 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting Navigation of Outdoor Shopping Complexes for Visually-impaired Users through Multi-modal Data Fusion
Apr 05, 2017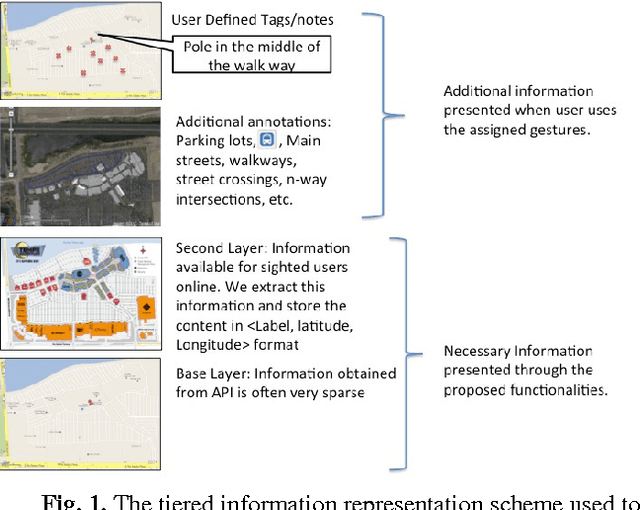
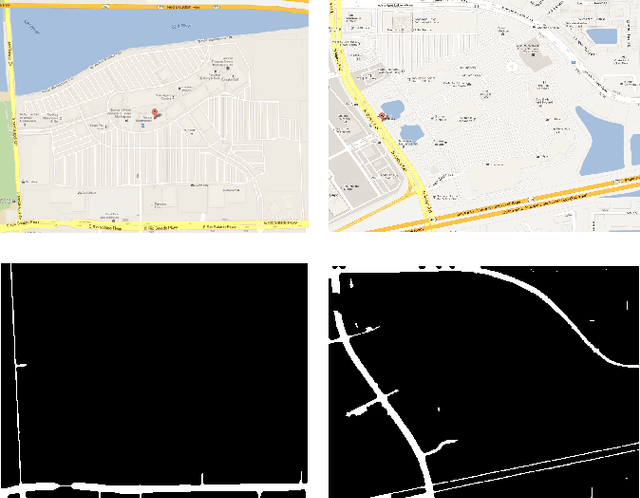
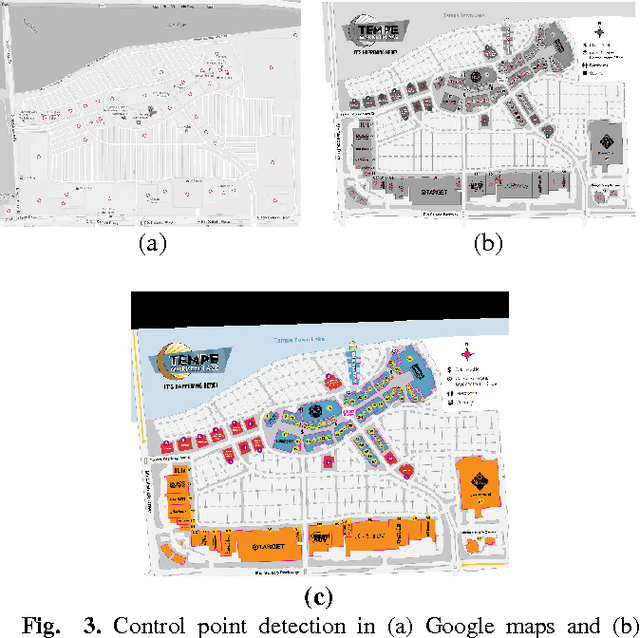
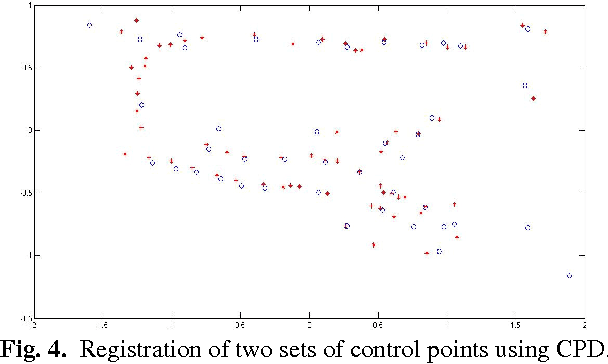
Outdoor shopping complexes (OSC) are extremely difficult for people with visual impairment to navigate. Existing GPS devices are mostly designed for roadside navigation and seldom transition well into an OSC-like setting. We report our study on the challenges faced by a blind person in navigating OSC through developing a new mobile application named iExplore. We first report an exploratory study aiming at deriving specific design principles for building this system by learning the unique challenges of the problem. Then we present a methodology that can be used to derive the necessary information for the development of iExplore, followed by experimental validation of the technology by a group of visually impaired users in a local outdoor shopping center. User feedback and other experiments suggest that iExplore, while at its very initial phase, has the potential of filling a practical gap in existing assistive technologies for the visually impaired.
