 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-the-box channel pruned networks
Paper and Code
Apr 30, 2020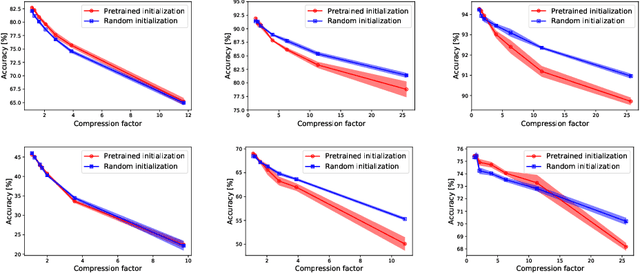
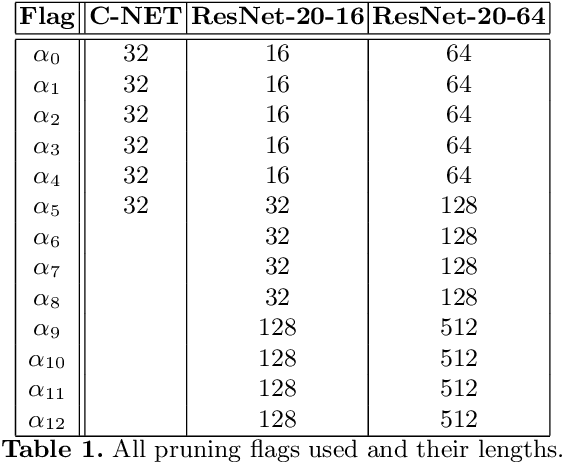
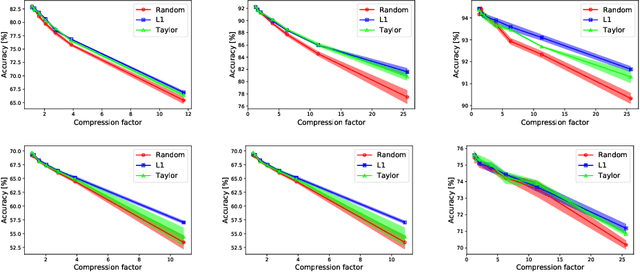
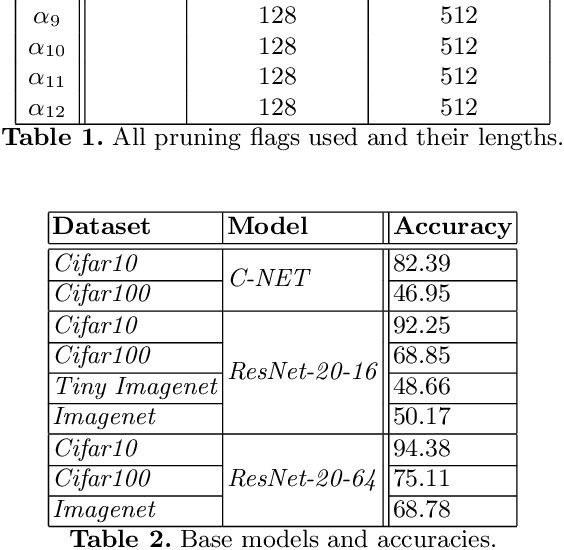
In the last decade convolutional neural networks have become gargantuan. Pre-trained models, when used as initializers are able to fine-tune ever larger networks on small datasets. Consequently, not all the convolutional features that these fine-tuned models detect are requisite for the end-task. Several works of channel pruning have been proposed to prune away compute and memory from models that were trained already. Typically, these involve policies that decide which and how many channels to remove from each layer leading to channel-wise and/or layer-wise pruning profiles, respectively. In this paper, we conduct several baseline experiments and establish that profiles from random channel-wise pruning policies are as good as metric-based ones. We also establish that there may exist profiles from some layer-wise pruning policies that are measurably better than common baselines. We then demonstrate that the top layer-wise pruning profiles found using an exhaustive random search from one datatset are also among the top profiles for other datasets. This implies that we could identify out-of-the-box layer-wise pruning profiles using benchmark datasets and use these directly for new datasets. Furthermore, we develop a Reinforcement Learning (RL) policy-based search algorithm with a direct objective of finding transferable layer-wise pruning profiles using many models for the same architecture. We use a novel reward formulation that drives this RL search towards an expected compression while maximizing accuracy. Our results show that our transferred RL-based profiles are as good or better than best profiles found on the original dataset via exhaustive search. We then demonstrate that if we found the profiles using a mid-sized dataset such as Cifar10/100, we are able to transfer them to even a large dataset such as Imagenet.