 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Strategy for an Uncompromising Incremental Learner
Paper and Code
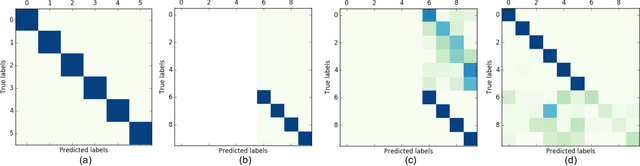
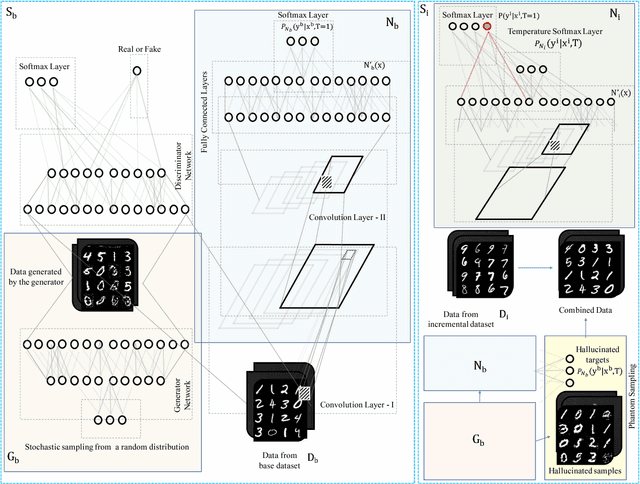
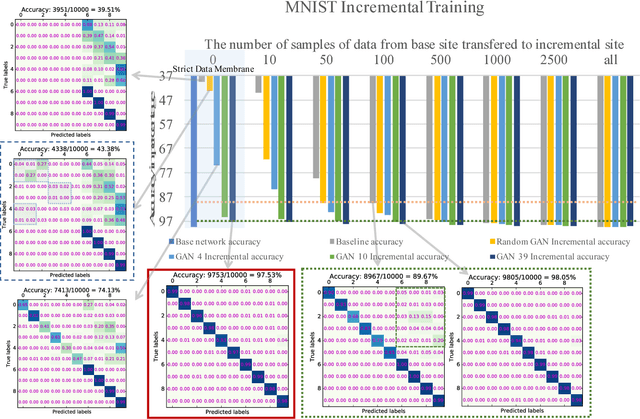
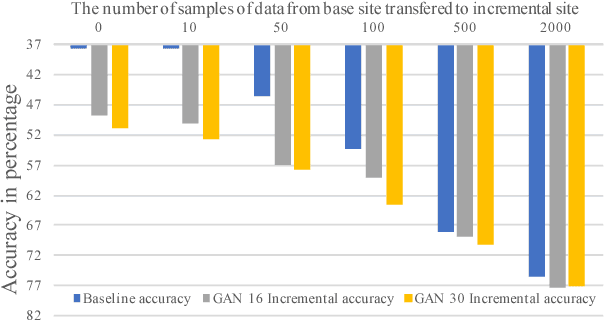
Multi-class supervised learning systems require the knowledge of the entire range of labels they predict. Often when learnt incrementally, they suffer from catastrophic forgetting. To avoid this, generous leeways have to be made to the philosophy of incremental learning that either forces a part of the machine to not learn, or to retrain the machine again with a selection of the historic data. While these hacks work to various degrees, they do not adhere to the spirit of incremental learning. In this article, we redefine incremental learning with stringent conditions that do not allow for any undesirable relaxations and assumptions. We design a strategy involving generative models and the distillation of dark knowledge as a means of hallucinating data along with appropriate targets from past distributions. We call this technique, phantom sampling.We show that phantom sampling helps avoid catastrophic forgetting during incremental learning. Using an implementation based on deep neural networks, we demonstrate that phantom sampling dramatically avoids catastrophic forgetting. We apply these strategies to competitive multi-class incremental learning of deep neural networks. Using various benchmark datasets and through our strategy, we demonstrate that strict incremental learning could be achieved. We further put our strategy to test on challenging cases, including cross-domain increments and incrementing on a novel label space. We also propose a trivial extension to unbounded-continual learning and identify potential for future development.