 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Noisy User Feedback
May 06, 2022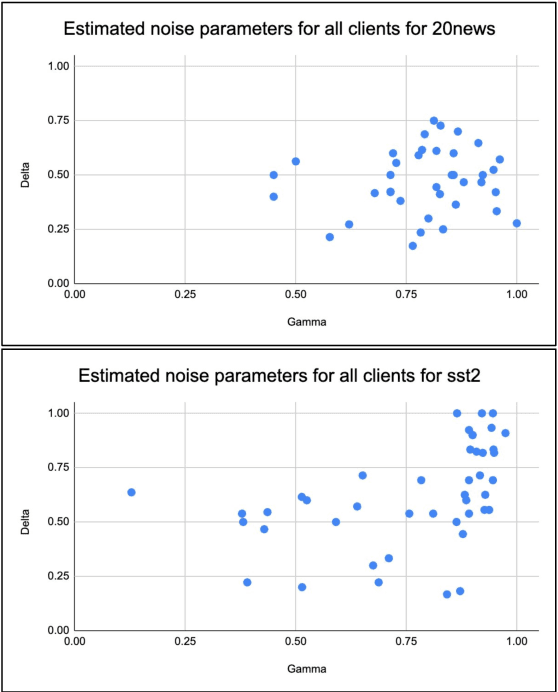



Machine Learning (ML) systems are getting increasingly popular, and drive more and more applications and services in our daily life. This has led to growing concerns over user privacy, since human interaction data typically needs to be transmitted to the cloud in order to train and improve such systems. Federated learning (FL) has recently emerged as a method for training ML models on edge devices using sensitive user data and is seen as a way to mitigate concerns over data privacy. However, since ML models are most commonly trained with label supervision, we need a way to extract labels on edge to make FL viable. In this work, we propose a strategy for training FL models using positive and negative user feedback. We also design a novel framework to study different noise patterns in user feedback, and explore how well standard noise-robust objectives can help mitigate this noise when training models in a federated setting. We evaluate our proposed training setup through detailed experiments on two text classification datasets and analyze the effects of varying levels of user reliability and feedback noise on model performance. We show that our method improves substantially over a self-training baseline, achieving performance closer to models trained with full supervision.
Evaluating the Effectiveness of Efficient Neural Architecture Search for Sentence-Pair Tasks
Oct 08, 2020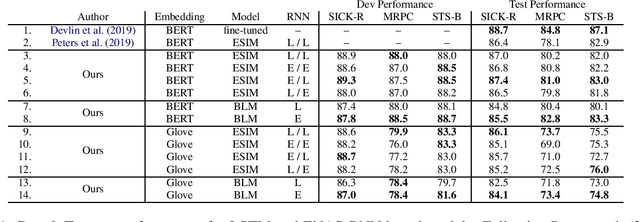
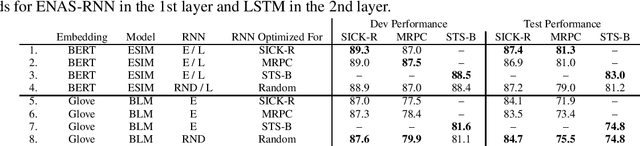

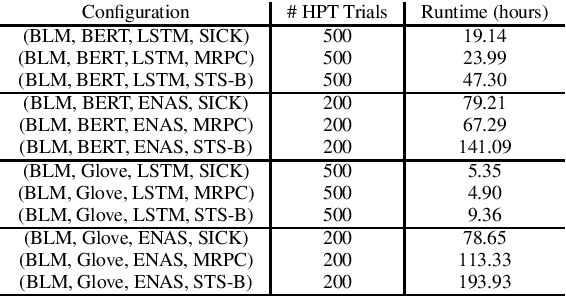
Neural Architecture Search (NAS) methods, which automatically learn entire neural model or individual neural cell architectures, have recently achieved competitive or state-of-the-art (SOTA) performance on variety of natural language processing and computer vision tasks, including language modeling, natural language inference, and image classification. In this work, we explore the applicability of a SOTA NAS algorithm, Efficient Neural Architecture Search (ENAS) (Pham et al., 2018) to two sentence pair tasks, paraphrase detection and semantic textual similarity. We use ENAS to perform a micro-level search and learn a task-optimized RNN cell architecture as a drop-in replacement for an LSTM. We explore the effectiveness of ENAS through experiments on three datasets (MRPC, SICK, STS-B), with two different models (ESIM, BiLSTM-Max), and two sets of embeddings (Glove, BERT). In contrast to prior work applying ENAS to NLP tasks, our results are mixed -- we find that ENAS architectures sometimes, but not always, outperform LSTMs and perform similarly to random architecture search.
Context-Based Quotation Recommendation
May 17, 2020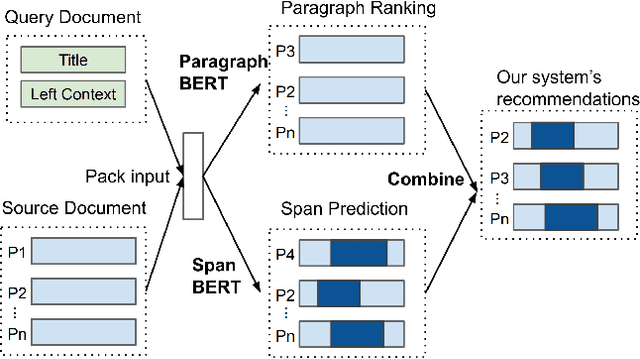

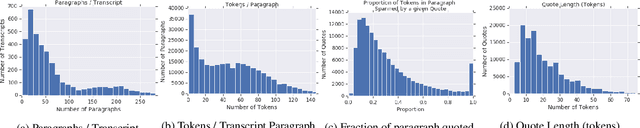

While composing a new document, anything from a news article to an email or essay, authors often utilize direct quotes from a variety of sources. Although an author may know what point they would like to make, selecting an appropriate quote for the specific context may be time-consuming and difficult. We therefore propose a novel context-aware quote recommendation system which utilizes the content an author has already written to generate a ranked list of quotable paragraphs and spans of tokens from a given source document. We approach quote recommendation as a variant of open-domain question answering and adapt the state-of-the-art BERT-based methods from open-QA to our task. We conduct experiments on a collection of speech transcripts and associated news articles, evaluating models' paragraph ranking and span prediction performances. Our experiments confirm the strong performance of BERT-based methods on this task, which outperform bag-of-words and neural ranking baselines by more than 30% relative across all ranking metrics. Qualitative analyses show the difficulty of the paragraph and span recommendation tasks and confirm the quotability of the best BERT model's predictions, even if they are not the true selected quotes from the original news articles.