 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attention Gazetteer Embeddings for Named-Entity Recognition
Apr 18, 2020
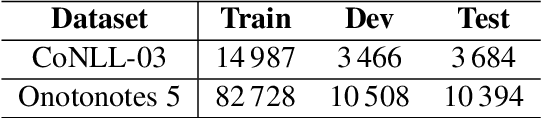


Recent attempts to ingest external knowledge into neural models for named-entity recognition (NER) have exhibited mixed results. In this work, we present GazSelfAttn, a novel gazetteer embedding approach that uses self-attention and match span encoding to build enhanced gazetteer embeddings. In addition, we demonstrate how to build gazetteer resources from the open source Wikidata knowledge base. Evaluations on CoNLL-03 and Ontonotes 5 datasets, show F1 improvements over baseline model from 92.34 to 92.86 and 89.11 to 89.32 respectively, achieving performance comparable to large state-of-the-art models.
F10-SGD: Fast Training of Elastic-net Linear Models for Text Classification and Named-entity Recognition
Feb 27, 2019
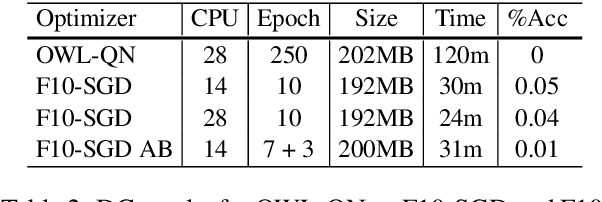


