 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALICO: Conversational Agent Localization via Synthetic Data Generation
Dec 06, 2024



We present CALICO, a method to fine-tune Large Language Models (LLMs) to localize conversational agent training data from one language to another. For slots (named entities), CALICO supports three operations: verbatim copy, literal translation, and localization, i.e. generating slot values more appropriate in the target language, such as city and airport names located in countries where the language is spoken. Furthermore, we design an iterative filtering mechanism to discard noisy generated samples, which we show boosts the performance of the downstream conversational agent. To prove the effectiveness of CALICO, we build and release a new human-localized (HL) version of the MultiATIS++ travel information test set in 8 languages. Compared to the original human-translated (HT) version of the test set, we show that our new HL version is more challenging. We also show that CALICO out-performs state-of-the-art LINGUIST (which relies on literal slot translation out of context) both on the HT case, where CALICO generates more accurate slot translations, and on the HL case, where CALICO generates localized slots which are closer to the HL test set.
Partial Federated Learning
Mar 03, 2024
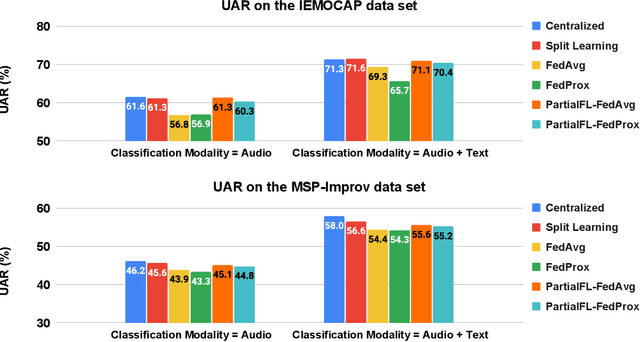
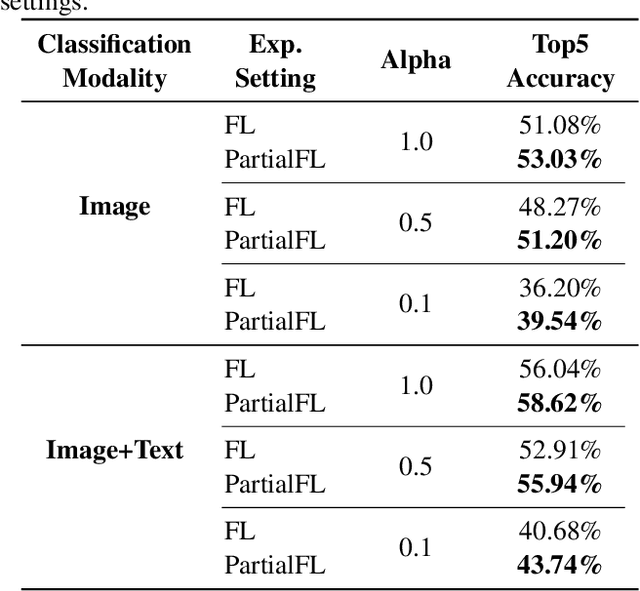
Federated Learning (FL) is a popular algorithm to train machine learning models on user data constrained to edge devices (for example, mobile phones) due to privacy concerns. Typically, FL is trained with the assumption that no part of the user data can be egressed from the edge. However, in many production settings, specific data-modalities/meta-data are limited to be on device while others are not. For example, in commercial SLU systems, it is typically desired to prevent transmission of biometric signals (such as audio recordings of the input prompt) to the cloud, but egress of locally (i.e. on the edge device) transcribed text to the cloud may be possible. In this work, we propose a new algorithm called Partial Federated Learning (PartialFL), where a machine learning model is trained using data where a subset of data modalities or their intermediate representations can be made available to the server. We further restrict our model training by preventing the egress of data labels to the cloud for better privacy, and instead use a contrastive learning based model objective. We evaluate our approach on two different multi-modal datasets and show promising results with our proposed approach.
Coordinated Replay Sample Selection for Continual Federated Learning
Oct 23, 2023