Classification of Diabetic Retinopathy Images Using Multi-Class Multiple-Instance Learning Based on Color Correlogram Features
Apr 05, 2017
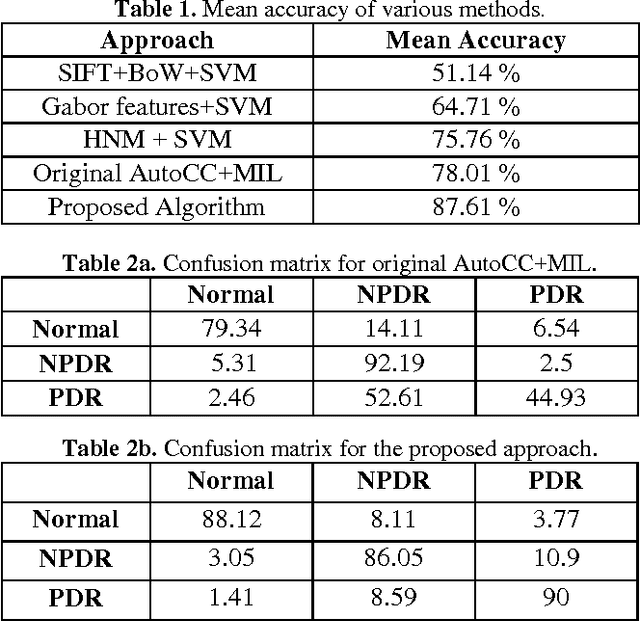

All people with diabetes have the risk of developing diabetic retinopathy (DR), a vision-threatening complication. Early detection and timely treatment can reduce the occurrence of blindness due to DR. Computer-aided diagnosis has the potential benefit of improving the accuracy and speed in DR detection. This study is concerned with automatic classification of images with microaneurysm (MA) and neovascularization (NV), two important DR clinical findings. Together with normal images, this presents a 3-class classification problem. We propose a modified color auto-correlogram feature (AutoCC) with low dimensionality that is spectrally tuned towards DR images. Recognizing the fact that the images with or without MA or NV are generally different only in small, localized regions, we propose to employ a multi-class, multiple-instance learning framework for performing the classification task using the proposed feature. Extensive experiments including comparison with a few state-of-art image classification approaches have been performed and the results suggest that the proposed approach is promising as it outperforms other methods by a large margin.
Investigating Human Factors in Image Forgery Detection
Apr 05, 2017
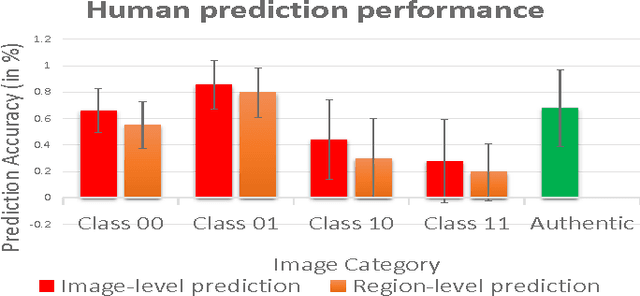
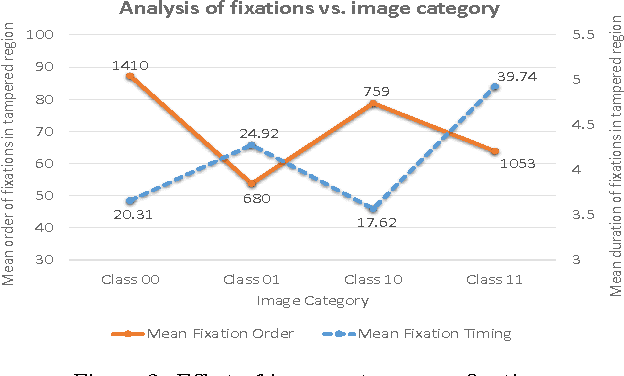
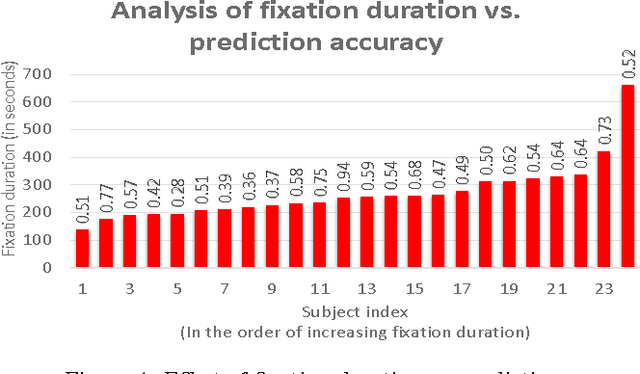
In today's age of internet and social media, one can find an enormous volume of forged images on-line. These images have been used in the past to convey falsified information and achieve harmful intentions. The spread and the effect of the social media only makes this problem more severe. While creating forged images has become easier due to software advancements, there is no automated algorithm which can reliably detect forgery. Image forgery detection can be seen as a subset of image understanding problem. Human performance is still the gold-standard for these type of problems when compared to existing state-of-art automated algorithms. We conduct a subjective evaluation test with the aid of eye-tracker to investigate into human factors associated with this problem. We compare the performance of an automated algorithm and humans for forgery detection problem. We also develop an algorithm which uses the data from the evaluation test to predict the difficulty-level of an image (the difficulty-level of an image here denotes how difficult it is for humans to detect forgery in an image. Terms such as "Easy/difficult image" will be used in the same context). The experimental results presented in this paper should facilitate development of better algorithms in the future.
