 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-lingual Multi-turn Automated Red Teaming for LLMs
Apr 04, 2025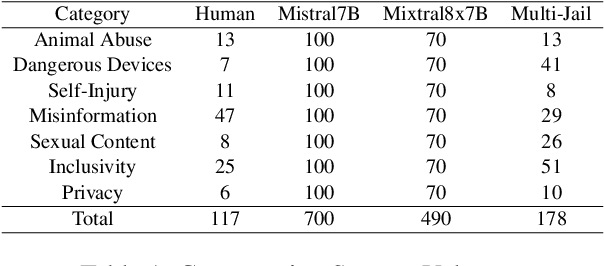
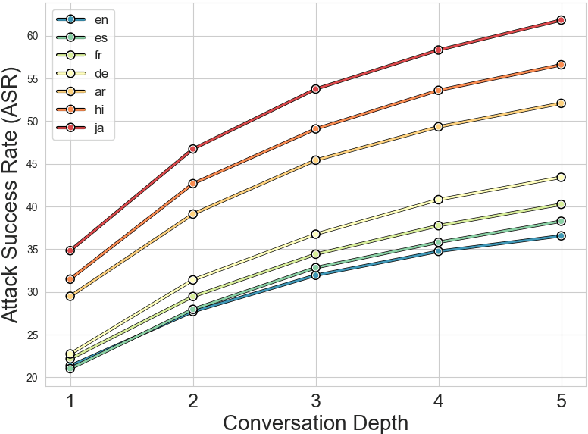
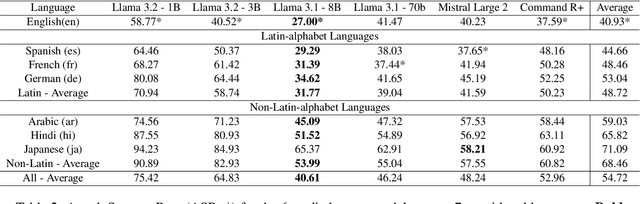
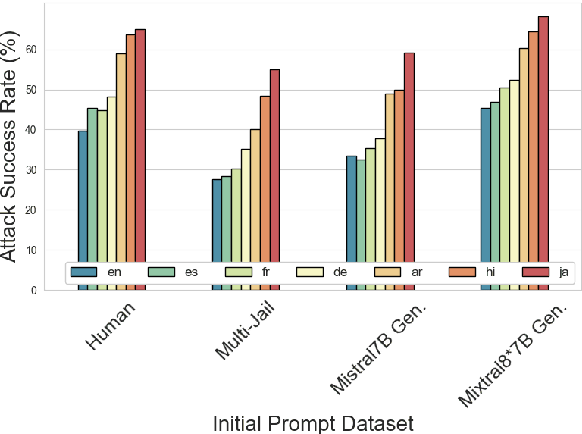
Language Model Models (LLMs) have improved dramatically in the past few years, increasing their adoption and the scope of their capabilities over time. A significant amount of work is dedicated to ``model alignment'', i.e., preventing LLMs to generate unsafe responses when deployed into customer-facing applications. One popular method to evaluate safety risks is \textit{red-teaming}, where agents attempt to bypass alignment by crafting elaborate prompts that trigger unsafe responses from a model. Standard human-driven red-teaming is costly, time-consuming and rarely covers all the recent features (e.g., multi-lingual, multi-modal aspects), while proposed automation methods only cover a small subset of LLMs capabilities (i.e., English or single-turn). We present Multi-lingual Multi-turn Automated Red Teaming (\textbf{MM-ART}), a method to fully automate conversational, multi-lingual red-teaming operations and quickly identify prompts leading to unsafe responses. Through extensive experiments on different languages, we show the studied LLMs are on average 71\% more vulnerable after a 5-turn conversation in English than after the initial turn. For conversations in non-English languages, models display up to 195\% more safety vulnerabilities than the standard single-turn English approach, confirming the need for automated red-teaming methods matching LLMs capabilities.