Continual Federated Learning (CFL) combines Federated Learning (FL), the decentralized learning of a central model on a number of client devices that may not communicate their data, and Continual Learning (CL), the learning of a model from a continual stream of data without keeping the entire history. In CL, the main challenge is \textit{forgetting} what was learned from past data. While replay-based algorithms that keep a small pool of past training data are effective to reduce forgetting, only simple replay sample selection strategies have been applied to CFL in prior work, and no previous work has explored coordination among clients for better sample selection. To bridge this gap, we adapt a replay sample selection objective based on loss gradient diversity to CFL and propose a new relaxation-based selection of samples to optimize the objective. Next, we propose a practical algorithm to coordinate gradient-based replay sample selection across clients without communicating private data. We benchmark our coordinated and uncoordinated replay sample selection algorithms against random sampling-based baselines with language models trained on a large scale de-identified real-world text dataset. We show that gradient-based sample selection methods both boost performance and reduce forgetting compared to random sampling methods, with our coordination method showing gains early in the low replay size regime (when the budget for storing past data is small).
End-to-end spoken language understanding using joint CTC loss and self-supervised, pretrained acoustic encoders
May 04, 2023



It is challenging to extract semantic meanings directly from audio signals in spoken language understanding (SLU), due to the lack of textual information. Popular end-to-end (E2E) SLU models utilize sequence-to-sequence automatic speech recognition (ASR) models to extract textual embeddings as input to infer semantics, which, however, require computationally expensive auto-regressive decoding. In this work, we leverage self-supervised acoustic encoders fine-tuned with Connectionist Temporal Classification (CTC) to extract textual embeddings and use joint CTC and SLU losses for utterance-level SLU tasks. Experiments show that our model achieves 4% absolute improvement over the the state-of-the-art (SOTA) dialogue act classification model on the DSTC2 dataset and 1.3% absolute improvement over the SOTA SLU model on the SLURP dataset.
Federated Learning with Noisy User Feedback
May 06, 2022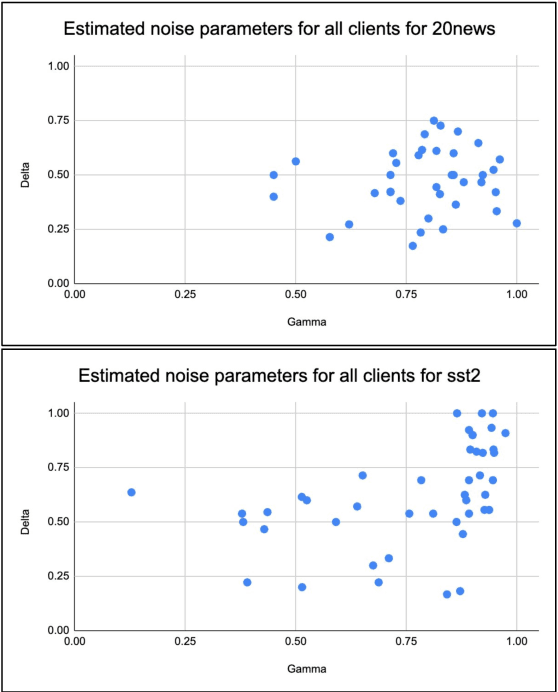



Machine Learning (ML) systems are getting increasingly popular, and drive more and more applications and services in our daily life. This has led to growing concerns over user privacy, since human interaction data typically needs to be transmitted to the cloud in order to train and improve such systems. Federated learning (FL) has recently emerged as a method for training ML models on edge devices using sensitive user data and is seen as a way to mitigate concerns over data privacy. However, since ML models are most commonly trained with label supervision, we need a way to extract labels on edge to make FL viable. In this work, we propose a strategy for training FL models using positive and negative user feedback. We also design a novel framework to study different noise patterns in user feedback, and explore how well standard noise-robust objectives can help mitigate this noise when training models in a federated setting. We evaluate our proposed training setup through detailed experiments on two text classification datasets and analyze the effects of varying levels of user reliability and feedback noise on model performance. We show that our method improves substantially over a self-training baseline, achieving performance closer to models trained with full supervision.
Training Mixed-Domain Translation Models via Federated Learning
May 03, 2022



