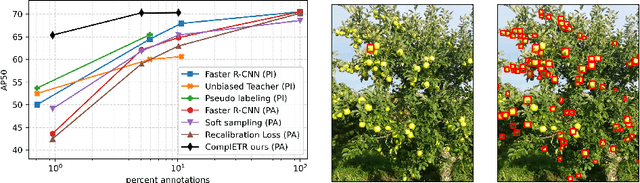
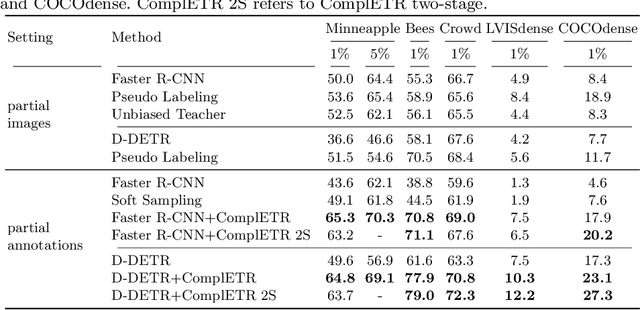
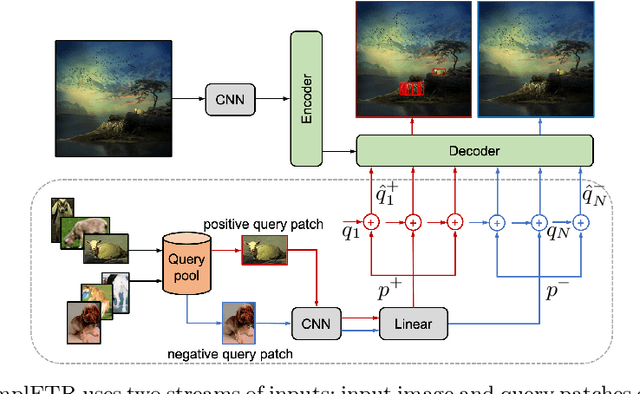
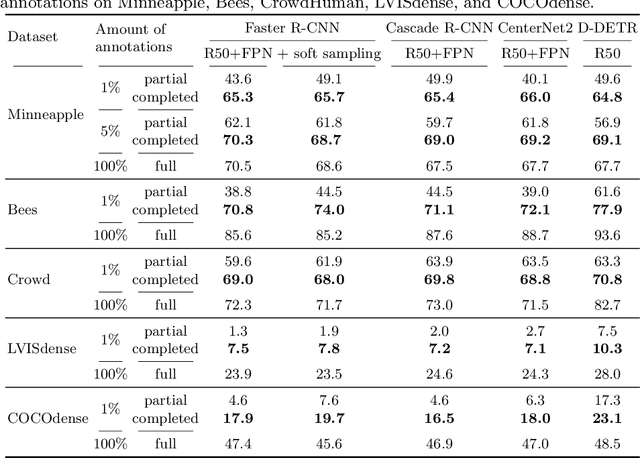
Annotating bounding boxes for object detection is expensive, time-consuming, and error-prone. In this work, we propose a DETR based framework called ComplETR that is designed to explicitly complete missing annotations in partially annotated dense scene datasets. This reduces the need to annotate every object instance in the scene thereby reducing annotation cost. ComplETR augments object queries in DETR decoder with patch information of objects in the image. Combined with a matching loss, it can effectively find objects that are similar to the input patch and complete the missing annotations. We show that our framework outperforms the state-of-the-art methods such as Soft Sampling and Unbiased Teacher by itself, while at the same time can be used in conjunction with these methods to further improve their performance. Our framework is also agnostic to the choice of the downstream object detectors; we show performance improvement for several popular detectors such as Faster R-CNN, Cascade R-CNN, CenterNet2, and Deformable DETR on multiple dense scene datasets.