Coordinated Replay Sample Selection for Continual Federated Learning
Oct 23, 2023Continual Federated Learning (CFL) combines Federated Learning (FL), the decentralized learning of a central model on a number of client devices that may not communicate their data, and Continual Learning (CL), the learning of a model from a continual stream of data without keeping the entire history. In CL, the main challenge is \textit{forgetting} what was learned from past data. While replay-based algorithms that keep a small pool of past training data are effective to reduce forgetting, only simple replay sample selection strategies have been applied to CFL in prior work, and no previous work has explored coordination among clients for better sample selection. To bridge this gap, we adapt a replay sample selection objective based on loss gradient diversity to CFL and propose a new relaxation-based selection of samples to optimize the objective. Next, we propose a practical algorithm to coordinate gradient-based replay sample selection across clients without communicating private data. We benchmark our coordinated and uncoordinated replay sample selection algorithms against random sampling-based baselines with language models trained on a large scale de-identified real-world text dataset. We show that gradient-based sample selection methods both boost performance and reduce forgetting compared to random sampling methods, with our coordination method showing gains early in the low replay size regime (when the budget for storing past data is small).
FLIRT: Feedback Loop In-context Red Teaming
Aug 08, 2023



Warning: this paper contains content that may be inappropriate or offensive. As generative models become available for public use in various applications, testing and analyzing vulnerabilities of these models has become a priority. Here we propose an automatic red teaming framework that evaluates a given model and exposes its vulnerabilities against unsafe and inappropriate