Voice-assistants text classification and named-entity recognition (NER) models are trained on millions of example utterances. Because of the large datasets, long training time is one of the bottlenecks for releasing improved models. In this work, we develop F10-SGD, a fast optimizer for text classification and NER elastic-net linear models. On internal datasets, F10-SGD provides 4x reduction in training time compared to the OWL-QN optimizer without loss of accuracy or increase in model size. Furthermore, we incorporate biased sampling that prioritizes harder examples towards the end of the training. As a result, in addition to faster training, we were able to obtain statistically significant accuracy improvements for NER. On public datasets, F10-SGD obtains 22% faster training time compared to FastText for text classification. And, 4x reduction in training time compared to CRFSuite OWL-QN for NER.
Active Learning for New Domains in Natural Language Understanding
Oct 03, 2018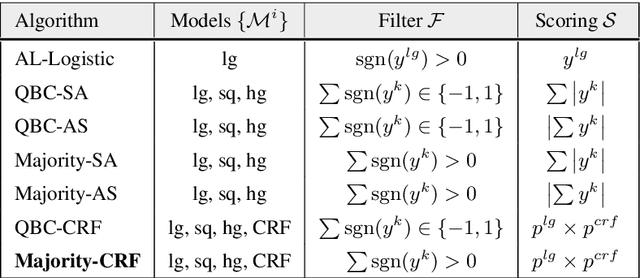
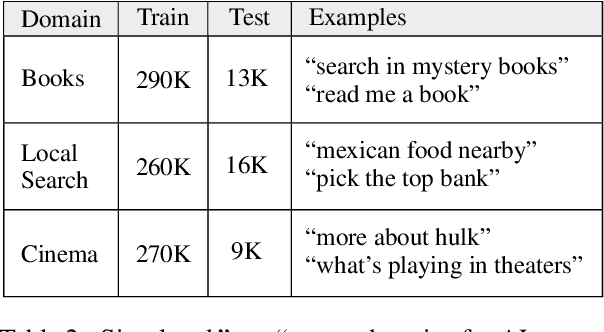
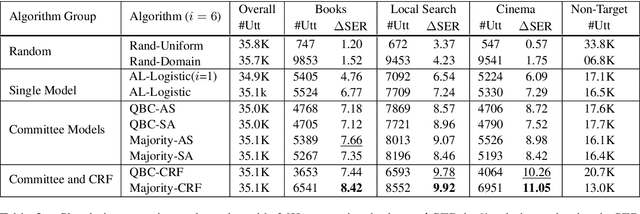
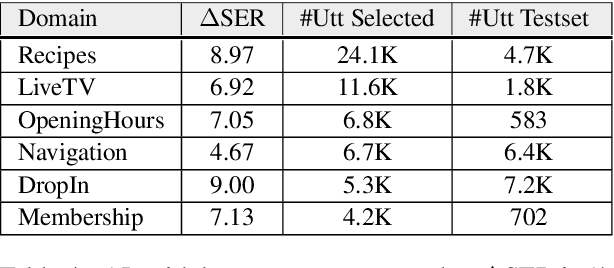
We explore active learning (AL) utterance selection for improving the accuracy of new underrepresented domains in a natural language understanding (NLU) system. Moreover, we propose an AL algorithm called Majority-CRF that uses an ensemble of classification and sequence labeling models to guide utterance selection for annotation. Experiments with three domains show that Majority-CRF achieves 6.6%-9% relative error rate reduction compared to random sampling with the same annotation budget, and statistically significant improvements compared to other AL approaches. Additionally, case studies with human-in-the-loop AL on six new domains show 4.6%-9% improvement on an existing NLU system.
Steepest Ascent Hill Climbing For A Mathematical Problem
Oct 02, 2010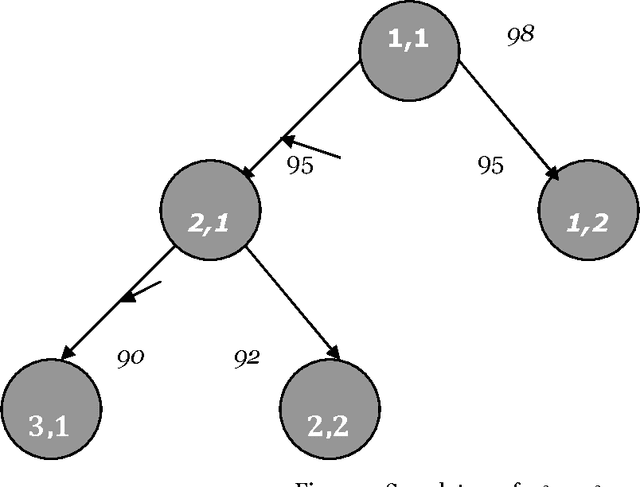
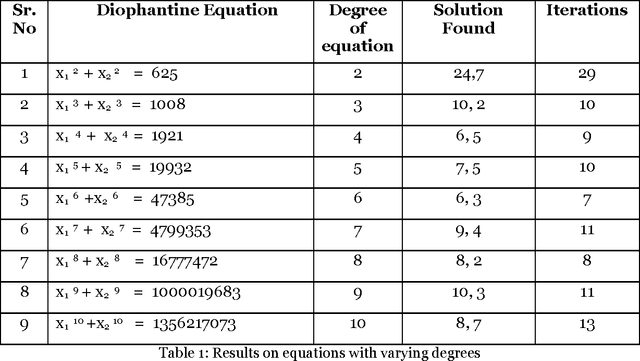
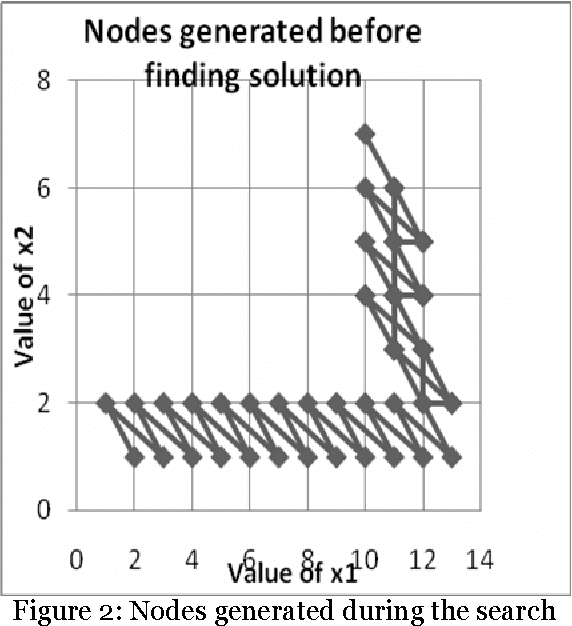

The paper proposes artificial intelligence technique called hill climbing to find numerical solutions of Diophantine Equations. Such equations are important as they have many applications in fields like public key cryptography, integer factorization, algebraic curves, projective curves and data dependency in super computers. Importantly, it has been proved that there is no general method to find solutions of such equations. This paper is an attempt to find numerical solutions of Diophantine equations using steepest ascent version of Hill Climbing. The method, which uses tree representation to depict possible solutions of Diophantine equations, adopts a novel methodology to generate successors. The heuristic function used help to make the process of finding solution as a minimization process. The work illustrates the effectiveness of the proposed methodology using a class of Diophantine equations given by a1. x1 p1 + a2. x2 p2 + ...... + an . xn pn = N where ai and N are integers. The experimental results validate that the procedure proposed is successful in finding solutions of Diophantine Equations with sufficiently large powers and large number of variables.