Rethinking Few-Shot Object Detection on a Multi-Domain Benchmark
Jul 22, 2022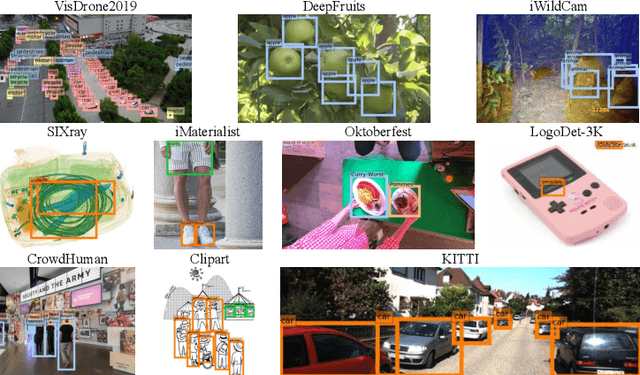
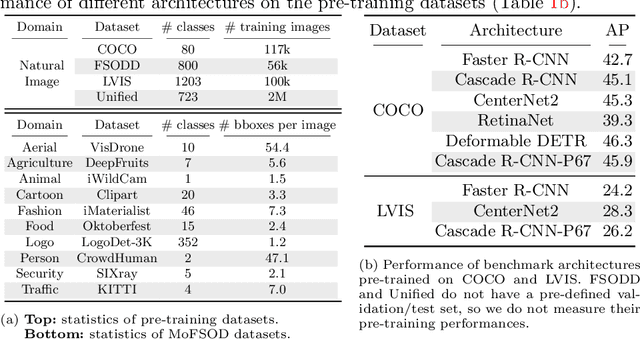
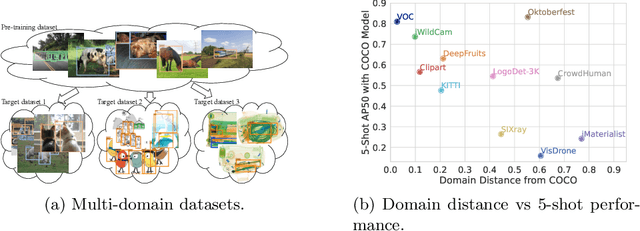
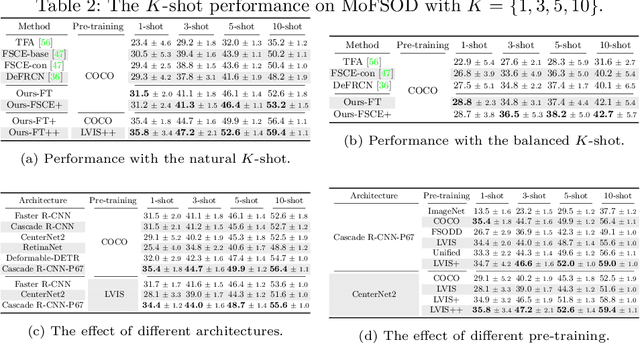
Most existing works on few-shot object detection (FSOD) focus on a setting where both pre-training and few-shot learning datasets are from a similar domain. However, few-shot algorithms are important in multiple domains; hence evaluation needs to reflect the broad applications. We propose a Multi-dOmain Few-Shot Object Detection (MoFSOD) benchmark consisting of 10 datasets from a wide range of domains to evaluate FSOD algorithms. We comprehensively analyze the impacts of freezing layers, different architectures, and different pre-training datasets on FSOD performance. Our empirical results show several key factors that have not been explored in previous works: 1) contrary to previous belief, on a multi-domain benchmark, fine-tuning (FT) is a strong baseline for FSOD, performing on par or better than the state-of-the-art (SOTA) algorithms; 2) utilizing FT as the baseline allows us to explore multiple architectures, and we found them to have a significant impact on down-stream few-shot tasks, even with similar pre-training performances; 3) by decoupling pre-training and few-shot learning, MoFSOD allows us to explore the impact of different pre-training datasets, and the right choice can boost the performance of the down-stream tasks significantly. Based on these findings, we list possible avenues of investigation for improving FSOD performance and propose two simple modifications to existing algorithms that lead to SOTA performance on the MoFSOD benchmark. The code is available at https://github.com/amazon-research/few-shot-object-detection-benchmark.