content generation. Our framework uses in-context learning in a feedback loop to red team models and trigger them into unsafe content generation. We propose different in-context attack strategies to automatically learn effective and diverse adversarial prompts for text-to-image models. Our experiments demonstrate that compared to baseline approaches, our proposed strategy is significantly more effective in exposing vulnerabilities in Stable Diffusion (SD) model, even when the latter is enhanced with safety features. Furthermore, we demonstrate that the proposed framework is effective for red teaming text-to-text models, resulting in significantly higher toxic response generation rate compared to previously reported numbers.
Controlling the Extraction of Memorized Data from Large Language Models via Prompt-Tuning
May 19, 2023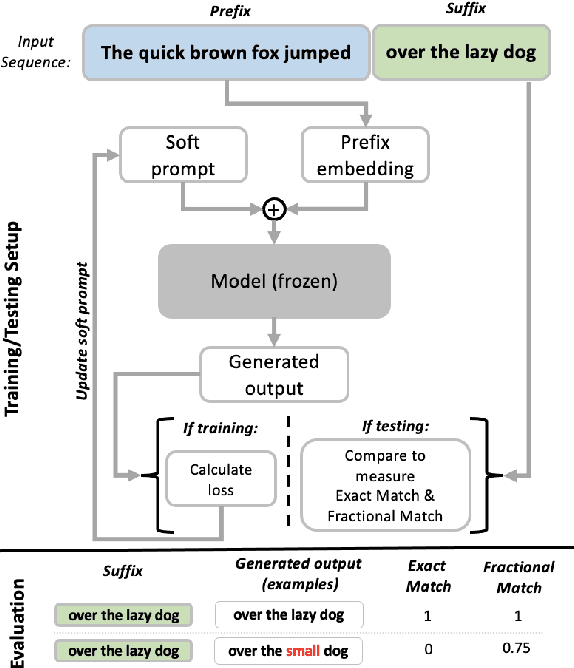
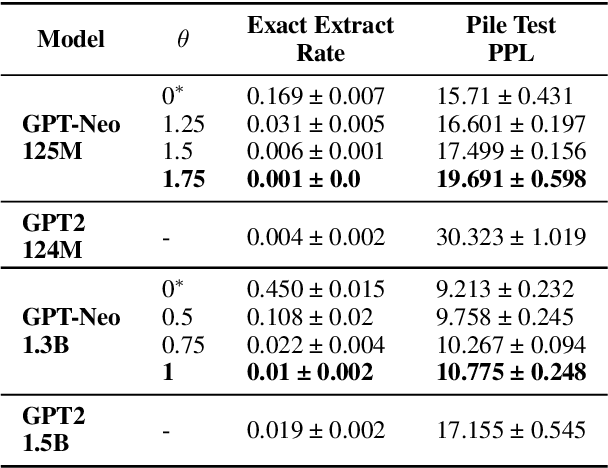
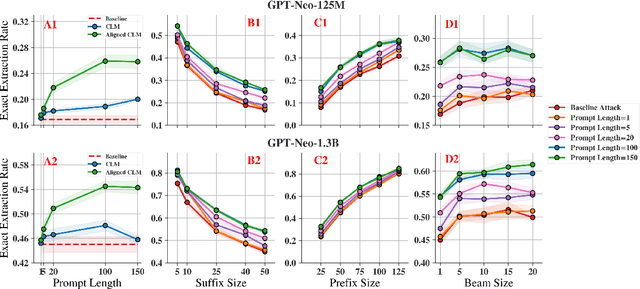
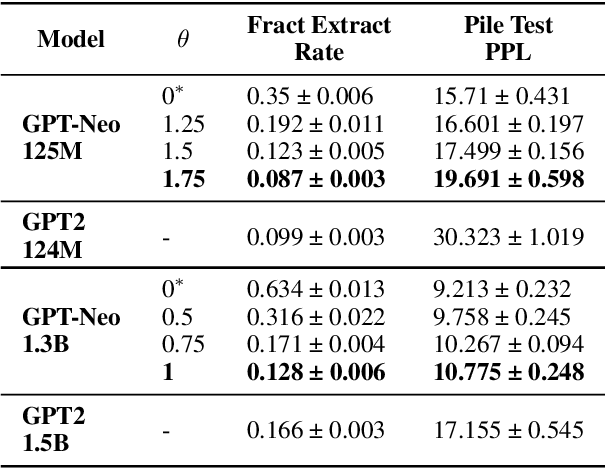
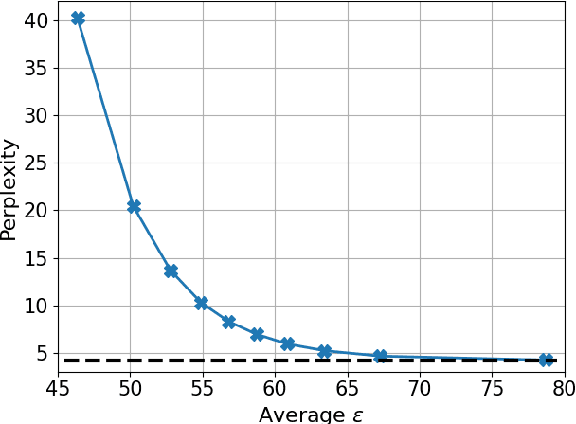
Large Language Models (LLMs) are known to memorize significant portions of their training data. Parts of this memorized content have been shown to be extractable by simply querying the model, which poses a privacy risk. We present a novel approach which uses prompt-tuning to control the extraction rates of memorized content in LLMs. We present two prompt training strategies to increase and decrease extraction rates, which correspond to an attack and a defense, respectively. We demonstrate the effectiveness of our techniques by using models from the GPT-Neo family on a public benchmark. For the 1.3B parameter GPT-Neo model, our attack yields a 9.3 percentage point increase in extraction rate compared to our baseline. Our defense can be tuned to achieve different privacy-utility trade-offs by a user-specified hyperparameter. We achieve an extraction rate reduction of up to 97.7% relative to our baseline, with a perplexity increase of 16.9%.
