 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Image Hashing through Tag Embeddings
Jun 15, 2018
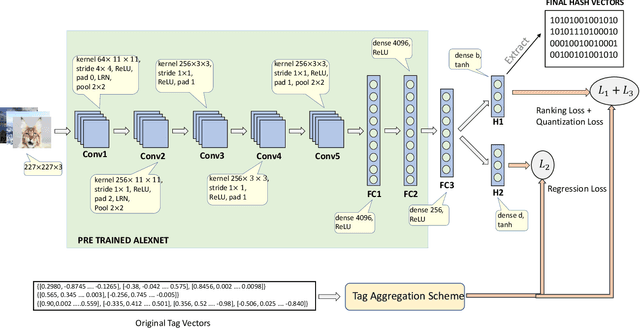
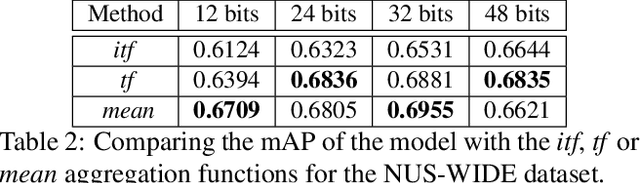
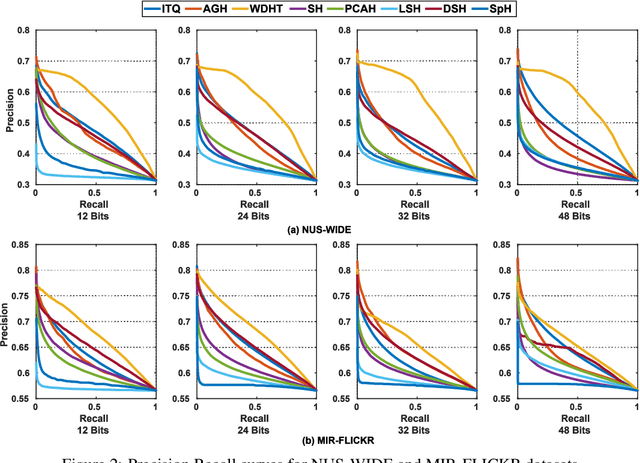
Many approaches to semantic image hashing have been formulated as supervised learning problems that utilize images and label information to learn the binary hash codes. However, large-scale labelled image data is expensive to obtain, thus imposing a restriction on the usage of such algorithms. On the other hand, unlabelled image data is abundant due to the existence of many Web image repositories. Such Web images may often come with images tags that contains useful information, although raw tags in general do not readily lead to semantic labels. Motivated by this scenario, we formulate the problem of image hashing as an unsupervised learning problem. We utilize the information contained in the user-generated tags associated with the images to learn the hash codes. More specifically, we extract the word2vec semantic embeddings of the tags and use the information contained in them for constraining the learning. Accordingly, we name our model Unsupervised Deep Hashing using Tag Embeddings (UDHT). UDHT is tested for the task of semantic image retrieval and is compared against several state-of-art unsupervised models. Results show that our approach sets a new state-of-art in the area of unsupervised image hashing.
A Computational Approach to Relative Aesthetics
Apr 05, 2017


Computational visual aesthetics has recently become an active research area. Existing state-of-art methods formulate this as a binary classification task where a given image is predicted to be beautiful or not. In many applications such as image retrieval and enhancement, it is more important to rank images based on their aesthetic quality instead of binary-categorizing them. Furthermore, in such applications, it may be possible that all images belong to the same category. Hence determining the aesthetic ranking of the images is more appropriate. To this end, we formulate a novel problem of ranking images with respect to their aesthetic quality. We construct a new dataset of image pairs with relative labels by carefully selecting images from the popular AVA dataset. Unlike in aesthetics classification, there is no single threshold which would determine the ranking order of the images across our entire dataset. We propose a deep neural network based approach that is trained on image pairs by incorporating principles from relative learning. Results show that such relative training procedure allows our network to rank the images with a higher accuracy than a state-of-art network trained on the same set of images using binary labels.
Neural Dataset Generality
May 14, 2016
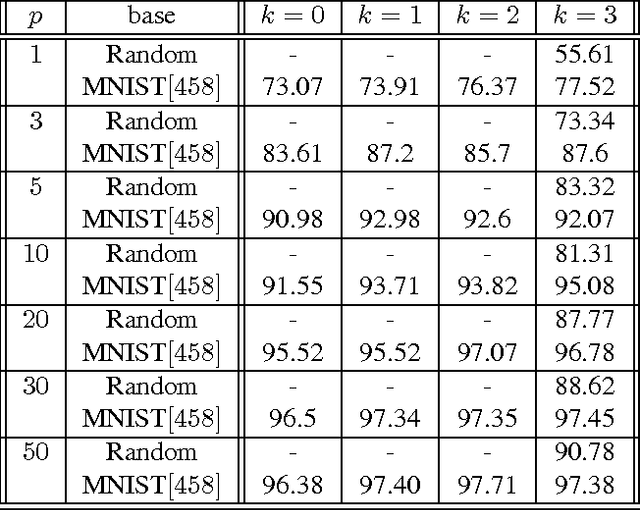

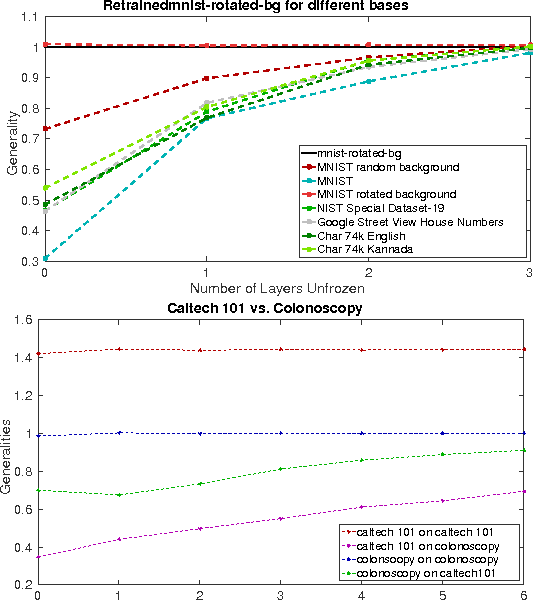
Often the filters learned by Convolutional Neural Networks (CNNs) from different datasets appear similar. This is prominent in the first few layers. This similarity of filters is being exploited for the purposes of transfer learning and some studies have been made to analyse such transferability of features. This is also being used as an initialization technique for different tasks in the same dataset or for the same task in similar datasets. Off-the-shelf CNN features have capitalized on this idea to promote their networks as best transferable and most general and are used in a cavalier manner in day-to-day computer vision tasks. It is curious that while the filters learned by these CNNs are related to the atomic structures of the images from which they are learnt, all datasets learn similar looking low-level filters. With the understanding that a dataset that contains many such atomic structures learn general filters and are therefore useful to initialize other networks with, we propose a way to analyse and quantify generality among datasets from their accuracies on transferred filters. We applied this metric on several popular character recognition, natural image and a medical image dataset, and arrived at some interesting conclusions. On further experimentation we also discovered that particular classes in a dataset themselves are more general than others.