 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Opinion-based Question Answering Systems Through Label Error Detection and Overwrite
Jun 13, 2023Label error is a ubiquitous problem in annotated data. Large amounts of label error substantially degrades the quality of deep learning models. Existing methods to tackle the label error problem largely focus on the classification task, and either rely on task specific architecture or require non-trivial additional computations, which is undesirable or even unattainable for industry usage. In this paper, we propose LEDO: a model-agnostic and computationally efficient framework for Label Error Detection and Overwrite. LEDO is based on Monte Carlo Dropout combined with uncertainty metrics, and can be easily generalized to multiple tasks and data sets. Applying LEDO to an industry opinion-based question answering system demonstrates it is effective at improving accuracy in all the core models. Specifically, LEDO brings 1.1% MRR gain for the retrieval model, 1.5% PR AUC improvement for the machine reading comprehension model, and 0.9% rise in the Average Precision for the ranker, on top of the strong baselines with a large-scale social media dataset. Importantly, LEDO is computationally efficient compared to methods that require loss function change, and cost-effective as the resulting data can be used in the same continuous training pipeline for production. Further analysis shows that these gains come from an improved decision boundary after cleaning the label errors existed in the training data.
Self-Attention Gazetteer Embeddings for Named-Entity Recognition
Apr 18, 2020
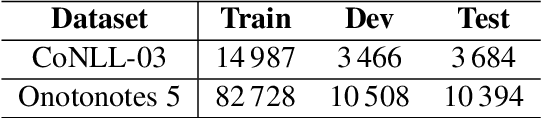


Recent attempts to ingest external knowledge into neural models for named-entity recognition (NER) have exhibited mixed results. In this work, we present GazSelfAttn, a novel gazetteer embedding approach that uses self-attention and match span encoding to build enhanced gazetteer embeddings. In addition, we demonstrate how to build gazetteer resources from the open source Wikidata knowledge base. Evaluations on CoNLL-03 and Ontonotes 5 datasets, show F1 improvements over baseline model from 92.34 to 92.86 and 89.11 to 89.32 respectively, achieving performance comparable to large state-of-the-art models.
F10-SGD: Fast Training of Elastic-net Linear Models for Text Classification and Named-entity Recognition
Feb 27, 2019
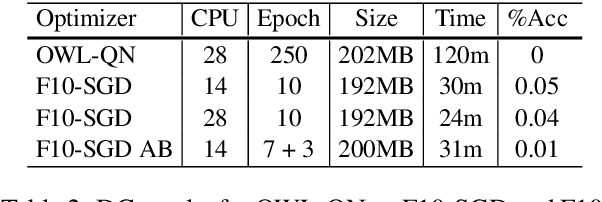


Voice-assistants text classification and named-entity recognition (NER) models are trained on millions of example utterances. Because of the large datasets, long training time is one of the bottlenecks for releasing improved models. In this work, we develop F10-SGD, a fast optimizer for text classification and NER elastic-net linear models. On internal datasets, F10-SGD provides 4x reduction in training time compared to the OWL-QN optimizer without loss of accuracy or increase in model size. Furthermore, we incorporate biased sampling that prioritizes harder examples towards the end of the training. As a result, in addition to faster training, we were able to obtain statistically significant accuracy improvements for NER. On public datasets, F10-SGD obtains 22% faster training time compared to FastText for text classification. And, 4x reduction in training time compared to CRFSuite OWL-QN for NER.
Active Learning for New Domains in Natural Language Understanding
Oct 03, 2018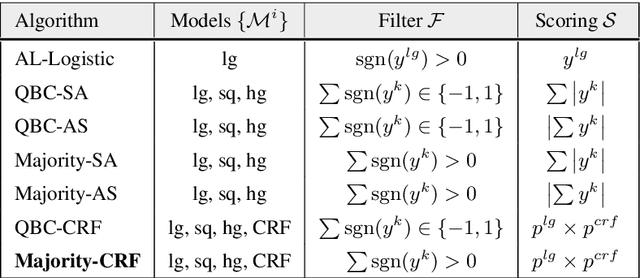
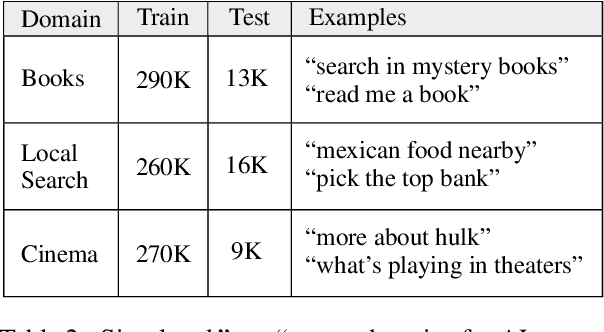
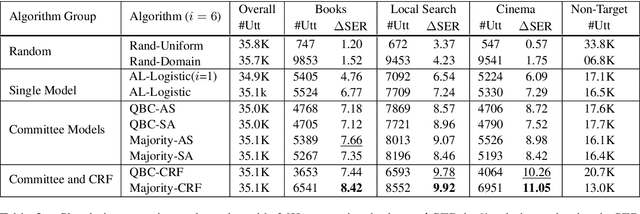
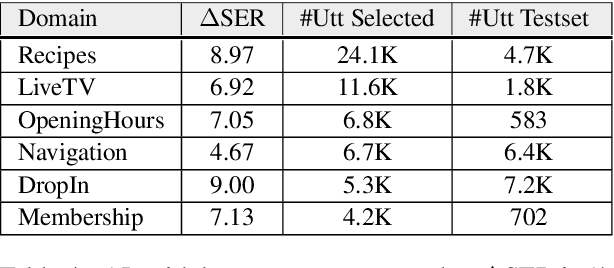
We explore active learning (AL) utterance selection for improving the accuracy of new underrepresented domains in a natural language understanding (NLU) system. Moreover, we propose an AL algorithm called Majority-CRF that uses an ensemble of classification and sequence labeling models to guide utterance selection for annotation. Experiments with three domains show that Majority-CRF achieves 6.6%-9% relative error rate reduction compared to random sampling with the same annotation budget, and statistically significant improvements compared to other AL approaches. Additionally, case studies with human-in-the-loop AL on six new domains show 4.6%-9% improvement on an existing NLU system.
Statistical Model Compression for Small-Footprint Natural Language Understanding
Jul 19, 2018
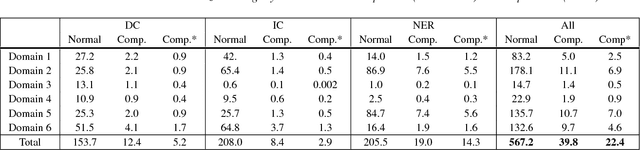
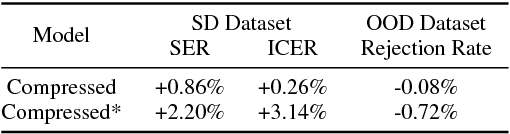