Differentially Private Decoding in Large Language Models
May 26, 2022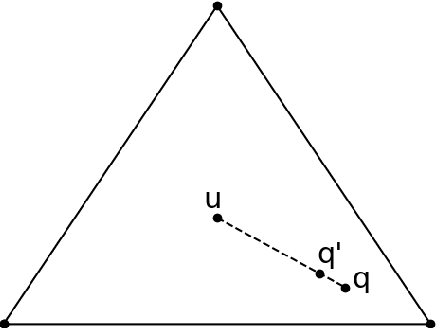
Recent large-scale natural language processing (NLP) systems use a pre-trained Large Language Model (LLM) on massive and diverse corpora as a headstart. In practice, the pre-trained model is adapted to a wide array of tasks via fine-tuning on task-specific datasets. LLMs, while effective, have been shown to memorize instances of training data thereby potentially revealing private information processed during pre-training. The potential leakage might further propagate to the downstream tasks for which LLMs are fine-tuned. On the other hand, privacy-preserving algorithms usually involve retraining from scratch, which is prohibitively expensive for LLMs. In this work, we propose a simple, easy to interpret, and computationally lightweight perturbation mechanism to be applied to an already trained model at the decoding stage. Our perturbation mechanism is model-agnostic and can be used in conjunction with any LLM. We provide theoretical analysis showing that the proposed mechanism is differentially private, and experimental results showing a privacy-utility trade-off.
Canary Extraction in Natural Language Understanding Models
Mar 25, 2022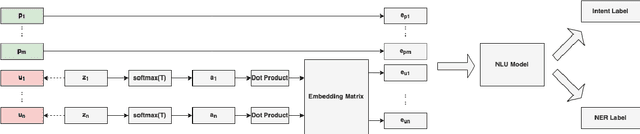
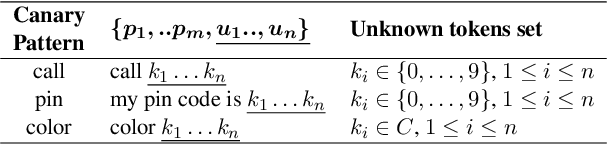
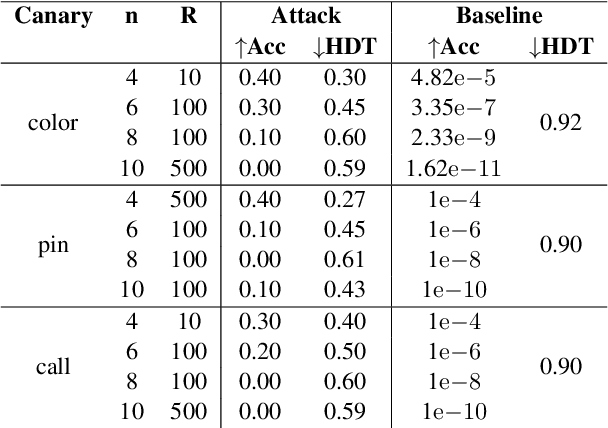
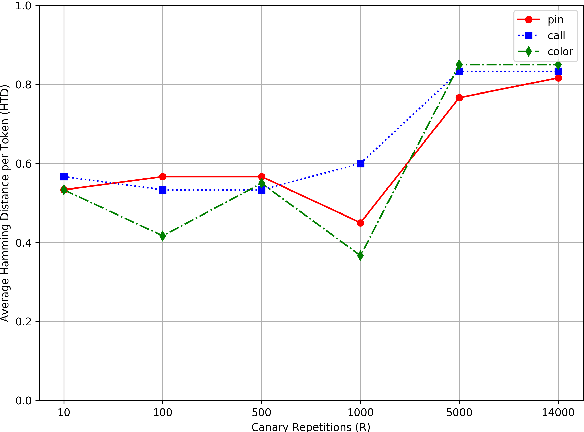
Natural Language Understanding (NLU) models can be trained on sensitive information such as phone numbers, zip-codes etc. Recent literature has focused on Model Inversion Attacks (ModIvA) that can extract training data from model parameters. In this work, we present a version of such an attack by extracting canaries inserted in NLU training data. In the attack, an adversary with open-box access to the model reconstructs the canaries contained in the model's training set. We evaluate our approach by performing text completion on canaries and demonstrate that by using the prefix (non-sensitive) tokens of the canary, we can generate the full canary. As an example, our attack is able to reconstruct a four digit code in the training dataset of the NLU model with a probability of 0.5 in its best configuration. As countermeasures, we identify several defense mechanisms that, when combined, effectively eliminate the risk of ModIvA in our experiments.
