 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Effectiveness of Efficient Neural Architecture Search for Sentence-Pair Tasks
Oct 08, 2020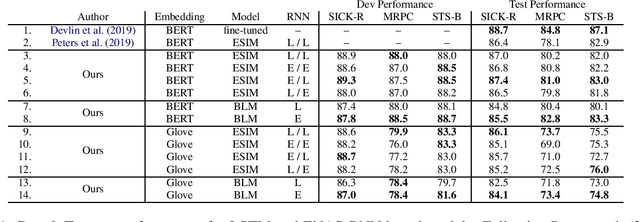
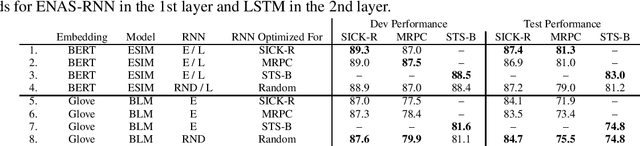

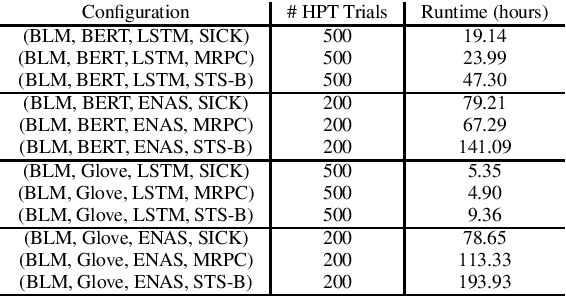
Neural Architecture Search (NAS) methods, which automatically learn entire neural model or individual neural cell architectures, have recently achieved competitive or state-of-the-art (SOTA) performance on variety of natural language processing and computer vision tasks, including language modeling, natural language inference, and image classification. In this work, we explore the applicability of a SOTA NAS algorithm, Efficient Neural Architecture Search (ENAS) (Pham et al., 2018) to two sentence pair tasks, paraphrase detection and semantic textual similarity. We use ENAS to perform a micro-level search and learn a task-optimized RNN cell architecture as a drop-in replacement for an LSTM. We explore the effectiveness of ENAS through experiments on three datasets (MRPC, SICK, STS-B), with two different models (ESIM, BiLSTM-Max), and two sets of embeddings (Glove, BERT). In contrast to prior work applying ENAS to NLP tasks, our results are mixed -- we find that ENAS architectures sometimes, but not always, outperform LSTMs and perform similarly to random architecture search.
Out-of-the-box channel pruned networks
Apr 30, 2020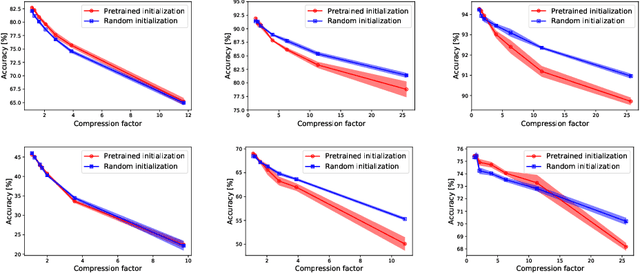
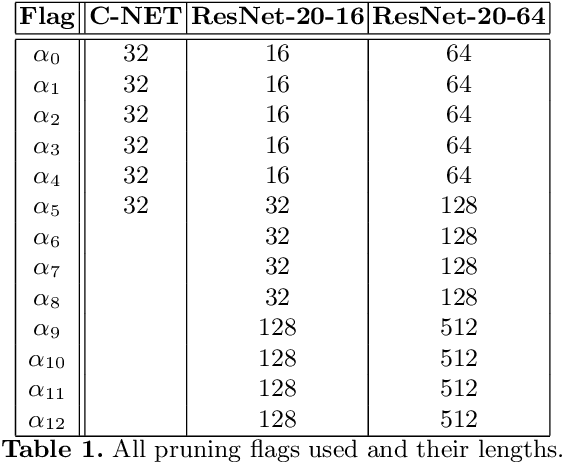
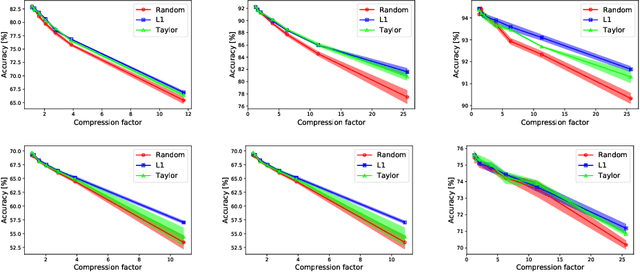
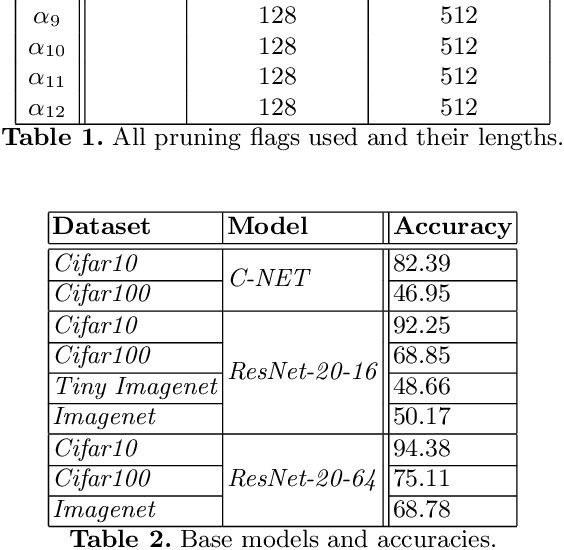