Class-Incremental Learning with Strong Pre-trained Models
Apr 07, 2022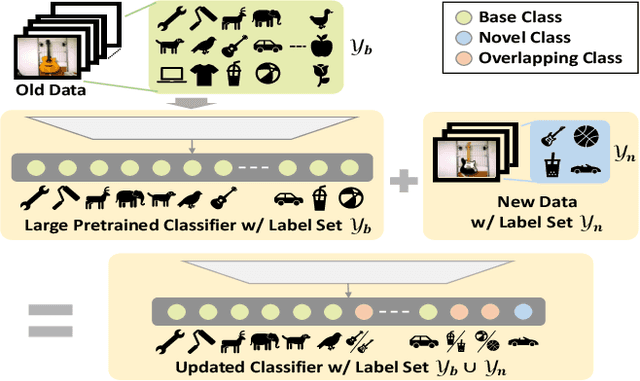
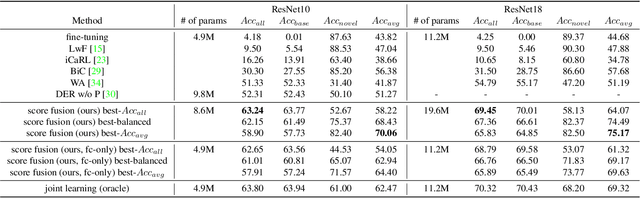
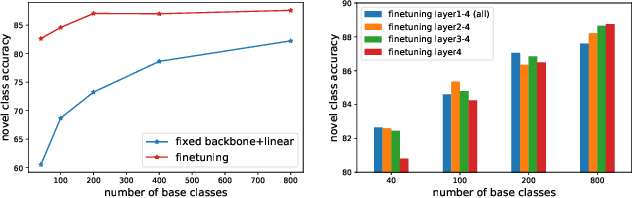
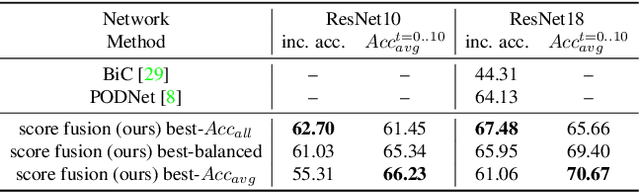
Class-incremental learning (CIL) has been widely studied under the setting of starting from a small number of classes (base classes). Instead, we explore an understudied real-world setting of CIL that starts with a strong model pre-trained on a large number of base classes. We hypothesize that a strong base model can provide a good representation for novel classes and incremental learning can be done with small adaptations. We propose a 2-stage training scheme, i) feature augmentation -- cloning part of the backbone and fine-tuning it on the novel data, and ii) fusion -- combining the base and novel classifiers into a unified classifier. Experiments show that the proposed method significantly outperforms state-of-the-art CIL methods on the large-scale ImageNet dataset (e.g. +10% overall accuracy than the best). We also propose and analyze understudied practical CIL scenarios, such as base-novel overlap with distribution shift. Our proposed method is robust and generalizes to all analyzed CIL settings.
Omni-DETR: Omni-Supervised Object Detection with Transformers
Mar 30, 2022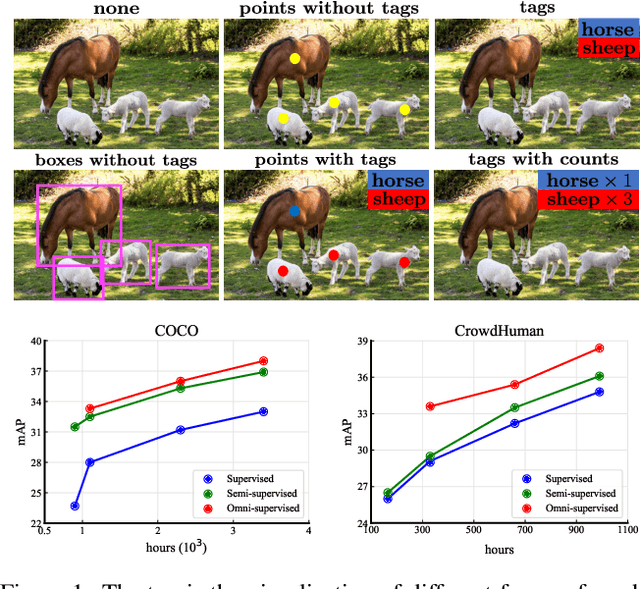


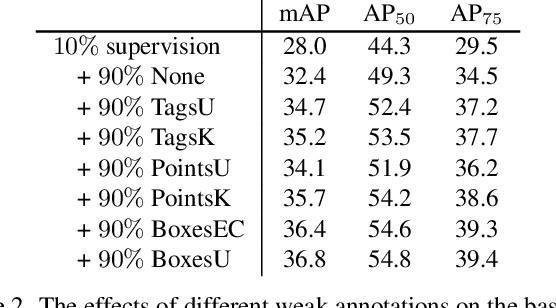
We consider the problem of omni-supervised object detection, which can use unlabeled, fully labeled and weakly labeled annotations, such as image tags, counts, points, etc., for object detection. This is enabled by a unified architecture, Omni-DETR, based on the recent progress on student-teacher framework and end-to-end transformer based object detection. Under this unified architecture, different types of weak labels can be leveraged to generate accurate pseudo labels, by a bipartite matching based filtering mechanism, for the model to learn. In the experiments, Omni-DETR has achieved state-of-the-art results on multiple datasets and settings. And we have found that weak annotations can help to improve detection performance and a mixture of them can achieve a better trade-off between annotation cost and accuracy than the standard complete annotation. These findings could encourage larger object detection datasets with mixture annotations. The code is available at https://github.com/amazon-research/omni-detr.