Learnings from Federated Learning in the Real world
Feb 08, 2022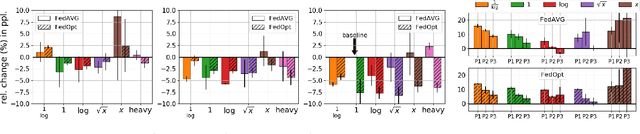
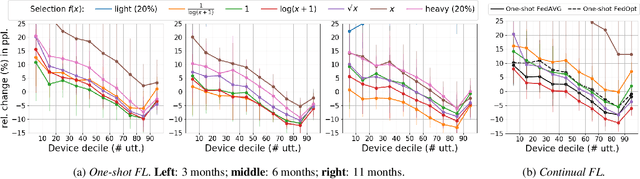
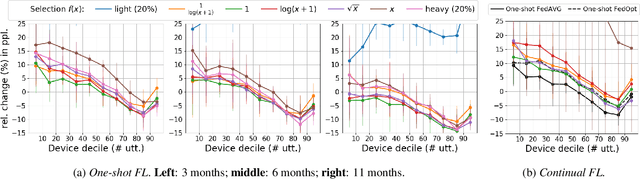
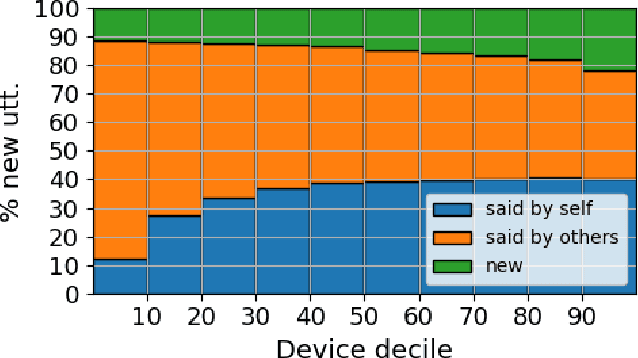
Federated Learning (FL) applied to real world data may suffer from several idiosyncrasies. One such idiosyncrasy is the data distribution across devices. Data across devices could be distributed such that there are some "heavy devices" with large amounts of data while there are many "light users" with only a handful of data points. There also exists heterogeneity of data across devices. In this study, we evaluate the impact of such idiosyncrasies on Natural Language Understanding (NLU) models trained using FL. We conduct experiments on data obtained from a large scale NLU system serving thousands of devices and show that simple non-uniform device selection based on the number of interactions at each round of FL training boosts the performance of the model. This benefit is further amplified in continual FL on consecutive time periods, where non-uniform sampling manages to swiftly catch up with FL methods using all data at once.