In the last decade convolutional neural networks have become gargantuan. Pre-trained models, when used as initializers are able to fine-tune ever larger networks on small datasets. Consequently, not all the convolutional features that these fine-tuned models detect are requisite for the end-task. Several works of channel pruning have been proposed to prune away compute and memory from models that were trained already. Typically, these involve policies that decide which and how many channels to remove from each layer leading to channel-wise and/or layer-wise pruning profiles, respectively. In this paper, we conduct several baseline experiments and establish that profiles from random channel-wise pruning policies are as good as metric-based ones. We also establish that there may exist profiles from some layer-wise pruning policies that are measurably better than common baselines. We then demonstrate that the top layer-wise pruning profiles found using an exhaustive random search from one datatset are also among the top profiles for other datasets. This implies that we could identify out-of-the-box layer-wise pruning profiles using benchmark datasets and use these directly for new datasets. Furthermore, we develop a Reinforcement Learning (RL) policy-based search algorithm with a direct objective of finding transferable layer-wise pruning profiles using many models for the same architecture. We use a novel reward formulation that drives this RL search towards an expected compression while maximizing accuracy. Our results show that our transferred RL-based profiles are as good or better than best profiles found on the original dataset via exhaustive search. We then demonstrate that if we found the profiles using a mid-sized dataset such as Cifar10/100, we are able to transfer them to even a large dataset such as Imagenet.
