 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF10-SGD: Fast Training of Elastic-net Linear Models for Text Classification and Named-entity Recognition
Feb 27, 2019
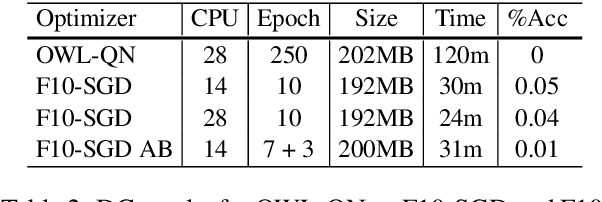


Voice-assistants text classification and named-entity recognition (NER) models are trained on millions of example utterances. Because of the large datasets, long training time is one of the bottlenecks for releasing improved models. In this work, we develop F10-SGD, a fast optimizer for text classification and NER elastic-net linear models. On internal datasets, F10-SGD provides 4x reduction in training time compared to the OWL-QN optimizer without loss of accuracy or increase in model size. Furthermore, we incorporate biased sampling that prioritizes harder examples towards the end of the training. As a result, in addition to faster training, we were able to obtain statistically significant accuracy improvements for NER. On public datasets, F10-SGD obtains 22% faster training time compared to FastText for text classification. And, 4x reduction in training time compared to CRFSuite OWL-QN for NER.