Out-of-the-box channel pruned networks
Apr 30, 2020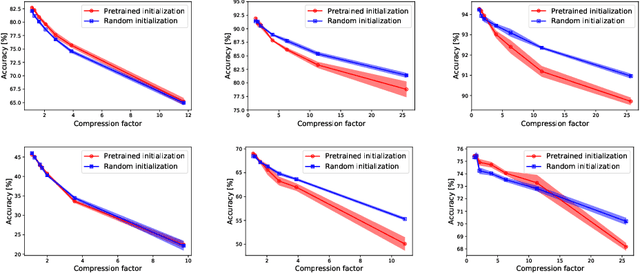
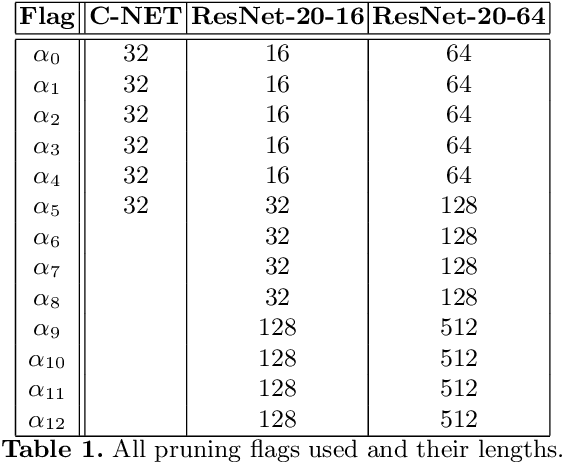
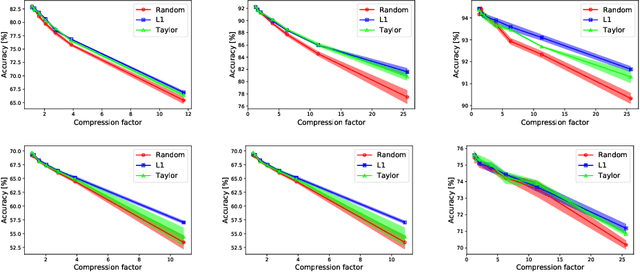
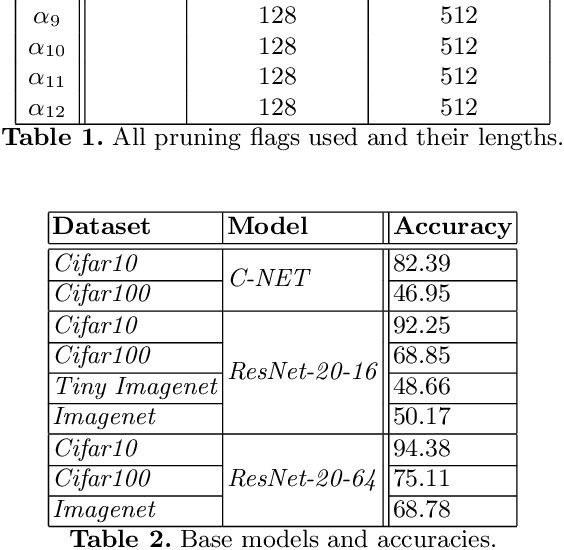
In the last decade convolutional neural networks have become gargantuan. Pre-trained models, when used as initializers are able to fine-tune ever larger networks on small datasets. Consequently, not all the convolutional features that these fine-tuned models detect are requisite for the end-task. Several works of channel pruning have been proposed to prune away compute and memory from models that were trained already. Typically, these involve policies that decide which and how many channels to remove from each layer leading to channel-wise and/or layer-wise pruning profiles, respectively. In this paper, we conduct several baseline experiments and establish that profiles from random channel-wise pruning policies are as good as metric-based ones. We also establish that there may exist profiles from some layer-wise pruning policies that are measurably better than common baselines. We then demonstrate that the top layer-wise pruning profiles found using an exhaustive random search from one datatset are also among the top profiles for other datasets. This implies that we could identify out-of-the-box layer-wise pruning profiles using benchmark datasets and use these directly for new datasets. Furthermore, we develop a Reinforcement Learning (RL) policy-based search algorithm with a direct objective of finding transferable layer-wise pruning profiles using many models for the same architecture. We use a novel reward formulation that drives this RL search towards an expected compression while maximizing accuracy. Our results show that our transferred RL-based profiles are as good or better than best profiles found on the original dataset via exhaustive search. We then demonstrate that if we found the profiles using a mid-sized dataset such as Cifar10/100, we are able to transfer them to even a large dataset such as Imagenet.