Improving Vision-based Self-positioning in Intelligent Transportation Systems via Integrated Lane and Vehicle Detection
Apr 05, 2017
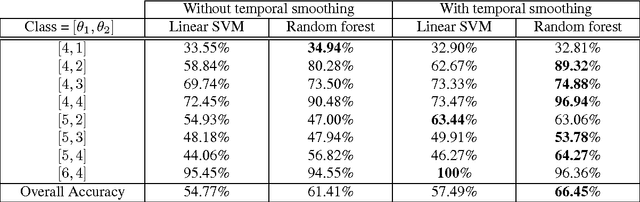
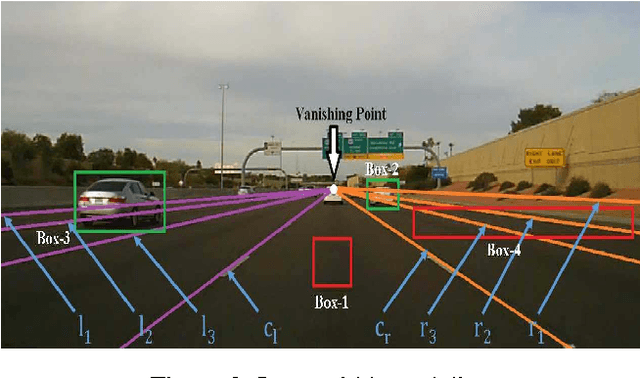

Traffic congestion is a widespread problem. Dynamic traffic routing systems and congestion pricing are getting importance in recent research. Lane prediction and vehicle density estimation is an important component of such systems. We introduce a novel problem of vehicle self-positioning which involves predicting the number of lanes on the road and vehicle's position in those lanes using videos captured by a dashboard camera. We propose an integrated closed-loop approach where we use the presence of vehicles to aid the task of self-positioning and vice-versa. To incorporate multiple factors and high-level semantic knowledge into the solution, we formulate this problem as a Bayesian framework. In the framework, the number of lanes, the vehicle's position in those lanes and the presence of other vehicles are considered as parameters. We also propose a bounding box selection scheme to reduce the number of false detections and increase the computational efficiency. We show that the number of box proposals decreases by a factor of 6 using the selection approach. It also results in large reduction in the number of false detections. The entire approach is tested on real-world videos and is found to give acceptable results.
Relative Learning from Web Images for Content-adaptive Enhancement
Apr 05, 2017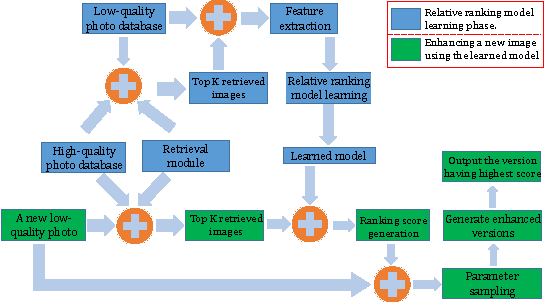


Personalized and content-adaptive image enhancement can find many applications in the age of social media and mobile computing. This paper presents a relative-learning-based approach, which, unlike previous methods, does not require matching original and enhanced images for training. This allows the use of massive online photo collections to train a ranking model for improved enhancement. We first propose a multi-level ranking model, which is learned from only relatively-labeled inputs that are automatically crawled. Then we design a novel parameter sampling scheme under this model to generate the desired enhancement parameters for a new image. For evaluation, we first verify the effectiveness and the generalization abilities of our approach, using images that have been enhanced/labeled by experts. Then we carry out subjective tests, which show that users prefer images enhanced by our approach over other existing methods.