$d$-SNE: Domain Adaptation using Stochastic Neighborhood Embedding
May 29, 2019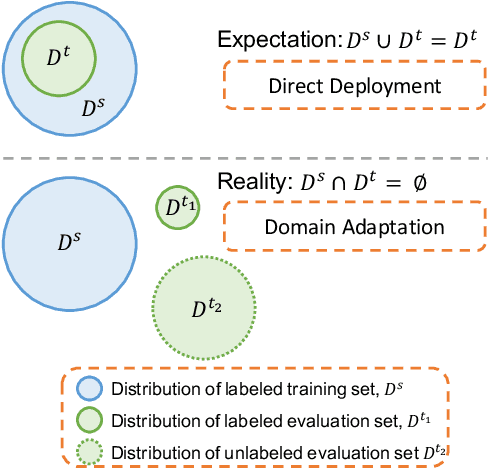
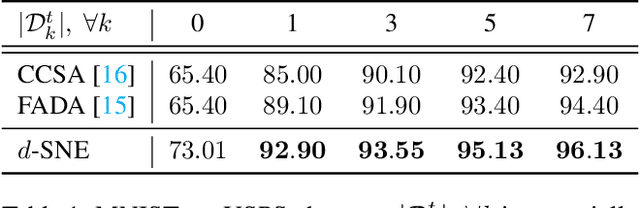
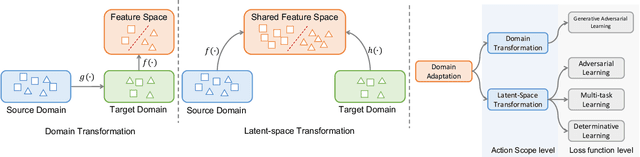
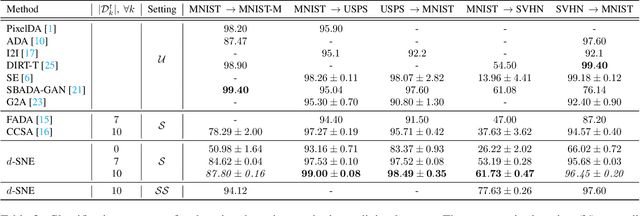
Deep neural networks often require copious amount of labeled-data to train their scads of parameters. Training larger and deeper networks is hard without appropriate regularization, particularly while using a small dataset. Laterally, collecting well-annotated data is expensive, time-consuming and often infeasible. A popular way to regularize these networks is to simply train the network with more data from an alternate representative dataset. This can lead to adverse effects if the statistics of the representative dataset are dissimilar to our target. This predicament is due to the problem of domain shift. Data from a shifted domain might not produce bespoke features when a feature extractor from the representative domain is used. In this paper, we propose a new technique ($d$-SNE) of domain adaptation that cleverly uses stochastic neighborhood embedding techniques and a novel modified-Hausdorff distance. The proposed technique is learnable end-to-end and is therefore, ideally suited to train neural networks. Extensive experiments demonstrate that $d$-SNE outperforms the current states-of-the-art and is robust to the variances in different datasets, even in the one-shot and semi-supervised learning settings. $d$-SNE also demonstrates the ability to generalize to multiple domains concurrently.
A Strategy for an Uncompromising Incremental Learner
Jul 17, 2017
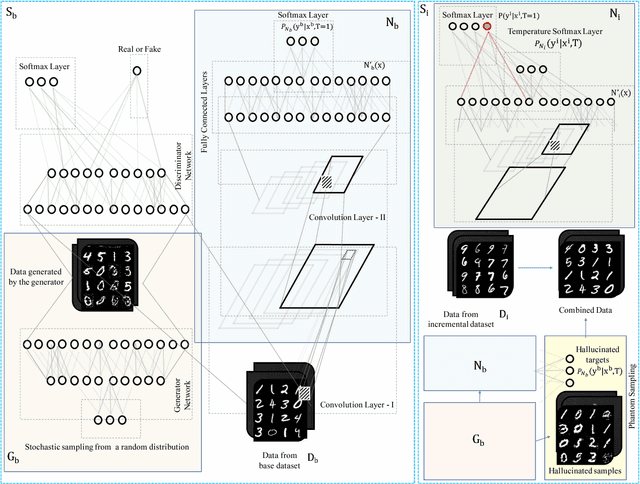
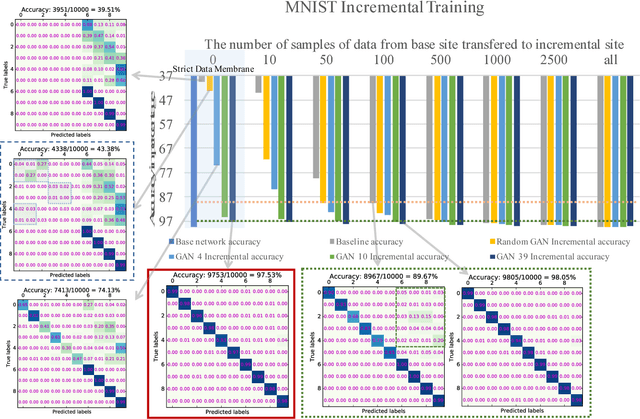
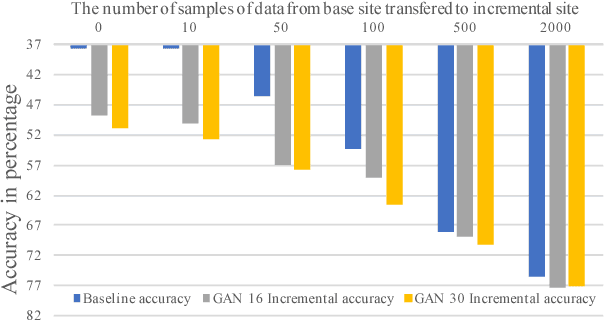
Multi-class supervised learning systems require the knowledge of the entire range of labels they predict. Often when learnt incrementally, they suffer from catastrophic forgetting. To avoid this, generous leeways have to be made to the philosophy of incremental learning that either forces a part of the machine to not