$d$-SNE: Domain Adaptation using Stochastic Neighborhood Embedding
May 29, 2019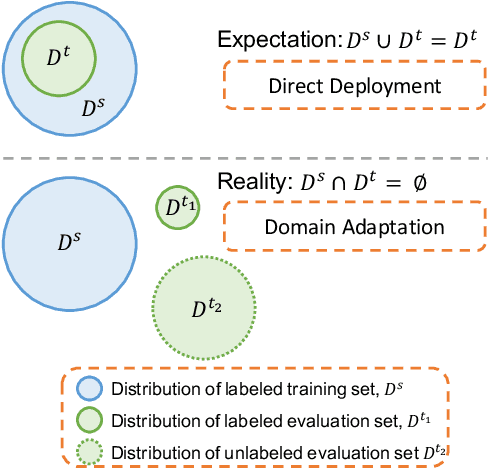
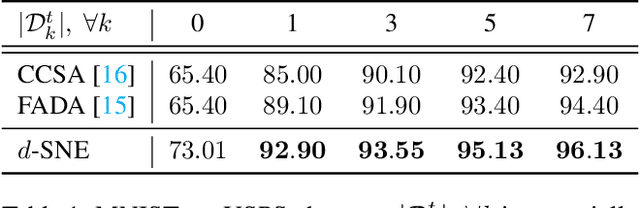
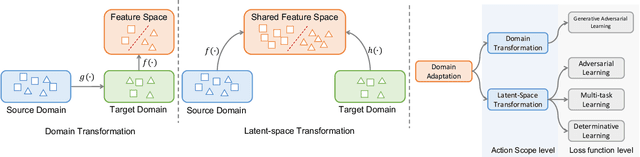
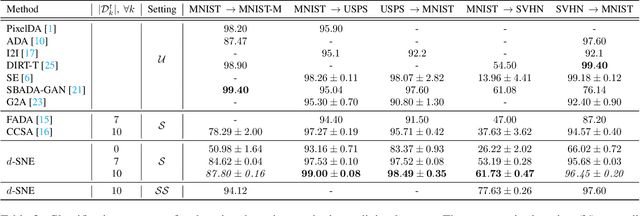
Deep neural networks often require copious amount of labeled-data to train their scads of parameters. Training larger and deeper networks is hard without appropriate regularization, particularly while using a small dataset. Laterally, collecting well-annotated data is expensive, time-consuming and often infeasible. A popular way to regularize these networks is to simply train the network with more data from an alternate representative dataset. This can lead to adverse effects if the statistics of the representative dataset are dissimilar to our target. This predicament is due to the problem of domain shift. Data from a shifted domain might not produce bespoke features when a feature extractor from the representative domain is used. In this paper, we propose a new technique ($d$-SNE) of domain adaptation that cleverly uses stochastic neighborhood embedding techniques and a novel modified-Hausdorff distance. The proposed technique is learnable end-to-end and is therefore, ideally suited to train neural networks. Extensive experiments demonstrate that $d$-SNE outperforms the current states-of-the-art and is robust to the variances in different datasets, even in the one-shot and semi-supervised learning settings. $d$-SNE also demonstrates the ability to generalize to multiple domains concurrently.