A Structured Approach to Predicting Image Enhancement Parameters
Apr 05, 2017


Social networking on mobile devices has become a commonplace of everyday life. In addition, photo capturing process has become trivial due to the advances in mobile imaging. Hence people capture a lot of photos everyday and they want them to be visually-attractive. This has given rise to automated, one-touch enhancement tools. However, the inability of those tools to provide personalized and content-adaptive enhancement has paved way for machine-learned methods to do the same. The existing typical machine-learned methods heuristically (e.g. kNN-search) predict the enhancement parameters for a new image by relating the image to a set of similar training images. These heuristic methods need constant interaction with the training images which makes the parameter prediction sub-optimal and computationally expensive at test time which is undesired. This paper presents a novel approach to predicting the enhancement parameters given a new image using only its features, without using any training images. We propose to model the interaction between the image features and its corresponding enhancement parameters using the matrix factorization (MF) principles. We also propose a way to integrate the image features in the MF formulation. We show that our approach outperforms heuristic approaches as well as recent approaches in MF and structured prediction on synthetic as well as real-world data of image enhancement.
A Computational Approach to Relative Aesthetics
Apr 05, 2017


Computational visual aesthetics has recently become an active research area. Existing state-of-art methods formulate this as a binary classification task where a given image is predicted to be beautiful or not. In many applications such as image retrieval and enhancement, it is more important to rank images based on their aesthetic quality instead of binary-categorizing them. Furthermore, in such applications, it may be possible that all images belong to the same category. Hence determining the aesthetic ranking of the images is more appropriate. To this end, we formulate a novel problem of ranking images with respect to their aesthetic quality. We construct a new dataset of image pairs with relative labels by carefully selecting images from the popular AVA dataset. Unlike in aesthetics classification, there is no single threshold which would determine the ranking order of the images across our entire dataset. We propose a deep neural network based approach that is trained on image pairs by incorporating principles from relative learning. Results show that such relative training procedure allows our network to rank the images with a higher accuracy than a state-of-art network trained on the same set of images using binary labels.
Joint Regression and Ranking for Image Enhancement
Apr 05, 2017
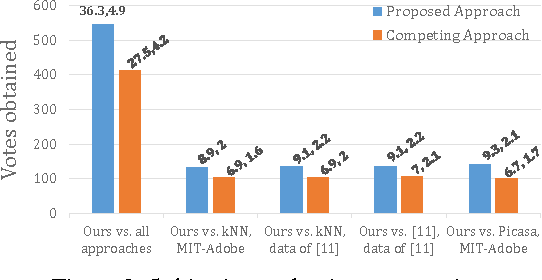
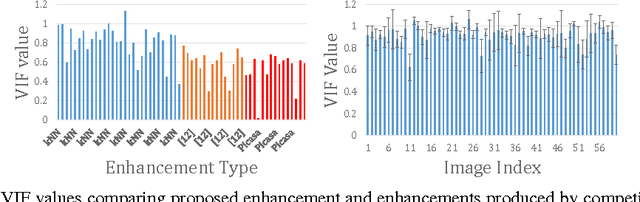

Research on automated image enhancement has gained momentum in recent years, partially due to the need for easy-to-use tools for enhancing pictures captured by ubiquitous cameras on mobile devices. Many of the existing leading methods employ machine-learning-based techniques, by which some enhancement parameters for a given image are found by relating the image to the training images with known enhancement parameters. While knowing the structure of the parameter space can facilitate search for the optimal solution, none of the existing methods has explicitly modeled and learned that structure. This paper presents an end-to-end, novel joint regression and ranking approach to model the interaction between desired enhancement parameters and images to be processed, employing a Gaussian process (GP). GP allows searching for ideal parameters using only the image features. The model naturally leads to a ranking technique for comparing images in the induced feature space. Comparative evaluation using the ground-truth based on the MIT-Adobe FiveK dataset plus subjective tests on an additional data-set were used to demonstrate the effectiveness of the proposed approach.