Training mixed-domain translation models is a complex task that demands tailored architectures and costly data preparation techniques. In this work, we leverage federated learning (FL) in order to tackle the problem. Our investigation demonstrates that with slight modifications in the training process, neural machine translation (NMT) engines can be easily adapted when an FL-based aggregation is applied to fuse different domains. Experimental results also show that engines built via FL are able to perform on par with state-of-the-art baselines that rely on centralized training techniques. We evaluate our hypothesis in the presence of five datasets with different sizes, from different domains, to translate from German into English and discuss how FL and NMT can mutually benefit from each other. In addition to providing benchmarking results on the union of FL and NMT, we also propose a novel technique to dynamically control the communication bandwidth by selecting impactful parameters during FL updates. This is a significant achievement considering the large size of NMT engines that need to be exchanged between FL parties.
Learnings from Federated Learning in the Real world
Feb 08, 2022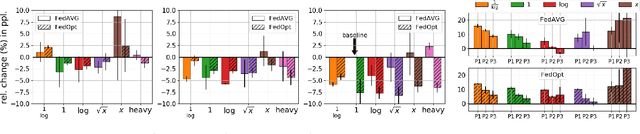
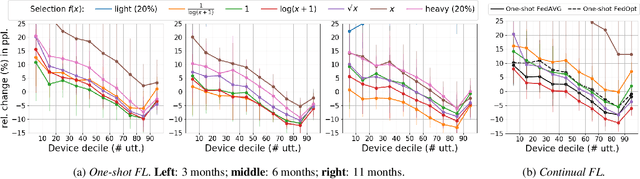
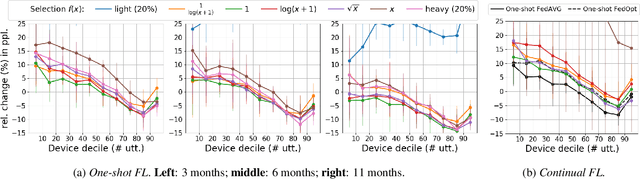
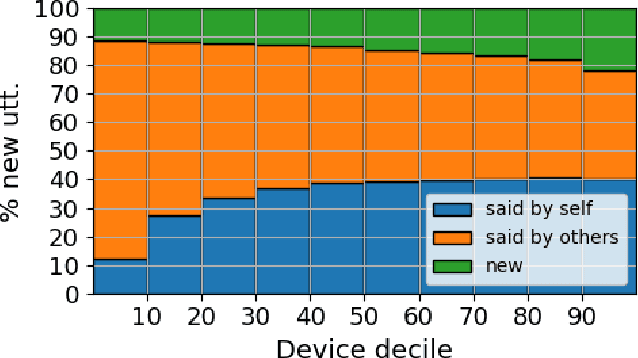
Federated Learning (FL) applied to real world data may suffer from several idiosyncrasies. One such idiosyncrasy is the data distribution across devices. Data across devices could be distributed such that there are some "heavy devices" with large amounts of data while there are many "light users" with only a handful of data points. There also exists heterogeneity of data across devices. In this study, we evaluate the impact of such idiosyncrasies on Natural Language Understanding (NLU) models trained using FL. We conduct experiments on data obtained from a large scale NLU system serving thousands of devices and show that simple non-uniform device selection based on the number of interactions at each round of FL training boosts the performance of the model. This benefit is further amplified in continual FL on consecutive time periods, where non-uniform sampling manages to swiftly catch up with FL methods using all data at once.
Encoding Syntactic Knowledge in Transformer Encoder for Intent Detection and Slot Filling
Dec 21, 2020



We propose a novel Transformer encoder-based architecture with syntactical knowledge encoded for intent detection and slot filling. Specifically, we encode syntactic knowledge into the Transformer encoder by jointly training it to predict syntactic parse ancestors and part-of-speech of each token via multi-task learning. Our model is based on self-attention and feed-forward layers and does not require external syntactic information to be available at inference time. Experiments show that on two benchmark datasets, our models with only two Transformer encoder layers achieve state-of-the-art results. Compared to the previously best performed model without pre-training, our models achieve absolute F1 score and accuracy improvement of 1.59% and 0.85% for slot filling and intent detection on the SNIPS dataset, respectively. Our models also achieve absolute F1 score and accuracy improvement of 0.1% and 0.34% for slot filling and intent detection on the ATIS dataset, respectively, over the previously best performed model. Furthermore, the visualization of the self-attention weights illustrates the benefits of incorporating syntactic information during training.
Hierarchical Affinity Propagation
Feb 14, 2012



Affinity propagation is an exemplar-based clustering algorithm that finds a set of data-points that best exemplify the data, and associates each datapoint with one exemplar. We extend affinity propagation in a principled way to solve the hierarchical clustering problem, which arises in a variety of domains including biology, sensor networks and decision making in operational research. We derive an inference algorithm that operates by propagating information up and down the hierarchy, and is efficient despite the high-order potentials required for the graphical model formulation. We demonstrate that our method outperforms greedy techniques that cluster one layer at a time. We show that on an artificial dataset designed to mimic the HIV-strain mutation dynamics, our method outperforms related methods. For real HIV sequences, where the ground truth is not available, we show our method achieves better results, in terms of the underlying objective function, and show the results correspond meaningfully to geographical location and strain subtypes. Finally we report results on using the method for the analysis of mass spectra, showing it performs favorably compared to state-of-the-art methods.