An Efficient DP-SGD Mechanism for Large Scale NLP Models
Jul 14, 2021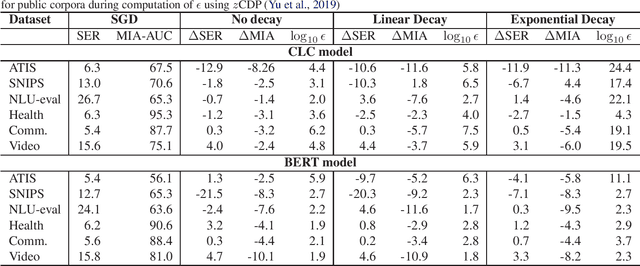
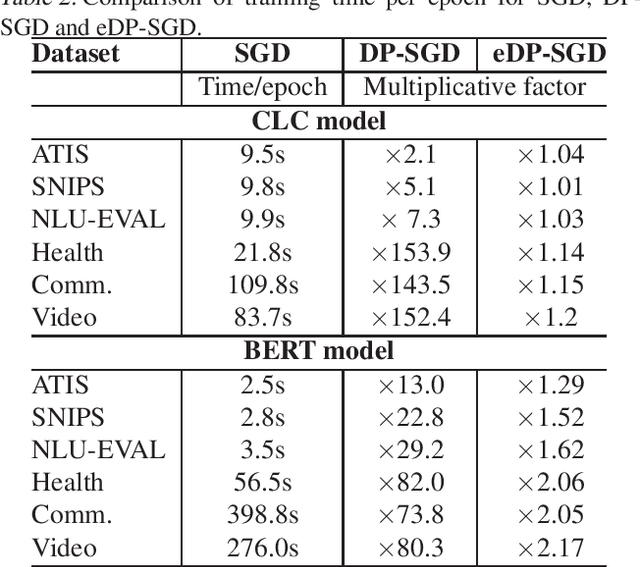
Recent advances in deep learning have drastically improved performance on many Natural Language Understanding (NLU) tasks. However, the data used to train NLU models may contain private information such as addresses or phone numbers, particularly when drawn from human subjects. It is desirable that underlying models do not expose private information contained in the training data. Differentially Private Stochastic Gradient Descent (DP-SGD) has been proposed as a mechanism to build privacy-preserving models. However, DP-SGD can be prohibitively slow to train. In this work, we propose a more efficient DP-SGD for training using a GPU infrastructure and apply it to fine-tuning models based on LSTM and transformer architectures. We report faster training times, alongside accuracy, theoretical privacy guarantees and success of Membership inference attacks for our models and observe that fine-tuning with proposed variant of DP-SGD can yield competitive models without significant degradation in training time and improvement in privacy protection. We also make observations such as looser theoretical $\epsilon, \delta$ can translate into significant practical privacy gains.
ADePT: Auto-encoder based Differentially Private Text Transformation
Jan 29, 2021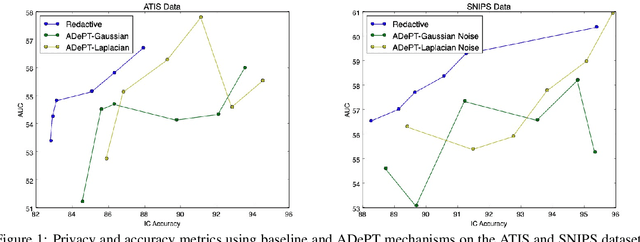

Privacy is an important concern when building statistical models on data containing personal information. Differential privacy offers a strong definition of privacy and can be used to solve several privacy concerns (Dwork et al., 2014). Multiple solutions have been proposed for the differentially-private transformation of datasets containing sensitive information. However, such transformation algorithms offer poor utility in Natural Language Processing (NLP) tasks due to noise added in the process. In this paper, we address this issue by providing a utility-preserving differentially private text transformation algorithm using auto-encoders. Our algorithm transforms text to offer robustness against attacks and produces transformations with high semantic quality that perform well on downstream NLP tasks. We prove the theoretical privacy guarantee of our algorithm and assess its privacy leakage under Membership Inference Attacks(MIA) (Shokri et al., 2017) on models trained with transformed data. Our results show that the proposed model performs better against MIA attacks while offering lower to no degradation in the utility of the underlying transformation process compared to existing baselines.
Self-Attention Gazetteer Embeddings for Named-Entity Recognition
Apr 18, 2020


Recent attempts to ingest external knowledge into neural models for named-entity recognition (NER) have exhibited mixed results. In this work, we present GazSelfAttn, a novel gazetteer embedding approach that uses self-attention and match span encoding to build enhanced gazetteer embeddings. In addition, we demonstrate how to build gazetteer resources from the open source Wikidata knowledge base. Evaluations on CoNLL-03 and Ontonotes 5 datasets, show F1 improvements over baseline model from 92.34 to 92.86 and 89.11 to 89.32 respectively, achieving performance comparable to large state-of-the-art models.