learn, or to retrain the machine again with a selection of the historic data. While these hacks work to various degrees, they do not adhere to the spirit of incremental learning. In this article, we redefine incremental learning with stringent conditions that do not allow for any undesirable relaxations and assumptions. We design a strategy involving generative models and the distillation of dark knowledge as a means of hallucinating data along with appropriate targets from past distributions. We call this technique, phantom sampling.We show that phantom sampling helps avoid catastrophic forgetting during incremental learning. Using an implementation based on deep neural networks, we demonstrate that phantom sampling dramatically avoids catastrophic forgetting. We apply these strategies to competitive multi-class incremental learning of deep neural networks. Using various benchmark datasets and through our strategy, we demonstrate that strict incremental learning could be achieved. We further put our strategy to test on challenging cases, including cross-domain increments and incrementing on a novel label space. We also propose a trivial extension to unbounded-continual learning and identify potential for future development.
Classification of Diabetic Retinopathy Images Using Multi-Class Multiple-Instance Learning Based on Color Correlogram Features
Apr 05, 2017
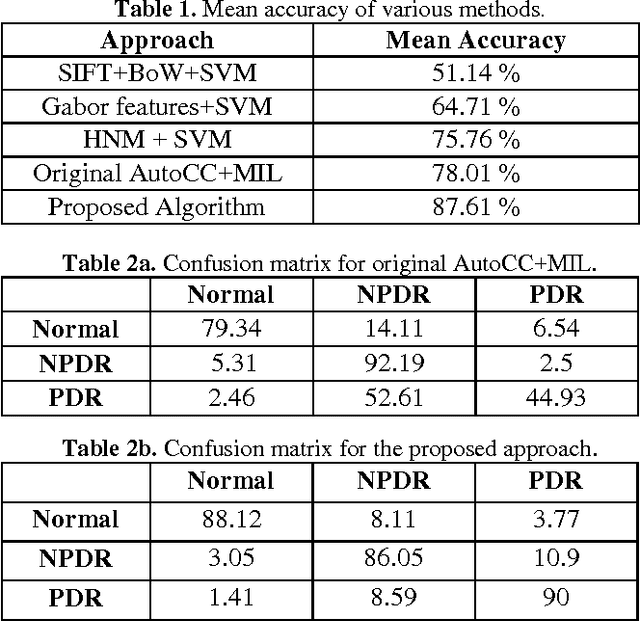

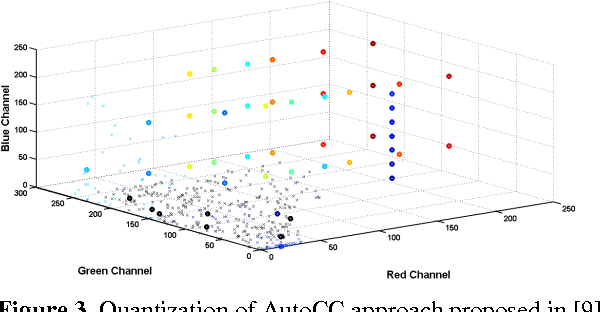
All people with diabetes have the risk of developing diabetic retinopathy (DR), a vision-threatening complication. Early detection and timely treatment can reduce the occurrence of blindness due to DR. Computer-aided diagnosis has the potential benefit of improving the accuracy and speed in DR detection. This study is concerned with automatic classification of images with microaneurysm (MA) and neovascularization (NV), two important DR clinical findings. Together with normal images, this presents a 3-class classification problem. We propose a modified color auto-correlogram feature (AutoCC) with