In this paper we investigate statistical model compression applied to natural language understanding (NLU) models. Small-footprint NLU models are important for enabling offline systems on hardware restricted devices, and for decreasing on-demand model loading latency in cloud-based systems. To compress NLU models, we present two main techniques, parameter quantization and perfect feature hashing. These techniques are complementary to existing model pruning strategies such as L1 regularization. We performed experiments on a large scale NLU system. The results show that our approach achieves 14-fold reduction in memory usage compared to the original models with minimal predictive performance impact.
Just ASK: Building an Architecture for Extensible Self-Service Spoken Language Understanding
Mar 02, 2018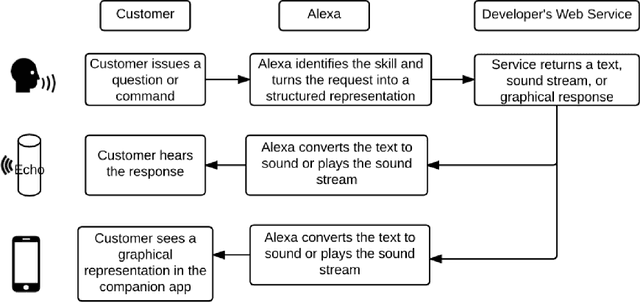
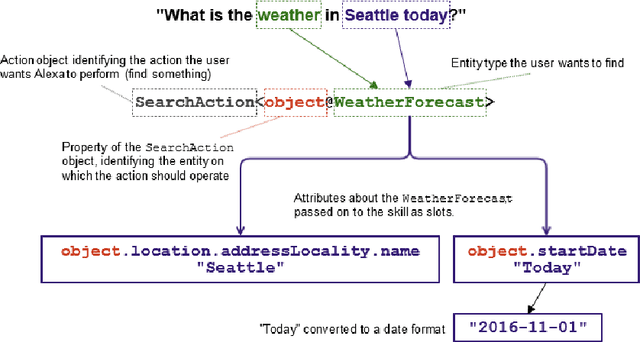
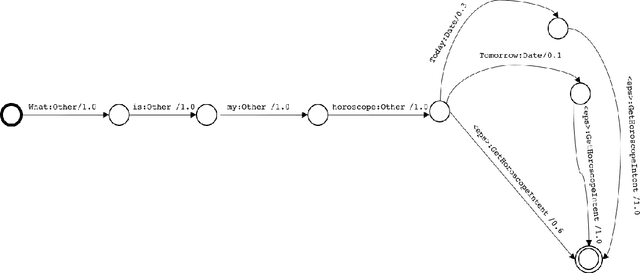
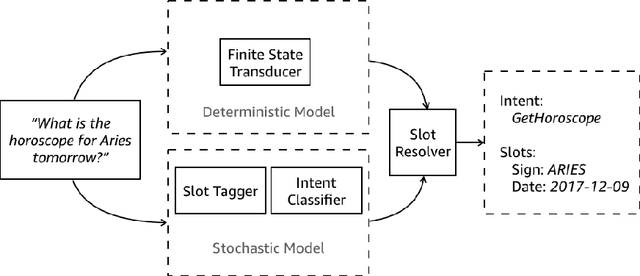
This paper presents the design of the machine learning architecture that underlies the Alexa Skills Kit (ASK) a large scale Spoken Language Understanding (SLU) Software Development Kit (SDK) that enables developers to extend the capabilities of Amazon's virtual assistant, Alexa. At Amazon, the infrastructure powers over 25,000 skills deployed through the ASK, as well as AWS's Amazon Lex SLU Service. The ASK emphasizes flexibility, predictability and a rapid iteration cycle for third party developers. It imposes inductive biases that allow it to learn robust SLU models from extremely small and sparse datasets and, in doing so, removes significant barriers to entry for software developers and dialogue systems researchers.