low dimensionality that is spectrally tuned towards DR images. Recognizing the fact that the images with or without MA or NV are generally different only in small, localized regions, we propose to employ a multi-class, multiple-instance learning framework for performing the classification task using the proposed feature. Extensive experiments including comparison with a few state-of-art image classification approaches have been performed and the results suggest that the proposed approach is promising as it outperforms other methods by a large margin.
Neural Dataset Generality
May 14, 2016
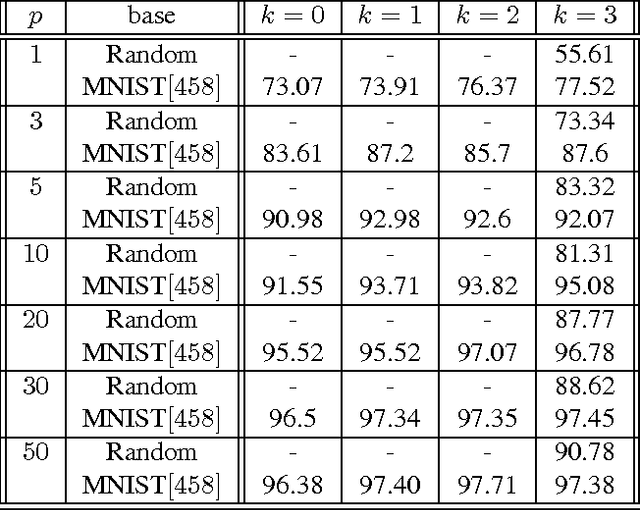

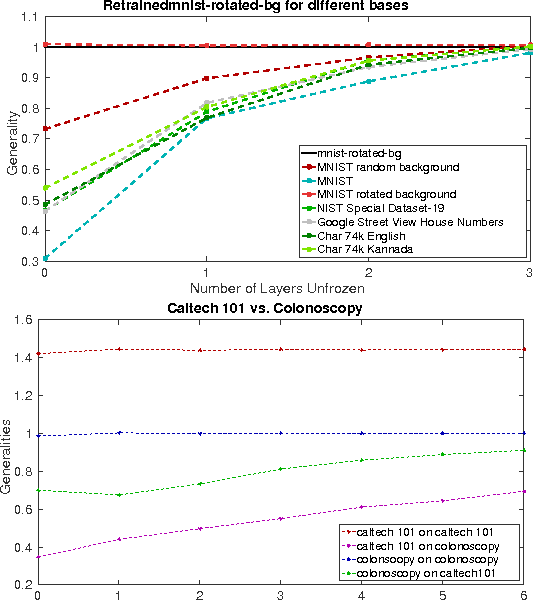
Often the filters learned by Convolutional Neural Networks (CNNs) from different datasets appear similar. This is prominent in the first few layers. This similarity of filters is being exploited for the purposes of transfer learning and some studies have been made to analyse such transferability of features. This is also being used as an initialization technique for different tasks in the same dataset or for the same task in similar datasets. Off-the-shelf CNN features have capitalized on this idea to promote their networks as best transferable and most general and are used in a cavalier manner in day-to-day computer vision tasks. It is curious that while the filters learned by these CNNs are related to the atomic structures of the images from which they are learnt, all datasets learn similar looking low-level filters. With the understanding that a dataset that contains many such atomic structures learn general filters and are therefore useful to initialize other networks with, we propose a way to analyse and quantify generality among datasets from their accuracies on transferred filters. We applied this metric on several popular character recognition, natural image and a medical image dataset, and arrived at some interesting conclusions. On further experimentation we also discovered that particular classes in a dataset themselves are more general than others.
Diving deeper into mentee networks
Apr 27, 2016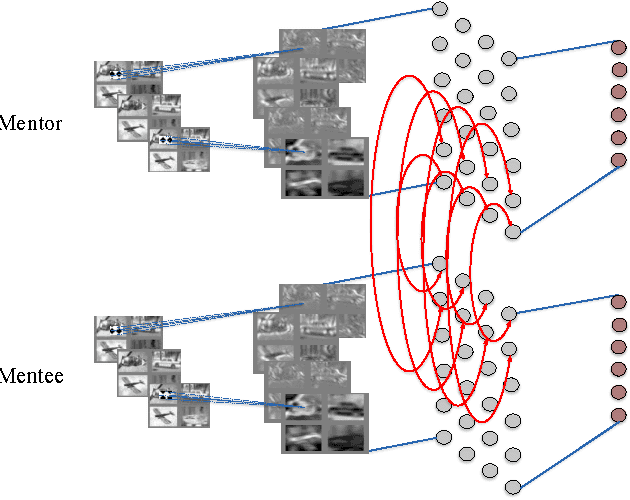


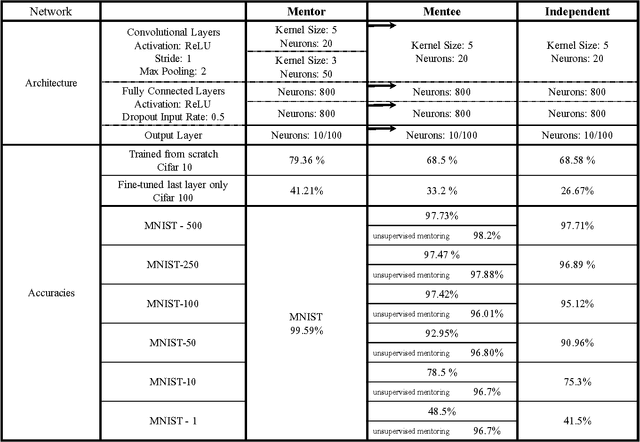
Modern computer vision is all about the possession of powerful image representations. Deeper and deeper convolutional neural networks have been built using larger and larger datasets and are made publicly available. A large swath of computer vision scientists use these pre-trained networks with varying degrees of successes in various tasks. Even though there is tremendous success in copying these networks, the representational space is not learnt from the target dataset in a traditional manner. One of the reasons for opting to use a pre-trained network over a network learnt from scratch is that small datasets provide less supervision and require meticulous regularization, smaller and careful tweaking of learning rates to even achieve stable learning without weight explosion. It is often the case that large deep networks are not portable, which necessitates the ability to learn mid-sized networks from scratch. In this article, we dive deeper into training these mid-sized networks on small datasets from scratch by drawing additional supervision from a large pre-trained network. Such learning also provides better generalization accuracies than networks trained with common regularization techniques such as l2, l1 and dropouts. We show that features learnt thus, are more general than those learnt independently. We studied various characteristics of such networks and found some interesting behaviors.